上一部分 介绍了硬间隔和软间隔支持向量机,本部分介绍非线性支持向量机(核方法)和序列最小最优化算法。
核方法
核方法主要针对非线性可分问题,给定数据集 T = {(x1, y1), ..., (xn, yn)} 其中 xi ∈ R^n,对应的标记为 yi= {-1, +1},如果能用 R^n 中一个超曲面将正负例正确分开,则称该问题为非线性可分问题。
用通俗的话来说,非线性可分问题就是有非常多的错误(而不是软间隔的一点点错误),完全无法线性可分的问题。
对于这类问题有两种思路:
感知机 PLA:大于一层隐层 + 非线性变换可以拟合任意曲线。
非线性可分,经过一个非线性转换将原空间的数据映射到新空间,变为线性可分(高维比低维更易线性可分)。核技巧属于这样的方法。
核函数与核技巧
频率派的优化问题最后都可以使用拉格朗日转为对偶问题进行求解,而对偶问题中有一项是 x 的内积:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( x i ⋅ x j ) − ∑ i = 1 N α i s . t . ∑ i = 1 N α i y i = 0 , α i ≥ 0 , i = 1 , 2 , . . . , N \min_\alpha \quad \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i\alpha_j y_iy_j (x_i · x_j) - \sum_{i=1}^N\alpha_i \quad \\
s.t.\quad \sum_{i=1}^N \alpha_iy_i = 0 ,\quad \alpha_i \ge 0, \quad i = 1, 2, ..., N
α min 2 1 i = 1 ∑ N j = 1 ∑ N α i α j y i y j ( x i ⋅ x j ) − i = 1 ∑ N α i s . t . i = 1 ∑ N α i y i = 0 , α i ≥ 0 , i = 1 , 2 , ... , N
那么对于非线性问题,上式的内积就变成了非线性转换的内积:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j ( ϕ ( x i ) ⋅ ϕ ( x j ) ) − ∑ i = 1 N α i \min_\alpha \quad \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i\alpha_j y_iy_j (\phi(x_i) · \phi(x_j)) - \sum_{i=1}^N\alpha_i
α min 2 1 i = 1 ∑ N j = 1 ∑ N α i α j y i y j ( ϕ ( x i ) ⋅ ϕ ( x j )) − i = 1 ∑ N α i
实际问题中,φ(x) 有时候可能维度很高,导致很难求解(更不用说还要求解内积)。是否有种方法能够不求解 φ 而直接获得内积呢(因为我们实际上并不关心 φ 是什么,而只关心它的内积)?核函数就是这样的方法:
∀ x , x ′ ∈ χ , ∃ ϕ : χ → Z s . t . K ( x , x ′ ) = ϕ ( x ) ⋅ ϕ ( x ′ ) \forall x,x' \in \chi, \exists \phi: \chi \rightarrow \Z \\
s.t. \quad K(x, x') = \phi(x) \cdot \phi(x')
∀ x , x ′ ∈ χ , ∃ ϕ : χ → Z s . t . K ( x , x ′ ) = ϕ ( x ) ⋅ ϕ ( x ′ )
则称 K 是一个核函数。
此时,假设我们已经找到一个 K,那么可以直接使用 K 得到 φ 的内积,这种取巧的方法称为核技巧。
使用了核方法的 SVM 则称为核 SVM,其基本模型不变(硬间隔或软间隔),只是将其中的内积变为核函数即可求解。
正定核
使用核技巧的一个很重要的问题就是:能否直接判断一个给定的函数 K 是不是核函数,或者说 K 满足什么条件才能成为核函数 。通常所说的核函数就是正定核函数。
正定核函数的充要条件(另一个定义)为:
k : χ × χ → R ∀ x , z ∈ χ h a s K ( x , z ) k: \chi \times \chi \rightarrow \R \\
\forall x,z \in \chi \quad {has} \quad K(x,z)
k : χ × χ → R ∀ x , z ∈ χ ha s K ( x , z )
k 为对称函数。如果 K 满足以下性质:
对称性:K(x,z) = K(z,x)
正定性:任取 N 个元素,x, x2, ..., xn ∈ X,对应的 Gram 矩阵是半正定的
那么称 K(x,z) 为正定核函数。
回到本节开始的问题,其实就是要证明:
K ( x , z ) = < ϕ ( x ) , ϕ ( z ) > ⇔ G r a m M a t r i x i s p o s i t i v e s e m i d e f i n i t e d K(x,z) = <\phi(x), \phi(z)> \Leftrightarrow {Gram Matrix\ is\ positive\ semidefinited}
K ( x , z ) =< ϕ ( x ) , ϕ ( z ) >⇔ G r am M a t r i x i s p os i t i v e se mi d e f ini t e d
必要性证明 :
已知 K(x,z) = <φ(x), φ(z)>,证 Gram 矩阵半正定,且 K 对称。
根据内积的对称性可知 K 满足对称性。
要证明正定性,只需要证:存在 α ∈ R^n,α^T · K · α ≥ 0。
α T ⋅ K ⋅ α = ( α 1 , α 2 , . . . α n ) ( K 11 K 12 . . . K 1 n K 21 K 21 . . . K 21 . . . . . . . . . . . . K n 1 K n 2 . . . K n n ) ( α 1 α 2 . . . α n ) = ∑ i = 1 N ∑ j = 1 N α i α j K i j = ∑ i = 1 N ∑ j = 1 N α i α j < ϕ ( x i ) , ϕ ( x j ) > = ∑ i = 1 N ∑ j = 1 N α i α j ϕ ( x i ) T ϕ ( x j ) = [ ∑ i = 1 N α i ϕ ( x i ) ] T ⋅ ∑ j = 1 N α j ϕ ( j ) = < ∑ i = 1 N α i ϕ ( x i ) , ∑ j − 1 N α j ϕ ( x j ) > = ∣ ∣ ∑ i = 1 N α i ϕ ( x i ) ∣ ∣ 2 ≥ 0 \alpha^T \cdot K \cdot \alpha = \left( \alpha_1,\alpha_2, ...\alpha_n \right)
\begin{pmatrix}
K_{11} & K_{12} & ... & K_{1n}\\
K_{21} & K_{21} & ... & K_{21}\\
... & ... & ... & ... &\\
K_{n1} & K_{n2} & ... & K_{nn}
\end{pmatrix}
\begin{pmatrix}
\alpha_1\\
\alpha_2\\
...\\
\alpha_n
\end{pmatrix} \\
= \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j K_{ij} \\
= \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j <\phi(x_i), \phi(x_j)> \\
= \sum_{i=1}^N \sum_{j=1}^N \alpha_i \alpha_j \phi(x_i)^T \phi(x_j) \\
= \left[\sum_{i=1}^N \alpha_i \phi(x_i) \right]^T \cdot \sum_{j=1}^N \alpha_j \phi(j) \\
= <\sum_{i=1}^N \alpha_i \phi(x_i), \sum_{j-1}^N \alpha_j \phi(x_j)> \\
= ||\sum_{i=1}^N \alpha_i \phi(x_i)||^2 \\
\ge 0
α T ⋅ K ⋅ α = ( α 1 , α 2 , ... α n ) K 11 K 21 ... K n 1 K 12 K 21 ... K n 2 ... ... ... ... K 1 n K 21 ... K nn α 1 α 2 ... α n = i = 1 ∑ N j = 1 ∑ N α i α j K ij = i = 1 ∑ N j = 1 ∑ N α i α j < ϕ ( x i ) , ϕ ( x j ) > = i = 1 ∑ N j = 1 ∑ N α i α j ϕ ( x i ) T ϕ ( x j ) = [ i = 1 ∑ N α i ϕ ( x i ) ] T ⋅ j = 1 ∑ N α j ϕ ( j ) =< i = 1 ∑ N α i ϕ ( x i ) , j − 1 ∑ N α j ϕ ( x j ) > = ∣∣ i = 1 ∑ N α i ϕ ( x i ) ∣ ∣ 2 ≥ 0
所以 K 是半正定的。
充分性证明 :
已知 K 对称且 Gram 矩阵半正定,证 K(x,z) = <φ(x), φ(z)>。以下内容来自李航老师《统计机器学习》。
定义映射:
ϕ : x → K ( ⋅ , x ) \phi: x \rightarrow K(\cdot, x)
ϕ : x → K ( ⋅ , x )
定义线性组合:
f ( ⋅ ) = ∑ i = 1 m α i K ( ⋅ , x i ) x i ∈ χ , α i ∈ R , i = 1 , 2 , . . . , m f(\cdot) = \sum_{i=1}^m \alpha_i K(\cdot, x_i) \\
x_i \in \chi, \alpha_i \in \mathrm {R} , i=1,2,...,m
f ( ⋅ ) = i = 1 ∑ m α i K ( ⋅ , x i ) x i ∈ χ , α i ∈ R , i = 1 , 2 , ... , m
由 f 组成的集合 S,由于 S 对加法和数乘封闭,所以 S 构成一个向量空间。
在集合 S 上定义点乘运算:
f ⋅ g = ∑ i = 1 m ∑ j = 1 l α i β j K ( x i , z j ) f \cdot g = \sum_{i=1}^m \sum_{j=1}^l \alpha_i \beta_j K(x_i, z_j)
f ⋅ g = i = 1 ∑ m j = 1 ∑ l α i β j K ( x i , z j )
证明过程可以参考李航老师《统计机器学习方法》,不再赘述。由此可得:
K ( ⋅ , x ) ⋅ f = ∑ i = 1 m α i K ( x , x i ) = f ( x ) K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z ) K(\cdot, x) \cdot f = \sum_{i=1}^m \alpha_i K(x, x_i) = f(x) \\
K(\cdot, x) \cdot K(\cdot, z) = K(x, z)
K ( ⋅ , x ) ⋅ f = i = 1 ∑ m α i K ( x , x i ) = f ( x ) K ( ⋅ , x ) ⋅ K ( ⋅ , z ) = K ( x , z )
此时 S 为再生核希尔伯特空间,因为核 K 具有再生性(满足上面两个条件)。
因此,给定对称函数 K,K 关于 x 的 Gram 矩阵是半正定的,可对 K 构造从 X 到希尔伯特空间 H 的映射:
ϕ : x → K ( ⋅ , x ) \phi: x \rightarrow K(\cdot, x)
ϕ : x → K ( ⋅ , x )
再根据第二个条件可得:
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z ) K(x,z) = \phi(x) \cdot \phi(z)
K ( x , z ) = ϕ ( x ) ⋅ ϕ ( z )
这个证明感觉不是特别理解,然后又看到有用矩阵分解证明的方法:
因为 K 对称,所以
K = V Λ V T l e t ϕ ( x i ) = [ λ 1 V 1 ( i ) , . . . , λ m V m ( i ) ] < ϕ ( x i ) , ϕ ( x j ) > = ∑ t = 1 m λ t v t ( i ) v t ( j ) = ( V Λ V t ) i j = K i j = k ( x i , x j ) K = V \Lambda V^T \\
let\ \phi(x_i) = [\sqrt{\lambda_1} V_1^{(i)}, ..., \sqrt{\lambda_m} V_m^{(i)}] \\
<\phi(x_i), \phi(x_j)> = \sum_{t=1}^m \lambda_t v_t^{(i)}v_t^{(j)} \\
= (V \Lambda V^t)_{ij} = K_{ij} = k(x_i, x_j)
K = V Λ V T l e t ϕ ( x i ) = [ λ 1 V 1 ( i ) , ... , λ m V m ( i ) ] < ϕ ( x i ) , ϕ ( x j ) >= t = 1 ∑ m λ t v t ( i ) v t ( j ) = ( V Λ V t ) ij = K ij = k ( x i , x j )
其中 V 是由特征向量组成的正交矩阵,Λ 是特征值组成的对角矩阵。
不过这块整体有点迷,没有弄得特别清晰,后来看到一个 MIT 的 Lecture Notes 觉得比较清楚,推荐阅读。
【希尔伯特空间】:完备的、可能是无限维的、被赋予内积的线性空间。
线性空间:向量空间(满足加法和数乘)
完备:可理解为对极限操作封闭(存在极限且极限也属于 Hilbert 空间)
内积,满足三个特征:
对称性:<f, g> = <g, f>, f,g ∈ H
正定性:<f, f> ≥ 0, "=" <=> f=0
线性:<r1f1 + r2f2, g> = r1<f, g> + r2<f2, g>
常用核函数
多项式核函数 :
K ( x , z ) = ( x ⋅ z + 1 ) p K(x, z) = (x \cdot z + 1)^p
K ( x , z ) = ( x ⋅ z + 1 ) p
对应的支持向量机是一个 p 次多项式分类器。
高斯核函数 :
K ( x , z ) = exp ( − ∣ ∣ x − z ∣ ∣ 2 2 σ 2 ) K(x,z) = \exp \left( -\frac{||x - z||^2}{2 \sigma^2 } \right)
K ( x , z ) = exp ( − 2 σ 2 ∣∣ x − z ∣ ∣ 2 )
对应的支持向量机是高斯径向基函数分类器。
字符串核函数 :
定义在离散集合上的核函数。字符串核是定义在字符串集合上的核函数。
考虑有限字符集 Σ,字符串 s 是从 Σ 中取出的有限个字符序列,s 的长度为 |s|,元素记为 s(1)s(2)…s(|s|)。所有长度为 n 的字符串集合记为 Σ^n,所有字符串的集合记为:
Σ ∗ = ⋃ n = 0 ∞ Σ n \Sigma^* = \bigcup_{n=0}^{\infty} \Sigma^n
Σ ∗ = n = 0 ⋃ ∞ Σ n
假设 S 是长度大于或等于 n 的字符串集合,s ∈ S,字符串集合 S 到特征空间 $$H_n = R^{\Sigma^n}$$ 的映射为 φn(s)。$$R^{\Sigma^n}$$ 表示定义在 Σ^n 上的实数空间,其每一维对应一个字符串 u ∈ Σ^n,映射 φn(s) 将字符串 s 对应于空间 R 的一个向量,在 u 维上的取值为:
[ ϕ n ( s ) ] u = ∑ i : s ( i ) = u λ l ( i ) [\phi_n(s)]_u = \sum_{i: s(i) = u} \lambda^{l(i)}
[ ϕ n ( s ) ] u = i : s ( i ) = u ∑ λ l ( i )
其中,0 ≤ λ ≤ 1 是一个衰减参数,l(i) 表示字符串 i 的长度,求和在 s 中所有与 u 相同的子串上 进行。
两个字符串 s 和 t 上的字符串核函数是基于映射 φn 的特种空间中的内积:
k n ( s , t ) = ∑ u ∈ Σ n [ ϕ n ( s ) ] u [ ϕ n ( t ) ] u = ∑ u ∈ Σ n ∑ ( i , j ) : s ( i ) = t ( j ) = u λ l ( i ) λ l ( j ) k_n(s,t) = \sum_{u \in \Sigma^n} [\phi_n(s)]_u [\phi_n(t)]_u \\
= \sum_{u \in \Sigma^n} \sum_{(i,j): s(i) = t(j) = u} \lambda^{l(i)} \lambda^{l(j)}
k n ( s , t ) = u ∈ Σ n ∑ [ ϕ n ( s ) ] u [ ϕ n ( t ) ] u = u ∈ Σ n ∑ ( i , j ) : s ( i ) = t ( j ) = u ∑ λ l ( i ) λ l ( j )
上式给出了字符串 s 和 t 中长度等于 n 的所有子串组成的特征向量的余弦相似度。相同的子串越多,s 和 t 越相似。
算法
输入:数据集 T = {(x1,y1), (x2, y2), ..., (xn, yn)} ,其中 xi ∈ R^n, yi ∈ {+1, -1} , i=1,2,...,N
输出:分类决策函数
利用对偶问题求解算法如下:
选择适当的核函数 K 和 惩罚参数 C,构造并求解最优化问题:
min α 1 2 ∑ i = 1 N ∑ j = 1 N α i α j y i y j K ( x i , x j ) − ∑ i = 1 N α i ( 1 ) s . t . ∑ i = 1 N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N \min_\alpha \quad \frac{1}{2} \sum_{i=1}^N \sum_{j=1}^N \alpha_i\alpha_j y_iy_j K(x_i, x_j) - \sum_{i=1}^N\alpha_i \quad (1) \\
s.t.\quad \sum_{i=1}^N \alpha_iy_i = 0 \\
\quad 0 \le\alpha_i \le C, \quad i = 1, 2, ..., N
α min 2 1 i = 1 ∑ N j = 1 ∑ N α i α j y i y j K ( x i , x j ) − i = 1 ∑ N α i ( 1 ) s . t . i = 1 ∑ N α i y i = 0 0 ≤ α i ≤ C , i = 1 , 2 , ... , N
得到最优解 α* = (α1*, α2*, ..., αN*)^T
根据 KKT 计算 w*,并选择 α* 的一个分量 0 < αj* < C 计算 b*:
b ∗ = y j − ∑ i = 1 N α ∗ y i K ( x i , x j ) b^* = y_j - \sum_{i=1}^{N} \alpha^* y_i K(x_i, x_j)
b ∗ = y j − i = 1 ∑ N α ∗ y i K ( x i , x j )
构造决策函数:
f ( x ) = s i g n ( ∑ i = 1 N α i ∗ y i K ( x i , x ) + b ∗ ) f(x) = {sign} \left( \sum_{i=1}^{N} \alpha_i^* y_i K(x_i, x) + b^* \right)
f ( x ) = s i g n ( i = 1 ∑ N α i ∗ y i K ( x i , x ) + b ∗ )
SMO
SMO(Sequential minimal optimization)是一种启发式算法,主要用于解决训练样本很大时,高效地实现支持向量机的学习问题,具体看就是要解决式(1)的凸二次规划对偶问题。
在正式开始之前需要介绍一种优化方法: Coordinate Ascent,假设我们要解决如下优化问题:
min α W ( α 1 , α 2 , . . . , α n ) \min_{\alpha} W(\alpha_1, \alpha_2, ..., \alpha_n)
α min W ( α 1 , α 2 , ... , α n )
Coordinate ascent 的解决思路如下:
1 2 3 4 5 Loop until convergence: { For i = 1 ,...,n { α_i := arg min_α W(α1 , α2 , ..., αn) } }
在内循环中,固定住除了 ai 的所有元素,通过调整参数 ai 重新优化 W,优化完每个 a 后就能得到最终的最优解。
SMO 的基本思路如下:
如果所有变量的解都满足 KKT 条件,那么这个解就是问题的最优解(KKT 是该最优化问题的充要条件)。
否则选择两个变量,固定其他变量,针对这两个变量构建一个二次规划问题。
这里第二步用到的就是 Coordinate Ascent,不过需要注意的是,因为有(1)式的约束条件,所以如果只留一个自由变量而固定住其他变量其实等于固定了所有变量。这里选择两个变量其实也只有一个是自由变量。比如假设 α1 和 α2 为两个变量,α3, α4, …, αn 固定,根据约束条件可得:
α 1 = − y 1 ∑ i = 2 N α i y i \alpha_1 = -y_1 \sum_{i=2}^{N} \alpha_i y_i
α 1 = − y 1 i = 2 ∑ N α i y i
如果 α2 确定,α1 自然也就确定了。
这样就将原始的优化问题变成一个个子问题,因为二次规划问题也是求极小,所以子问题的解应该能更接近原始问题的解。而且子问题可以通过解析法直接求得,这就提高了速度。
SMO 包括两个部分:求解两个变量二次规划的解析方法和选择变量的启发式方法。
两个变量二次规划求解
假设选择的变量为:α1 和 α2,其他变量固定,原始的优化问题(1)可以写为:
min α 1 , α 2 W ( α 1 , α 2 ) = 1 2 K 11 α 1 2 + 1 2 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 − ∑ i = 3 N α i ( 2 ) s . t . α 1 y 1 + α 2 y 2 = − ∑ i = 3 N y i α i = ζ 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N \min_{\alpha_1, \alpha_2} W(\alpha_1, \alpha_2) = \frac{1}{2}K_{11}\alpha_{1}^{2} + \frac{1}{2}K_{22}\alpha_{2}^{2} + y_1y_2K_{12}\alpha_1\alpha_2 - (\alpha_1 + \alpha_2) + y_1\alpha_1\sum_{i=3}^{N} y_i\alpha_iK_{i1}+ y_2\alpha_2\sum_{i=3}^{N} y_i\alpha_iK_{i2} - \sum_{i=3}^{N} \alpha_i \quad (2)\\
s.t. \quad \alpha_1y_1 + \alpha_2y_2 = - \sum_{i=3}^{N} y_i\alpha_i = \zeta \\
\quad 0 \le\alpha_i \le C, \quad i = 1, 2, ..., N
α 1 , α 2 min W ( α 1 , α 2 ) = 2 1 K 11 α 1 2 + 2 1 K 22 α 2 2 + y 1 y 2 K 12 α 1 α 2 − ( α 1 + α 2 ) + y 1 α 1 i = 3 ∑ N y i α i K i 1 + y 2 α 2 i = 3 ∑ N y i α i K i 2 − i = 3 ∑ N α i ( 2 ) s . t . α 1 y 1 + α 2 y 2 = − i = 3 ∑ N y i α i = ζ 0 ≤ α i ≤ C , i = 1 , 2 , ... , N
该问题即为有约束的二次规划问题,可以求得极值。
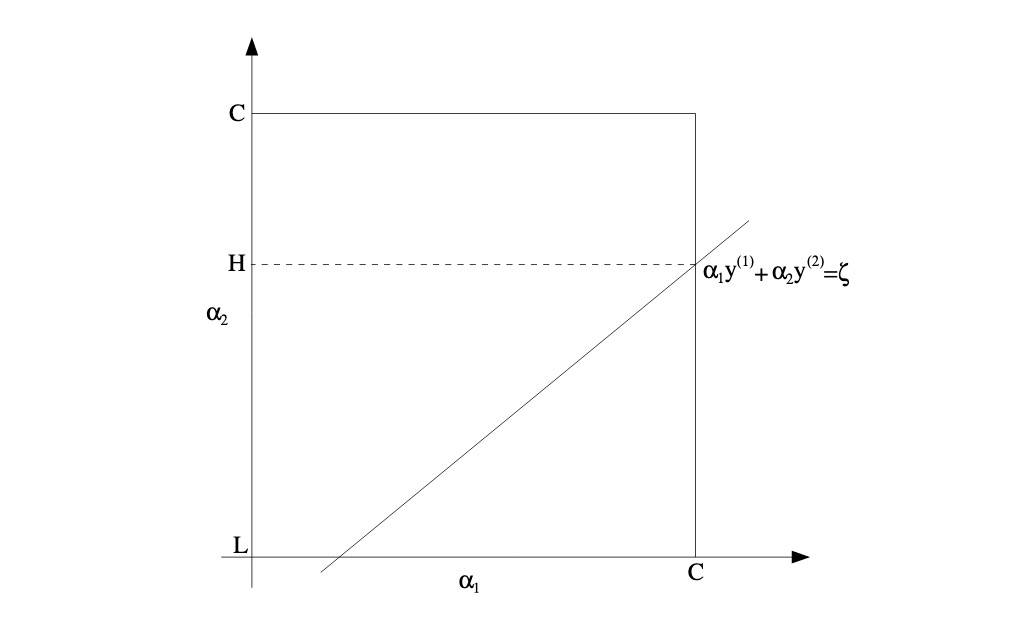
根据约束条件可知, α1 和 α2 一定在下面这个正方形区域中:
图片来自 Stanford CS229(第二个参考文献)
同时,α1 也可以表示为:
α 1 = ( ζ − α 2 y 2 ) y 1 \alpha_{1}=\left(\zeta-\alpha_{2} y_{2}\right) y_{1}
α 1 = ( ζ − α 2 y 2 ) y 1
于是,目标函数可以写为:
min α 2 W ( α 2 ) = 1 2 K 11 ( ζ − α 2 y 2 ) 2 + 1 2 K 22 α 2 2 + y 2 K 12 α 2 ( ζ − α 2 y 2 ) − ( ( ζ − α 2 y 2 ) y 1 + α 2 ) + ( ζ − α 2 y 2 ) ∑ i = 3 N y i α i K i 1 + y 2 α 2 ∑ i = 3 N y i α i K i 2 − ∑ i = 3 N α i ( 3 ) s . t . L ≤ α 2 ≤ H \min_{\alpha_2} W(\alpha_2) = \frac{1}{2}K_{11}(\zeta-\alpha_{2} y_{2})^{2} + \frac{1}{2}K_{22}\alpha_{2}^{2} + y_2K_{12}\alpha_2(\zeta-\alpha_{2} y_{2}) - ((\zeta-\alpha_{2} y_{2})y_1 + \alpha_2) + \\
(\zeta-\alpha_{2} y_{2})\sum_{i=3}^{N} y_i\alpha_iK_{i1}+ y_2\alpha_2\sum_{i=3}^{N} y_i\alpha_iK_{i2} - \sum_{i=3}^{N} \alpha_i \quad (3)\\
s.t. \quad L \le\alpha_2 \le H
α 2 min W ( α 2 ) = 2 1 K 11 ( ζ − α 2 y 2 ) 2 + 2 1 K 22 α 2 2 + y 2 K 12 α 2 ( ζ − α 2 y 2 ) − (( ζ − α 2 y 2 ) y 1 + α 2 ) + ( ζ − α 2 y 2 ) i = 3 ∑ N y i α i K i 1 + y 2 α 2 i = 3 ∑ N y i α i K i 2 − i = 3 ∑ N α i ( 3 ) s . t . L ≤ α 2 ≤ H
假设式(2)的初始可行解为 $$\alpha_1^{old}, \alpha_2^{old}$$,最优解为 $$\alpha_1^{new}, \alpha_2^{new}$$,沿着约束方向未剪辑时 α2 的最优解为 $$\alpha_2^{new, unclipped}$$,那么:
L = max ( 0 , α 2 o l d − α 1 o l d ) H = min ( C , C + α 2 o l d − α 1 o l d ) s . t . y 1 ≠ y 2 L = max ( 0 , α 2 o l d + α 1 o l d − C ) H = min ( C , α 2 o l d + α 1 o l d ) s . t . y 1 = y 2 L = \max(0, \alpha_2^{old} - \alpha_1^{old}) \\
H = \min(C, C + \alpha_2^{old} - \alpha_1^{old}) \\
s.t. \quad \ y_1 \neq y_2
\\
L = \max(0, \alpha_2^{old} + \alpha_1^{old} - C) \\
H = \min(C, \alpha_2^{old} + \alpha_1^{old}) \\
s.t. \quad \ y_1 = y_2
L = max ( 0 , α 2 o l d − α 1 o l d ) H = min ( C , C + α 2 o l d − α 1 o l d ) s . t . y 1 = y 2 L = max ( 0 , α 2 o l d + α 1 o l d − C ) H = min ( C , α 2 o l d + α 1 o l d ) s . t . y 1 = y 2
为了记录方便,记:
g ( x ) = ∑ i = 1 N α i y i K ( x i , x ) + b E i = g ( x i ) − y i v i = ∑ j = 3 N α j y j K ( x j , x i ) = g ( x i ) − ∑ j = 1 2 α j y j K ( x j , x i ) − b g(x) = \sum_{i=1}^{N} \alpha_i y_i K(x_i, x) + b \\
E_i = g(x_i) - y_i \\
v_i = \sum_{j=3}^{N} \alpha_j y_j K(x_j, x_i) = g(x_i) - \sum_{j=1}^{2} \alpha_j y_j K(x_j, x_i) - b
g ( x ) = i = 1 ∑ N α i y i K ( x i , x ) + b E i = g ( x i ) − y i v i = j = 3 ∑ N α j y j K ( x j , x i ) = g ( x i ) − j = 1 ∑ 2 α j y j K ( x j , x i ) − b
于是目标函数可以表示为:
min α 2 W ( α 2 ) = 1 2 K 11 ( ζ − α 2 y 2 ) 2 + 1 2 K 22 α 2 2 + y 2 K 12 α 2 ( ζ − α 2 y 2 ) − ( ( ζ − α 2 y 2 ) y 1 + α 2 ) + ( ζ − α 2 y 2 ) v 1 + y 2 α 2 v 2 − ∑ i = 3 N α i ( 4 ) s . t . L ≤ α 2 ≤ H \min_{\alpha_2} W(\alpha_2) = \frac{1}{2}K_{11}(\zeta-\alpha_{2} y_{2})^{2} + \frac{1}{2}K_{22}\alpha_{2}^{2} + y_2K_{12}\alpha_2(\zeta-\alpha_{2} y_{2}) - ((\zeta-\alpha_{2} y_{2})y_1 + \alpha_2) + \\
(\zeta-\alpha_{2} y_{2})v_1+ y_2 \alpha_2 v_2- \sum_{i=3}^{N} \alpha_i \quad (4)\\
s.t. \quad L \le\alpha_2 \le H
α 2 min W ( α 2 ) = 2 1 K 11 ( ζ − α 2 y 2 ) 2 + 2 1 K 22 α 2 2 + y 2 K 12 α 2 ( ζ − α 2 y 2 ) − (( ζ − α 2 y 2 ) y 1 + α 2 ) + ( ζ − α 2 y 2 ) v 1 + y 2 α 2 v 2 − i = 3 ∑ N α i ( 4 ) s . t . L ≤ α 2 ≤ H
对 α2 求导并令其等于 0:
( K 11 + K 22 − 2 K 12 ) α 2 = y 2 ( y 2 − y 1 + ζ K 11 − ζ K 12 + v 1 − v 2 ) (K_{11} + K_{22} - 2K_{12})\alpha_2 = y_2(y_2 - y_1 + \zeta K_{11} - \zeta K_{12} + v_1 - v_2)
( K 11 + K 22 − 2 K 12 ) α 2 = y 2 ( y 2 − y 1 + ζ K 11 − ζ K 12 + v 1 − v 2 )
将 $$\zeta = \alpha_1^{old} y_1 + \alpha_2^{old} y_2$$ 以及 v 代入得:
( K 11 + K 22 − 2 K 12 ) α 2 n e w , u n c l i p p e d = y 2 ( ( K 11 + K 22 − 2 K 12 ) α 2 o l d y 2 + y 2 − y 1 + g ( x 1 ) − g ( x 2 ) ) = ( K 11 + K 22 − 2 K 12 ) α 2 o l d + y 2 ( E 1 − E 2 ) (K_{11} + K_{22} - 2K_{12}) \alpha_2^{new, unclipped} \\
= y_2((K_{11} + K_{22} - 2K_{12}) \alpha_2^{old} y_2 + y_2 - y_1 + g(x_1) - g(x_2)) \\
= (K_{11} + K_{22} - 2K_{12}) \alpha_2^{old} + y_2(E_1 - E_2)
( K 11 + K 22 − 2 K 12 ) α 2 n e w , u n c l i pp e d = y 2 (( K 11 + K 22 − 2 K 12 ) α 2 o l d y 2 + y 2 − y 1 + g ( x 1 ) − g ( x 2 )) = ( K 11 + K 22 − 2 K 12 ) α 2 o l d + y 2 ( E 1 − E 2 )
于是得:
α 2 n e w , u n c l i p p e d = α 2 o l d + y 2 ( E 1 − E 2 ) K 11 + K 22 − 2 K 12 ( 5 ) \alpha_2^{new, unclipped} = \alpha_2^{old} + \frac{y_2(E_1 - E_2)}{K_{11} + K_{22} - 2K_{12}} \quad(5)
α 2 n e w , u n c l i pp e d = α 2 o l d + K 11 + K 22 − 2 K 12 y 2 ( E 1 − E 2 ) ( 5 )
其中:
K 11 + K 22 − 2 K 12 = ∣ ∣ ϕ ( x 1 ) − ϕ ( x 2 ) ∣ ∣ 2 K_{11} + K_{22} - 2K_{12} = || \phi(x_1) - \phi(x_2)||^2
K 11 + K 22 − 2 K 12 = ∣∣ ϕ ( x 1 ) − ϕ ( x 2 ) ∣ ∣ 2
φ 是输入空间到特征空间的映射。
进而可得:
α 2 n e w = { H if α 2 n e w , unclipped > H α 2 new,unclipped if L ≤ α 2 new , unclipped ≤ H L if α 2 new , unclipped < L α 1 n e w = α 1 o l d + y 1 y 2 ( α 2 o l d − α 2 n e w ) \alpha_{2}^{n e w}=\left\{\begin{array}{ll}
H & \text { if } \alpha_{2}^{n e w, \text {unclipped}}>H \\
\alpha_{2}^{\text {new,unclipped}} & \text {if } L \leq \alpha_{2}^{\text {new}, \text {unclipped}} \leq H \\
L & \text { if } \alpha_{2}^{\text {new}, \text {unclipped}}<L
\end{array}\right. \\
\alpha_1^{new} = \alpha_1^{old} + y_1 y_2 (\alpha_2^{old} - \alpha_2^{new})
α 2 n e w = ⎩ ⎨ ⎧ H α 2 new,unclipped L if α 2 n e w , unclipped > H if L ≤ α 2 new , unclipped ≤ H if α 2 new , unclipped < L α 1 n e w = α 1 o l d + y 1 y 2 ( α 2 o l d − α 2 n e w )
变量选择
每个子问题要选择两个变量,其中至少有一个不满足 KKT 条件(如果两个变量都满足 KKT 条件的话,最优解已经得到了)。
第一个变量的选择为外循环,选择违反 KKT 最严重的点。具体地,根据对偶互补条件:
α i = 0 ⇒ y i ( w ⋅ x i + b ) ≥ 1 α i = C ⇒ y i ( w ⋅ x i + b ) ≤ 1 0 < α i < C ⇒ y i ( w ⋅ x i + b ) = 1 \begin{aligned}
\alpha_{i}=0 & \Rightarrow y_{i}\left(w \cdot x_{i}+b\right) \geq 1 \\
\alpha_{i}=C & \Rightarrow y_{i}\left(w \cdot x_{i}+b\right) \leq 1 \\
0<\alpha_{i}<C & \Rightarrow y_{i}\left(w \cdot x_{i}+b\right)=1
\end{aligned}
α i = 0 α i = C 0 < α i < C ⇒ y i ( w ⋅ x i + b ) ≥ 1 ⇒ y i ( w ⋅ x i + b ) ≤ 1 ⇒ y i ( w ⋅ x i + b ) = 1
可得:
α i = 0 ⇔ y i ( ∑ j = 1 N α j y j K ( x j , x i ) + b ) ≥ 1 α i = C ⇔ y i ( ∑ j = 1 N α j y j K ( x j , x i ) + b ) ≤ 1 0 < α i < C ⇔ y i ( ∑ j = 1 N α j y j K ( x j , x i ) + b ) = 1 \begin{aligned}
\alpha_{i}=0 & \Leftrightarrow y_{i}\left(\sum_{j=1}^{N} \alpha_j y_j K(x_j, x_i) + b\right) \geq 1 \\
\alpha_{i}=C & \Leftrightarrow y_{i}\left(\sum_{j=1}^{N} \alpha_j y_j K(x_j, x_i)+b\right) \leq 1 \\
0<\alpha_{i}<C & \Leftrightarrow y_{i}\left(\sum_{j=1}^{N} \alpha_j y_j K(x_j, x_i)+b\right)=1
\end{aligned}
α i = 0 α i = C 0 < α i < C ⇔ y i ( j = 1 ∑ N α j y j K ( x j , x i ) + b ) ≥ 1 ⇔ y i ( j = 1 ∑ N α j y j K ( x j , x i ) + b ) ≤ 1 ⇔ y i ( j = 1 ∑ N α j y j K ( x j , x i ) + b ) = 1
然后检验样本点(xi, yi)是否满足上面的条件。
在检验过程中,外循环在首先遍历所有满足条件 0<αi<C 的样本点(间隔边界上的支持向量点),检验它们是否满足上述(KKT)条件。如果这些点都满足,则遍历整个数据集,检验它们是否满足。
第二个变量的选择为内循环,假设外循环已经找到了第一个变量 α1,现在要找第二个变量,选择的标准是希望 α2 有足够大的变化(有助于快速收敛)。因为 α1 已定,E1 也已定,根据式(5),要使 α2 最大,如果 E1>0,选择最小的 Ei 作为 E2,如果 E1<0,选择最大的 Ei 作为 E2。
如果按照上面方法找到的 α2 不能使目标函数有足够的下降,则采用启发式方法继续选择 α2:
遍历在间隔边界上的点,依次将其对应的变量作为 α2,直到目标函数有足够的下降
如果找不到合适的 α2,就遍历数据集
如果还是找不到就放弃第一个 α1,重新选择一个
每次完成两个变量的优化后都要重新计算 b,当 $$0 < \alpha_1^{new} < C$$ 时,由上面的条件可知:
∑ j = 1 N α j y j K ( x j , x 1 ) + b = y 1 \sum_{j=1}^{N} \alpha_j y_j K(x_j, x_1) + b = y_1
j = 1 ∑ N α j y j K ( x j , x 1 ) + b = y 1
于是:
b 1 n e w = y 1 − ∑ j = 3 N α j y j K j 1 − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21 b_1^{new} = y_1 - \sum_{j=3}^{N} \alpha_j y_j K_{j1} - \alpha_1^{new}y_1K_{11} - \alpha_2^{new}y_2K_{21}
b 1 n e w = y 1 − j = 3 ∑ N α j y j K j 1 − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21
再根据 E 的定义:
E 1 = ∑ j = 3 N α j y j K j 1 + α 1 o l d y 1 K 11 + α 2 o l d y 1 K 21 + b o l d − y 1 E_1 = \sum_{j=3}^{N} \alpha_j y_j K_{j1} + \alpha_1^{old} y_1 K_{11} + \alpha_2^{old} y_1 K_{21} + b^{old} - y_1
E 1 = j = 3 ∑ N α j y j K j 1 + α 1 o l d y 1 K 11 + α 2 o l d y 1 K 21 + b o l d − y 1
进而可得:
b 1 n e w = − E 1 + α 1 o l d y 1 K 11 + α 2 o l d y 1 K 21 + b o l d − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21 = − E 1 − y 1 K 11 ( α 1 n e w − α 1 o l d ) − y 2 K 21 ( α 2 n e w − α 2 o l d ) + b o l d b_1^{new} = -E_1 + \alpha_1^{old} y_1 K_{11} + \alpha_2^{old} y_1 K_{21} + b^{old} - \alpha_1^{new}y_1K_{11} - \alpha_2^{new}y_2K_{21} \\
= -E_1 - y_1K_{11} (\alpha_1^{new} - \alpha_1^{old}) - y_2K_{21} (\alpha_2^{new} - \alpha_2^{old})+ b^{old}
b 1 n e w = − E 1 + α 1 o l d y 1 K 11 + α 2 o l d y 1 K 21 + b o l d − α 1 n e w y 1 K 11 − α 2 n e w y 2 K 21 = − E 1 − y 1 K 11 ( α 1 n e w − α 1 o l d ) − y 2 K 21 ( α 2 n e w − α 2 o l d ) + b o l d
同理,如果 $$0 < \alpha_2^{new} < C$$ 可得:
b 2 n e w = − E 2 − y 1 K 12 ( α 1 n e w − α 1 o l d ) − y 2 K 22 ( α 2 n e w − α 2 o l d ) + b o l d b_2^{new} = -E_2 - y_1K_{12} (\alpha_1^{new} - \alpha_1^{old}) - y_2K_{22} (\alpha_2^{new} - \alpha_2^{old})+ b^{old}
b 2 n e w = − E 2 − y 1 K 12 ( α 1 n e w − α 1 o l d ) − y 2 K 22 ( α 2 n e w − α 2 o l d ) + b o l d
如果新的 α1 和 α2 都满足条件 0<α<C,那么新的 b1=b2;如果新的 α1 和 α2 是 0 或 C,新的 b1 和 b2 以及它们之间的数都是符合 KKT 条件的阈值,此时选择中点作为新 b。
完成两个变量的优化后,还需更新对应的 Ei 值:
E i n e w = ∑ S y j α j K ( x i , x j ) + b n e w − y i E_i^{new} = \sum_{S} y_j \alpha_jK(x_i, x_j) + b^{new} - y_i
E i n e w = S ∑ y j α j K ( x i , x j ) + b n e w − y i
其中 S 是所有支持向量 xj 的集合。
算法
输入:数据集 T = {(x1,y1), (x2, y2), ..., (xn, yn} ,其中 xi ∈ R^n, yi ∈ {+1, -1} , i=1,2,...,N,精度 ε
输出:近似解 α
步骤如下:
取初始值 α0 = 0,令 k = 0
选取优化变量 α 1 k , α 2 k \alpha_1^k, \alpha_2^k α 1 k , α 2 k α 1 k + 1 , α 2 k + 1 \alpha_1^{k+1}, \alpha_2^{k+1} α 1 k + 1 , α 2 k + 1 α k + 1 \alpha^{k+1} α k + 1
如果在精度 ε 内满足停机条件:
∑ i = 1 N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , . . . , N y i ⋅ g ( x i ) { ≥ 1 { x i ∣ α i = 0 } = 1 { x i ∣ 0 ≤ α i ≤ C } ≤ 1 { x i ∣ α i = C } s . t . g ( x i ) = ∑ j = 1 N α j y j K ( x j , x i ) + b \sum_{i=1}^N \alpha_i y_i = 0, \quad 0 \le \alpha_i \le C, \quad i = 1,2, ..., N \\
y_i \cdot g(x_i) \left\{\begin{matrix}
\ge 1 & \{x_i | \alpha_i = 0 \} \\
=1 & \{x_i | 0 \le \alpha_i \le C \} \\
\le 1 & \{x_i | \alpha_i = C \}
\end{matrix}\right. \\
s.t. \quad g(x_i) = \sum_{j=1}^{N} \alpha_j y_j K(x_j, x_i) + b
i = 1 ∑ N α i y i = 0 , 0 ≤ α i ≤ C , i = 1 , 2 , ... , N y i ⋅ g ( x i ) ⎩ ⎨ ⎧ ≥ 1 = 1 ≤ 1 { x i ∣ α i = 0 } { x i ∣0 ≤ α i ≤ C } { x i ∣ α i = C } s . t . g ( x i ) = j = 1 ∑ N α j y j K ( x j , x i ) + b
则转下一步,否则令 k=k+1,回到第二步
取近似解 $$ \hat{\alpha} = \alpha^{k+1}$$
实现
具体实现可以参考这里 ,本文主要梳理一下主要的流程。
首先是初始化参数,主要包括 α,b 和 E(也就是 error)
接下来就是初始化 α1,根据 SMO 算法,首先选择满足条件 0<αi<C 的样本点,即间隔边界上的支持向量点,检验它们是否满足 KKT 条件。如果这些点都满足,则遍历整个数据集,检验它们是否满足。
找到 α1 后,可以根据 E 的差距最大选择 α2,进而可以求得新的 α,b,E 和支持向量。如果 α2 不能使目标函数有足够的下降,则根据启发式规则重新选择 α2,即:
遍历在间隔边界上的点,依次作为 α2 直到目标函数有足够的下降
再不行就遍历数据集
还是不行就放弃第一个 α1,重新选择一个
直到计算完所有 α 或达到最大迭代次数为止。
参考资料