Paper:https://arxiv.org/pdf/1910.13461.pdf
Code:https://github.com/pytorch/fairseq
核心思想:基于 Transformer Seq2Seq 架构适应各种不同的输入噪声。
What
动机和核心问题
MLM 的方法通常专注于特定类型的最终任务(例如跨度预测,生成等),从而限制了它们的适用性。BART 结合了双向和自回归的 Transformer(可以看成是 Bert + GPT2)。具体而言分为两步:
- 任意的加噪方法破坏文本
- 使用一个 Seq2Seq 模型重建文本
主要的优势是噪声灵活性,也就是更加容易适应各种噪声(转换)。BART 对文本生成精调特别有效,对理解任务也很有效。它还提供了一种精调的新思路,效果嘛,如果不好就不会有论文了。
模型和算法
架构就是 Seq2Seq 的 Transformer,相比 Bert 有以下不同:
- Decoder 的每一层增加对 Encoder 最后隐层的交叉注意力(类似 Luong Attention,也是最初的 Attention 机制)
- 没有使用 Bert 在预测词的那个额外的前馈网络(这里说的应该就是那个 Pooler)
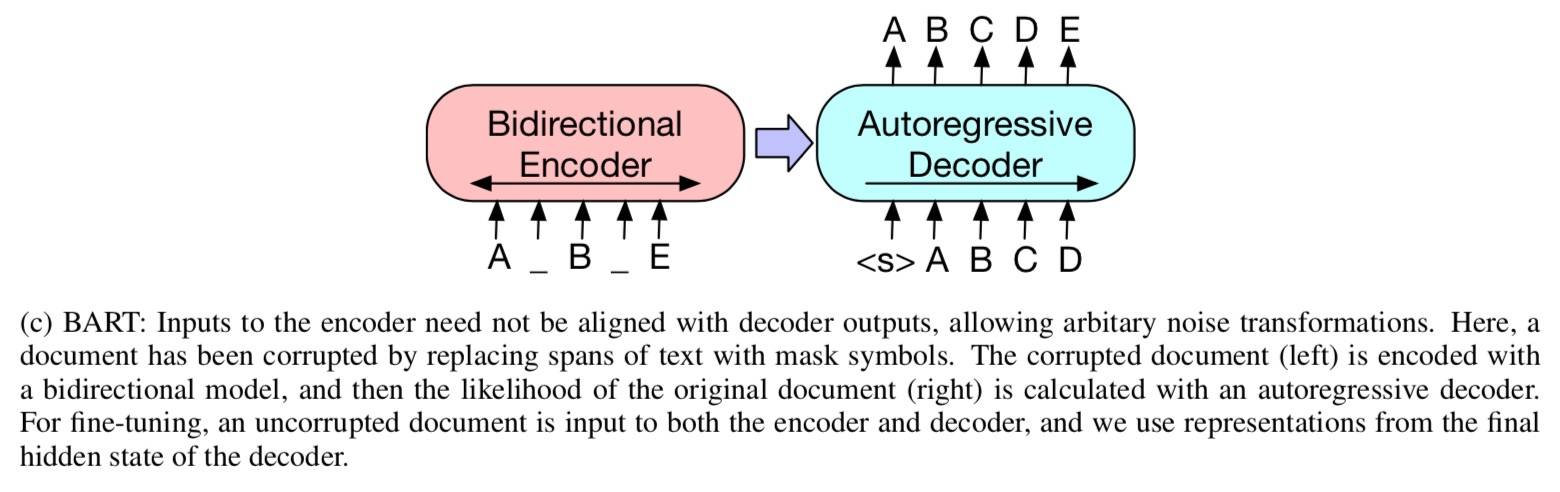
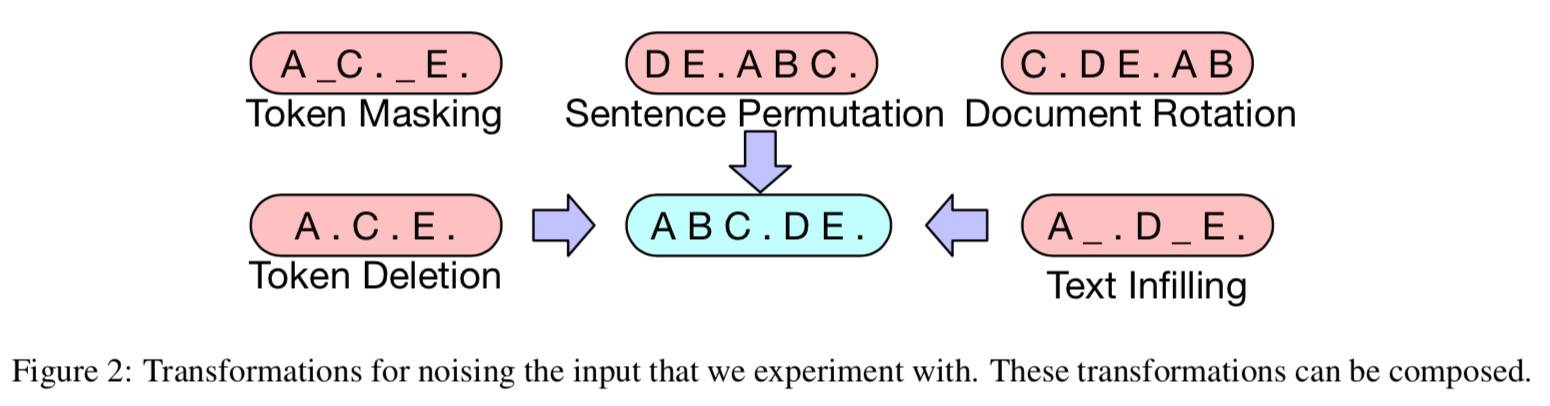
Bart 允许任意的噪声,极端情况(比如所有源信息都丢失)下其实是一种语言模型(和 GPT2 类似)。具体包括:
- Token 遮蔽:和 Bert 一样。
- Token 删除:输入中随机删除 Token,模型必须确定哪些位置是被删除的。
- 文本填充:文本跨度长度从泊松分布(λ= 3)中得出,每个跨度替换为一个
[MASK],0 对应插入。这个灵感来自 SpanBert,不同的是,但是 SpanBERT 采样跨度来自不同(固定几何)分布的长度,并用长度完全相同的[MASK]序列替换每个跨度 。 文本填充可以指导模型预测跨度中缺少多少个 Token。 - 句子排列:文档被切分成句子,然后随机 shuffle。
- 文档旋转:随机均匀选择一个 Token,让文档从选中的 Token 开始,训练模型识别文档的开始。
以下代码我们参考 Transformer 中的实现。首先看配置:
1 | # From transformers |
然后是模型:
1 | # From transformers |
除了 Encoder 和 Decoder 外,有个需要注意的是 generation_mode 参数,当它为 True 时为生成模式,此时不需要 Mask;当为 False 时,与 GPT2 一样,需要对 Padding 和未来时间的 Token 进行 Mask。举个例子:
1 | # Bart Speical Tokens |
这里的 decoder_input_ids 其实是 input_ids 的上一步,两个 Mask 一目了然。
接下来就是两个核心组件:Encoder 和 Decoder 了,首先看一下简化的结构(以 Base 为例):
1 | BARTModel( |
EncoderLayer 其实就是 Bert 的 EncoderLayer:
1 | # From transformers |
对比了一下 Transformer Bert 的实现,唯一的不同就是激活函数后面多了一个 Dropout。大致还是可以分为三块:自注意力模块、中间模块和输出模块。
Decoder 部分是在 GPT2 的基础上增加了交叉 Attention,具体代码如下:
1 | # From transformers |
大部分读者应该已经非常熟悉 Transformer 了,SelfAttention 的 qkv 都是输入的 x,而 Cross-Attention 的 q 是输入的 x,但 k 和 v 就变成了 Encoder 的最后隐层。另外需要注意的是,与 Encoder 的 SelfAttention 相比,Decoder 的 SelfAttention 需要 Mask 当前 Token 后面的 Token。这也就是 Transformer 架构的三种 Attention 机制。具体可以参考这里。
特点和创新
- 提出了一种更加有效地预训练方法,就是把 Transformer 整体作为预训练的架构。
- 使用任意噪声的输入。
How
如何构造数据并训练
官方并未提供预训练说明和代码,GitHub 上有个 Issue 可以关注:
Transformer 也没提供:
不过根据另一个 Issue 提供的训练时长,一般人应该也不会自己训练吧:
想想也是,一个 Bert 或 GPT2 都不小了,这还两个,能不慢才怪。
如何使用结果
文章介绍了如何在多种下游任务中进行使用:
- 序列分类:相同的 input 喂入 Encoder 和 Decoder,Decoder 最后一个 Token(EOS)的 hidden state 喂入多分类线性分类器。和 Bert 不同,最后添加 EOS 作为句子关系的标记。
- 序列标注:将整个文档喂入 Encoder 和 Decoder,使用 Decoder 顶部隐藏状态作为每个单词的表示。
- 序列生成:Encoder 输入句子,Decoder 输出。
- 翻译(源→英文):通过添加从双向语料学习的新的 Encoder 参数集,可以整体作为预训练的 Decoder。具体而言就是把 Bart 的 Encoder 替换为随机初始化的一个 Encoder,新的 Encoder 要学习源语言 Token 到 Bart 能够去噪为英文的输入映射。训练源 Encoder 分两步,都从 BART 模型的输出反向传播交叉熵损失。
- 第一步,冻结大多数 BART 参数,仅更新随机初始化的源 Encoder:位置 Embedding 和 Encoder 第一层的自注意输入投影矩阵。
- 第二步,训练所有模型参数进行少量迭代。
具体可以参考官方提供的 Example,使用并不复杂:
另外,我们也可以参考 Transformer 使用,其实预训练模型使用都是类似的,它们的共同点就是对输入的 Token 返回一个隐层表示,不同的模型和任务对输入和输出后的控制略有差别。
数据和实验
Base
需要说明的是,作者这里对对比模型重新进行了训练,细节可以参考论文。
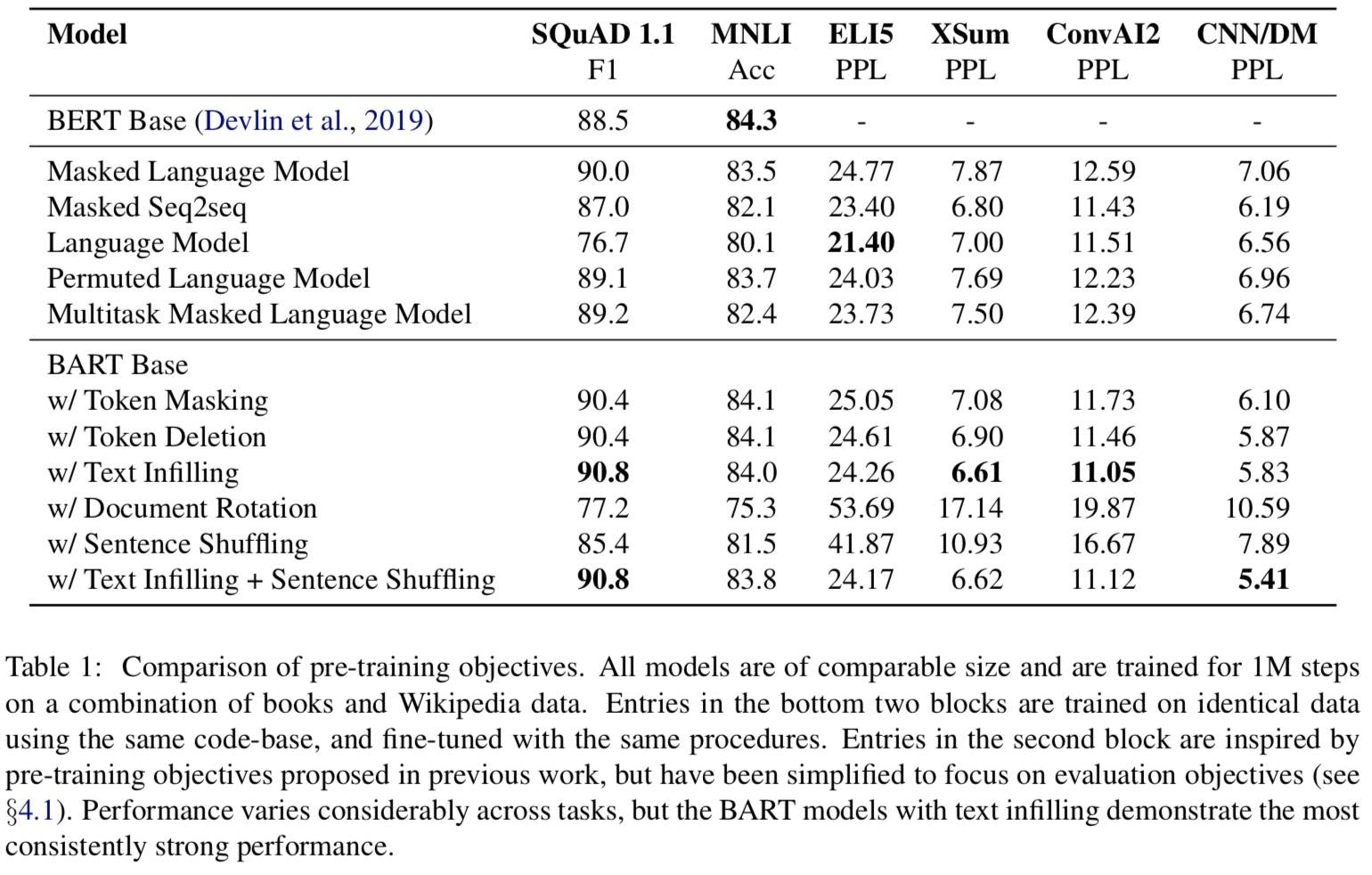
结论如下:
- 预训练方法的性能在各个任务中有很大不同
- Token Mask 至关重要,旋转文档和句子 Shuffle 表现不佳
- 从左到右的预训练模型能提高文本生成能力
- 双向模型对于 SQuAD 至关重要
- 预训练目标并不是唯一重要的因素
- 纯语言模型在 ELI5 上表现最佳
- 除此之外,使用了文本填充的 Bart 表现很好
大模型
实验设置:
- Encoder 和 Decoder 各 12 层,hidden size 1024
- batch size 8000,500000 steps
- 文本填充 + 句子排列,每个文档 Mask 30% Token,变换所有句子
- 最后 10% 的训练步不使用 dropout
- 数据集 160G,包括新闻、书籍、故事和网络文本
分类任务:

生成任务:

除了摘要外,在对话回复、QA 方面也取得了 state-of-the-art 结果。
翻译:

Baseline 是 Transformer 架构。
整体而言,在理解+生成的任务上表现想当可观,比如文本摘要、对话回复。
Discussion
相关工作
- GPT 是单向语言模型,ELMo 双向但是互相没有交互。
- BERT 使用 MLM 构建双向语言模型,RoBERTa, ALBERT 和 SpanBert 对其进行了优化,因为不是自回归模型,所以在文本生成任务上效果一般。
- UniLM 使用一组 MASK,有些只允许使用左边的上下文,所以可以同时用于生成和判别任务。与 Bart 不同的是 UniLM 在预测上是条件独立的,Bart 采用的是自回归。 BART 减少了预训练和生成任务之间的不匹配,因为 Decoder 始终在未损坏的上下文中进行训练。
- MASS 与 Bart 最类似,连续跨度(span)的 Token 被遮盖的输入映射到被遮盖的 Token 序列。由于不相交的 Token 集喂入 Encoder 和 Decoder,MASS 在判别任务上表现一般。
- XLNet 通过以排列自回归预测被屏蔽的 Token 来扩展 BERT。它允许预测以左右上下文为条件。
打开脑洞
乍一看貌似好像没啥创新点,就是用了 Transformer 的架构作为预训练方法,原因是因为能够同时顾及到 MLM 和从左到右的语言模型,可以看成是后 Bert 时代预训练方法的综合集成。不过稍微想一想就知道,这样的模型必然是巨大且相对复杂的;而且 MLM 和自回归语言模型之间是否有冗余也不甚明确,但效果从理论上预期肯定会比单纯使用一种方法好。也许正如作者所期望的那样,MLM 负责理解,Auto-Regressive LM 负责生成,所以在文本摘要和对话回复等任务上才有那么大的效果提升。唯一的问题可能还是太复杂了,一个 Bert 都让工业界大多数中小公司头大了,这 Bart 还怎么上。想想刚开始那阵美滋滋地上了一个基于 Bert 的模型,结果并发上不去(只有普通的 CPU 服务器),C++,Rust 怼上去都没用,最后还是只能回到 Tiny 版甚至 Lite 版,做各种压缩,现在还在坑里没出来。
论文的相关工作部分总结的不错,本来还想看一下 SpanBert,UniLM,MASS 的,搞得都没有欲望了。谁让论文这么多呢,2020 年都过了一半了还在补 2019 年的作业。至于如何在 Bart 上进一步提升,目前的感觉应该就是知识图谱了,毕竟预训练已经足够 general 的时候,领域知识就显得更加重要了;然后具体任务上可能要引入强化学习,即用某种规则去 “引导” AI,这类算法还包括遗传算法、PSO 粒子群算法、蚁群算法等。关于整体架构的思考,感兴趣的小伙伴可以查看 2018 年的这篇文章。