Paper:[1907.11692] RoBERTa: A Robustly Optimized BERT Pretraining Approach
Code:fairseq/examples/roberta at master · pytorch/fairseq
核心思想:
对 BERT 几个小点(主要是动态 Mask 和不使用 NSP)进行优化取得了比较好的实践结果。
What
动机和核心问题
预训练方法好是好,但很难确定到底哪些方面对模型贡献最大。所以本文在仔细评估 Bert 超参数和训练数据规模的影响后,发现 BERT 可以表现的更好,完全不亚于已发表的任何后 BERT 方法;而且也证明 MLM 作为训练目标也有足够的竞争力(如对比 PLM)。贡献如下:
- 提出一组重要的 BERT 设计选择和训练策略,并介绍了能够提高下游任务性能的替代方案。
- 使用了新的数据集(CCNews),并确认使用跟多数据能够提高下游任务性能。
- 训练效果的提升说明 MLM 方法在所有已发表的方法中极具竞争力。
模型和算法
模型同 BERT,主要说一下几个改动。
动态 Masking
BERT 是随机 Mask,而且是静态的,也就是每条训练数据在每个 Epoch 使用相同的 Mask。
本文采用动态 Mask,即每条训练数据被喂进模型时都生成新的 Mask。
最终效果嘛,稍好一点。fairseq 专门实现了一个 MaskTokensDataset,感觉还挺有意思的,看下是怎么 mask 的。还是看简化后的代码,为了便于观察,数据也伪造了一下。
1 | # 代码来自 fairseq 的 MaskTokensDataset |
最终的结果就是要实现的效果,mask 的大概是 15% 的 80%,在本例中也就是大约 24 个,随机替换的大概是 15% 的 10%,在本例中大约 3 个。
NSP
为了判断 NSP 到底有没有作用,本文做了几组对比实验:
- SEGMENT-PAIR+NSP:BERT 的配置,每个输入包含一对片段,每个片段可能包含多个语句。
- SENTENCE-PAIR+NSP:每个输入包含一对自然语句,它们是从一个文档的连续部分或从单独的文档中采样而来的。
- FULL-SENTENCES:每个输入来自一个或多个文档的连续输入,如果跨越文档,加一个分割标记,不使用 NSP。
- DOC-SENTENCES:同上,但不跨越文档。因为长度可能达不到 512,所以动态增加 batch size,让总的 Token 数量和 FULL-SENTENCES 接近。
最后的结论有三个:
- 单个句子有损性能(上面第二个设置)
- NSP 与性能关系不大
- 不跨越文档略好
Batch Size
大批能够提高 MLM 的 ppl 同时提升下游任务性能,而且更容易并行,训练步骤更少。
本文采用 8K batch size。
Encoding
BERT 使用了 char-level 的 BPE(30K),本文使用了 byte-level 的 BPE(50K),方法来自 GPT-2,该方法会增加参数量。
特点和创新
对 Bert 的改进:
- 更长训练时间、更大 batch、更多数据
- 去掉 NSP(下一句预测)
- 更长的序列
- 动态 Masking
How
如何构造数据并训练使用
除了 byte-level BPE,FULL-SENTENCES,动态 Mask 和不使用 NSP,其他与 BERT 一致。训练参数设置可以参见下面的【数据和实验】。
官方文档提供了一些开箱即用的使用方法,功能包括:提取序列特征、分类、Mask 填充(预测)、代词消歧等。
数据和实验
数据(160G)包括:BOOKCORPUS、CC-NEWS、OPENWEBTEXT 和 STORIES。
模型训练有几个调整(其他同 BERT):
- 最大的学习率和 warmup 步数每次分开单独调整
- Adam 的 β2 设置为 0.98
- 只训练全长(512)序列
- Batch Size 8K
BERT 原配置:
- Adam β1 = 0.9,ϵ = 1e-6,L2 权重衰减 0.01
- 学习率前 10000 步 warmed up to 峰值 1e-4,然后线性衰减
- 所有层和注意力权重都使用 Dropout 0.1
- GELU 激活函数
- 更新 1000000 步
- Batch Size 256
- MAX Length 512 Tokens
数据量和训练时长的影响
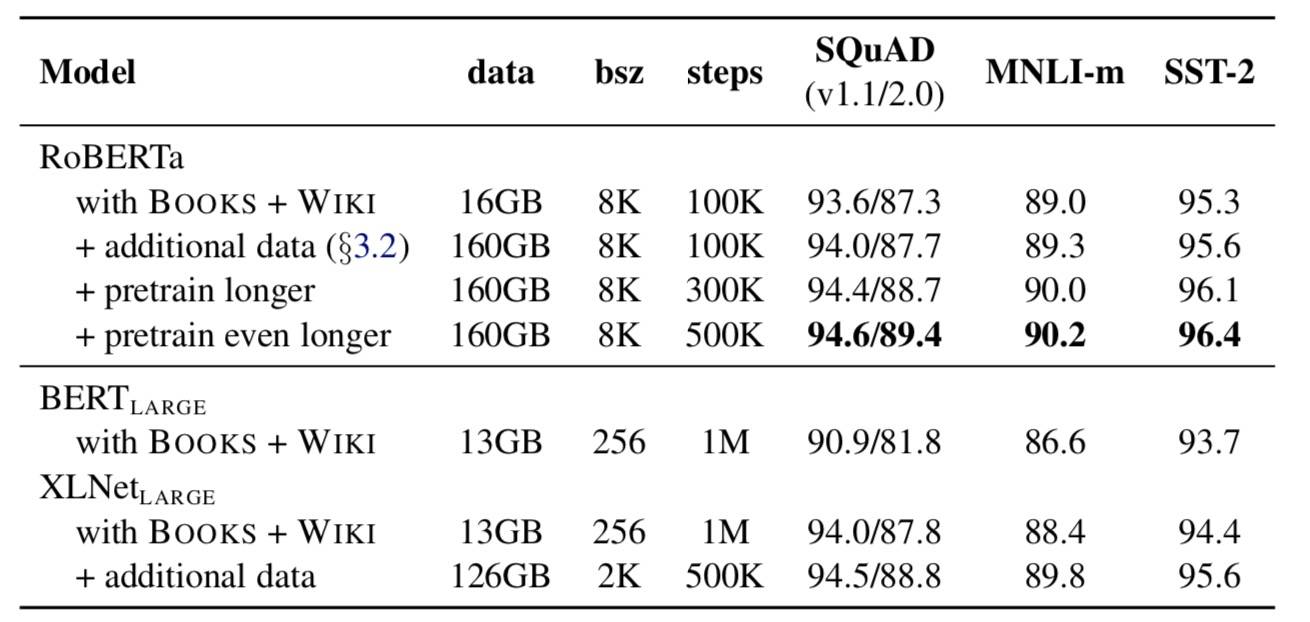
具体任务上的结果和精调的配置可以参见论文。
Discussion
相关工作
语言模型:
- Andrew M Dai and Quoc V Le. 2015. Semi-supervised sequence learning. In Advances in Neural Informa- tion Processing Systems (NIPS).
- ELMo: Matthew Peters, Mark Neumann, Mohit Iyyer, Matt Gardner, Christopher Clark, Kenton Lee, and Luke Zettlemoyer. 2018. Deep contextualized word representations. In North American Association for Com- putational Linguistics (NAACL).
- ULMFiT: Jeremy Howard and Sebastian Ruder. 2018. Universal language model fine-tuning for text classification. arXiv preprint arXiv:1801.06146.
翻译:
- Bryan McCann, James Bradbury, Caiming Xiong, and Richard Socher. 2017. Learned in translation: Con- textualized word vectors. In Advances in Neural Information Processing Systems (NIPS), pages 6297– 6308.
MLM:
- BERT: Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2019. BERT: Pre-training of deep bidirectional transformers for language under- standing. In North American Association for Computational Linguistics (NAACL).
- XLM: Guillaume Lample and Alexis Conneau. 2019. Crosslingual language model pretraining. arXiv preprint arXiv:1901.07291.
Finetune:
-
GPT: Alec Radford, Karthik Narasimhan, Time Salimans, and Ilya Sutskever. 2018. Improving language understanding with unsupervised learning. Technical report, OpenAI.
-
ULMFiT
-
UniLM: Li Dong, Nan Yang, Wenhui Wang, Furu Wei, Xiaodong Liu, Yu Wang, Jianfeng Gao, Ming Zhou, and Hsiao-Wuen Hon. 2019. Unified language model pre-training for natural language understanding and generation. arXiv preprint arXiv:1905.03197.
-
ERNIE (Entity Embedding): Yu Stephanie Sun, Shuohuan Wang, Yukun Li, Shikun Feng, Xuyi Chen, Han Zhang, Xinlun Tian, Danxi- ang Zhu, Hao Tian, and Hua Wu. 2019. ERNIE: Enhanced representation through knowledge integra- tion. arXiv preprint arXiv:1904.09223.
-
SpanBERT (span prediction): Mandar Joshi, Danqi Chen, Yinhan Liu, Daniel S. Weld, Luke Zettlemoyer, and Omer Levy. 2019. SpanBERT: Improving pre-training by representing and predicting spans. arXiv preprint arXiv:1907.10529.
自回归预训练的变种:
- MASS: Kaitao Song, Xu Tan, Tao Qin, Jianfeng Lu, and Tie-Yan Liu. 2019. MASS: Masked sequence to sequence pre-training for language generation. In International Conference on Machine Learning (ICML).
- KERMIT: William Chan, Nikita Kitaev, Kelvin Guu, Mitchell Stern, and Jakob Uszkoreit. 2019. KERMIT: Generative insertion-based modeling for sequences. arXiv preprint arXiv:1906.01604.
- XLNet: Zhilin Yang, Zihang Dai, Yiming Yang, Jaime Car- bonell, Ruslan Salakhutdinov, and Quoc V Le. 2019. Xlnet: Generalized autoregressive pre-training for language understanding. arXiv preprint arXiv:1906.08237.
更多数据大模型:
- BERT
- Alexei Baevski, Sergey Edunov, Yinhan Liu, Luke Zettlemoyer, and Michael Auli. 2019. Cloze-driven pretraining of self-attention networks. arXiv preprint arXiv:1903.07785.
- XLNet
- GPT-2: Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei, and Ilya Sutskever. 2019. Language models are unsupervised multitask learners. Technical report, OpenAI.
胡思乱想
忽然发现近年来的论文公式是越来越少,整个就成了各式各样的实验报告,各种 Trick 满天飞,这是要变成经验科学了么……说不清楚是好是坏,但个人对这个趋势不太认同,还是希望能百花齐放。论文整理完才发现貌似没有太多东西,这几个小 Trick 更像是锦上添花,我甚至怀疑是不是因为数据量大了、训练时间长了,所以结果变好了,毕竟公开数据集就那点东西。其实就自己感觉,后 BERT 时代的种种搞法都没从本质上改变什么,NLP 不该在这条路上一路走到黑,尤其发散型任务(比如文本生成),能否在强化学习、GAN 方面进一步突破呢?