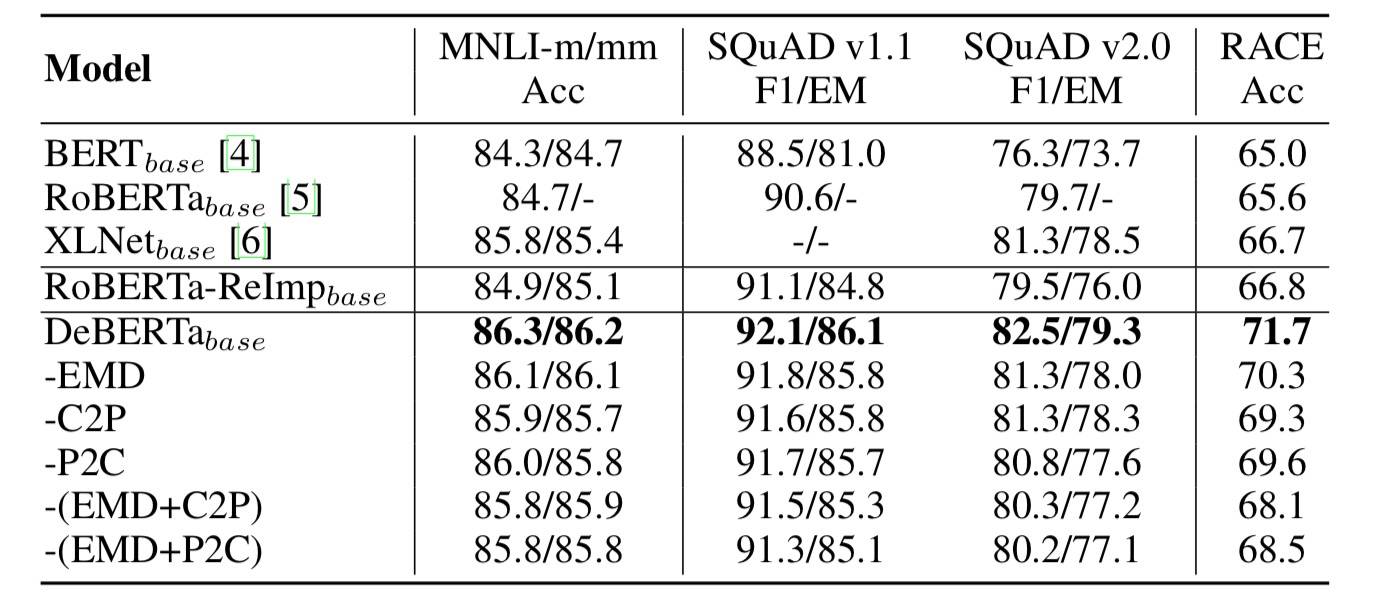
defforward(self, hidden_states, attention_mask, return_att=False, query_states=None, relative_pos=None, rel_embeddings=None): """ Call the module Args: hidden_states (:obj:`torch.FloatTensor`): Input states to the module usally the output from previous layer, it will be the Q,K and V in `Attention(Q,K,V)` attention_mask (:obj:`torch.ByteTensor`): An attention mask matrix of shape [`B`, `N`, `N`] where `B` is the batch size, `N` is the maxium sequence length in which element [i,j] = `1` means the `i` th token in the input can attend to the `j` th token. return_att (:obj:`bool`, optional): Whether return the attention maxitrix. query_states (:obj:`torch.FloatTensor`, optional): The `Q` state in `Attention(Q,K,V)`. relative_pos (:obj:`torch.LongTensor`): The relative position encoding between the tokens in the sequence. It's of shape [`B`, `N`, `N`] with values ranging in [`-max_relative_positions`, `max_relative_positions`]. rel_embeddings (:obj:`torch.FloatTensor`): The embedding of relative distances. It's a tensor of shape [:math:`2 \\times \\text{max_relative_positions}`, `hidden_size`]. """ # (batch_size, seq_len, hidden_size * 3) qp = self.in_proj(hidden_states) # (batch_size, num_attention_heads, seq_len, 3 * attention_head_size).chunk(3, dim=-1) => # (batch_size, num_attention_heads, seq_len, attention_head_size) query_layer,key_layer, value_layer = self.transpose_for_scores(qp).chunk(3, dim=-1) query_layer += self.transpose_for_scores(self.q_bias.unsqueeze(0).unsqueeze(0)) value_layer += self.transpose_for_scores(self.v_bias.unsqueeze(0).unsqueeze(0))
rel_att = None # Take the dot product between "query" and "key" to get the raw attention scores. scale_factor = 1 if'c2p'inself.pos_att_type: scale_factor += 1 if'p2c'inself.pos_att_type: scale_factor += 1 if'p2p'inself.pos_att_type: scale_factor += 1 scale = math.sqrt(query_layer.size(-1)*scale_factor) query_layer = query_layer/scale # (batch_size, num_attention_heads, query_size, key_size) attention_scores = torch.matmul(query_layer, key_layer.transpose(-1, -2)) # 本文定义的额外计算 Attention 分数 rel_embeddings = self.pos_dropout(rel_embeddings) # (batch_size, num_attention_heads, query_size, key_size) rel_att = self.disentangled_att_bias(query_layer, key_layer, relative_pos, rel_embeddings, scale_factor)
Cheng-Zhi Anna Huang, Ashish Vaswani, Jakob Uszkoreit, Ian Simon, Curtis Hawthorne, Noam Shazeer, Andrew M Dai, Matthew D Hoffman, Monica Dinculescu, and Douglas Eck. Music transformer: Generating music with long-term structure. 2018.
Peter Shaw, Jakob Uszkoreit, and Ashish Vaswani. Self-attention with relative position representations. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 2 (Short Papers), pages 464–468, 2018.