This chapter is devoted to the topic of context-free grammars. They are integral to many computational applications, including grammar checking, semantic interpretation, dialogue understanding, and machine translation.
Constituency
The fundamental notion underlying the idea of constituency is that of abstraction — groups of words behaving as a single units, or constituents.
- noun phrase can occur before verbs
- preposed or postposed constructions
Context-Free Grammars
Context-Free Grammar or CFG are also called Phrase-Structure Grammars, the formalism is equivalent to Backus-Naur Form, or BNF.
A CFG consists of a set of rules or productions, each of which expresses the ways that symbols of the language can be grouped and ordered together, and a lexicon of words and symbols.
Two classes of symbols:
- terminal: words
- non-terminals: express abstractions over terminals
Notice that in the lexicon, the non-terminal associated with each word is its lexical category, or POS.
A CFG can be thought of in two ways:
- as a device for generating sentences
- as a device for assigning a structure to a given sentence
A derivation of the string of words can be represented by a parse tree. The formal language defined by a CFG is the set of strings that are derivable from the designated start symbol.
Three types of phrase:
-
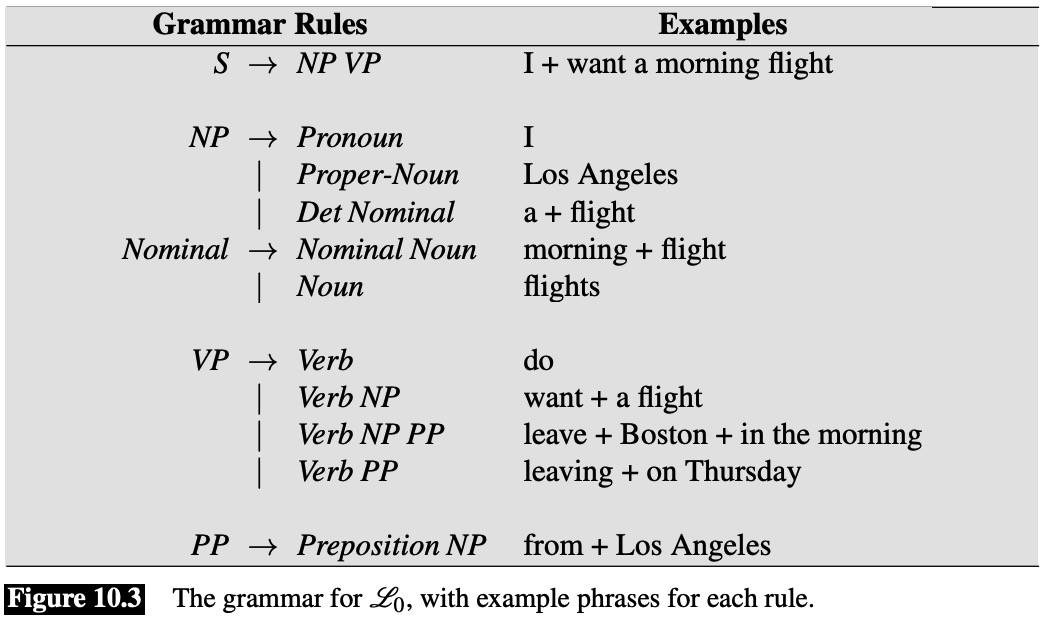
PP: A prepositional phrase generally has a preposition followed by a noun phrase.
-
NP: A noun phrase can be composed of either a ProperNoun or a determiner (Det) followed by a Nominal; a Nominal in turn can consist of one or more Nouns.
-
VP: A verb phrase in English consists of a verb followed by assorted other things.
Sometimes, bracketed notation format is used to represent a parse tree:
[S[NP [Pro I]] [VP [V prefer] [NP [Det a] [Nom [N morning] [Nom [N flight]]]]]]
Sentences (strings of words) that can be derived by a grammar are in the formal language defined by that grammar, and are called grammatical.
Sentences that cannot be derived by a given formal grammar are not in the language defined by that grammar and are referred to as ungrammatical.
In linguistics, the use of formal languages to model natural languages is called generative grammar since the language is defined by the set of possible sentences “generated” by the grammar.
Formal Definition of Context-Free Grammar
A CFG G is defined by a 4-tuple: N, Σ, R, S:
-
N: a set of non-terminal symbols (or variables)
-
Σ: a set of terminal symbols (disjoint from N)
-
R: a set of rules or productions, each of the form A → β
- A: a non-terminal
- β: a string of symbols from the infinite set of strings
(Σ U N) *
-
S: a designated start symbol and a member of N
if A → β is a production of R and α and γ are any strings in the set (Σ U N) *, then we say that αAγ directly derives αβγ, or αAγ=>αβγ.
Derivation is then a generalization of direct derivation:
Let α1, α2, …, αm be strings in (Σ U N)∗,m ≥ 1, such that:
α1 => α2, α2 => α3, …, α_{m-1} => αm
We say that α1 derives αm.
The language LG generated by a grammar G as the set of strings composed of terminal symbols that can be derived from the designated start symbol S:
L_G = {w | w is in Σ* and S => w}
Mapping from a string of words to its parse tree is called syntactic parsing.
Some Grammar Rules for English
Sentence-Level Constructions
Four common and important sentences:
-
Sentences with declarative structure have a subject noun phrase followed by a verb phrase.
-
Sentences with imperative structure often begin with a verb phrase and have no subject.
-
Sentences with yes-no question structure are often (though not always) used to ask questions.
-
One constituent is a wh-phrase, that is one that includes a wh-word.
- The wh-subject-question structure is identical to the declarative structure, except that the first noun phrase contains some wh-word.
- The wh-non-subject-question structure which the wh-phrase is not the subject of the sentence, so the sentence includes another subject. It contains long-distance dependencies.
Clauses and Sentences
S rules are intended to account for entire sentences that stand alone as fundamental units of discourse. However, S can also occur on the right-hand side of grammar rules and hence can be embedded within larger sentences.
A clause often describe as forming a complete thought, of which S is a node of the parse tree below which the main verb of the S has all of its arguments.
The Noun Phrase
There are three most frequent types of noun phrases: pronouns, proper nouns and NP→Det Nominal construction. Here focus the last type which consists of a head, the central noun in the noun phrase, along with various modifiers that can occur before or after the head noun.
-
The Determiner
- a, the, this, some, those, US’s, Jim’s, etc.
- mass nouns also don’t require determination.
-
The Nominal
- The nominal construction follows the determiner and contains any pre- and posthead noun modifiers.
-
Before the Head Noun
- Cardinal numbers, ordinal numbers, quantifiers and adjectives can appear before the head noun in a nominal.
- Adjectives can also be grouped into a phrase called an adjective phrase or AP.
-
After the Head Noun
- A head noun can be followed by postmodifiers. Three kinds of nominal postmodifiers are common in English: prepositional phrases, non-finite clauses, relative clauses.
- non-finite postmodifiers are the gerundive (-ing), -ed, and infinitive forms.
- A postnominal relative clause (more correctly a restrictive relative clause), is often begins with a relative pronoun (that and who are the most).
- Various postnominal modifiers can be combined.
-
Before the Noun Phrase
- Word classes that modify and appear before NPs are called predeterminers.
- Many of these have to do with number or amount; a common predeterminer is all.
The Verb Phrase
The verb phrase consists of the verb and a number of other constituents.
Verb followed by an entire embedded sentence is called sentential complements.
Verbs are compatible with different kinds of complements. In traditional grammar:
- transitive takes a direct object NP
- intransitive do not
Modern grammars subcategorize verbs into as many as 100 subcategories. A verb subcategorizes for an NP or a non-finite VP (which are called complements of the verb). The possible sets of complements are called the subcategorization frame for the verb. We can capture the association between verbs and their complements by making separate subtypes of the class Verb. The problem is the significant increase in the number of rules and the associated loss of generality.
Coordination
A coordinate noun phrase can consist of two other noun phrases separated by a conjunction. The meta-rules is like: X → X and X (X stands for any non-terminal rather than a nonterminal itself).
Treebanks
A corpus where every sentence in the collection is paired with a corresponding parse tree, such a syntactically annotated corpus is called a treebank.
A feature of Penn Treebanks: the use of traces (-NONE- nodes) to mark long-distance dependencies or syntactic movement.
Syntactic constituents could be associated with a lexical head; N is the head of an NP, V is the head of a VP.
The head is the word in the phrase that is grammatically the most important. Heads are passed up the parse tree; thus, each non-terminal in a parse tree is annotated with a single word, which is its lexical head.
An alternative approach to finding a head is used in most practical computational systems. Instead of specifying head rules in the grammar itself, heads are identified dynamically in the context of trees for specific sentences.
Grammar Equivalence and Normal Form
We usually distinguish two kinds of grammar equivalence:
-
weak equivalence: generate the same set of strings and assign the same phrase structure to each sentence
-
strong equivalence: generate the same set of strings
It is sometimes useful to have a normal form for grammars, in which each of the productions takes a particular form. For example, a context-free grammar is in Chomsky normal form (CNF) if it is ε-free and if in addition each production is either of the form A → B C (two non-terminal symbols) or A → a (one terminal symbol). CNF grammars are binary branching, that is they have binary trees (down to the pre-lexical nodes).
Any context-free grammar can be converted into a weakly equivalent Chomsky normal form grammar.
The generation of a symbol A with a potentially infinite sequence of symbols B with a rule of the form A → A B is known as Chomsky-adjunction.
It’s much better to read 自然语言计算机形式分析的理论与方法笔记 (Ch03) | Yam first.
Lexicalized Grammars
The approach to grammar presented thus far emphasizes phrase-structure rules while minimizing the role of the lexicon. However, as we saw in the discussions of agreement, subcategorization, and long distance dependencies, this approach leads to solutions that are cumbersome at best, yielding grammars that are redundant, hard to manage, and brittle.
To overcome these issues, numerous alternative approaches have been developed that all share the common theme of making better use of the lexicon:
- Lexical-Functional Grammar (LFG) (Bresnan, 1982)
- Head-Driven Phrase Structure Grammar (HPSG) (Pollard and Sag, 1994)
- Tree-Adjoining Grammar (TAG) (Joshi,1985)
- Combinatory Categorial Grammar (CCG)
These approaches differ with respect to how lexicalized they are — the degree to which they rely on the lexicon as opposed to phrase structure rules to capture facts about the language.
All these can be read in 自然语言计算机形式分析的理论与方法笔记 (Ch04) | Yam and 自然语言计算机形式分析的理论与方法笔记 (Ch03) | Yam.
Combinatory Categorial Grammar
The categorial approach consists of three major elements: a set of categories, a lexicon that associates words with categories, and a set of rules that govern how categories combine in context.
Categories
Categories are either atomic elements or single-argument functions that return a category as a value when provided with a desired category as argument.
A set of categories L for a grammar:
- A is a subset of L, where A is a given set of atomic elements
(X/Y), (X\Y) ∈ L, if X, Y ∈ L, the slash defines a function which specifies the type of the expected argument, the direction it is expected be found, and the type of the result.(X/Y)is a function that seeks a constituent of type Y to its right and returns a value of X.
The set of atomic categories is typically very small and includes familiar elements such as sentences and noun phrases. Functional categories include verb phrases and complex noun phrases among others.
The Lexicon
The lexicon in a categorial approach consists of assignments of categories to words. These assignments can either be to atomic or functional categories, and due to lexical ambiguity words can be assigned to multiple categories.
Rules
The rules of a categorial grammar specify how functions and their arguments combine. The following two rule templates constitute the basis for all categorial grammars.
X/Y Y => X: forward function applicationY X\Y => X: backward function application
The result of applying either of these rules is the category specified as the value of the function being applied.
The basic categorial approach does not give us any more expressive power than we had with traditional CFG rules; it just moves information from the grammar to the lexicon. To move beyond these limitations CCG includes operations that operate over functions:
- compose: Both kinds of composition are signalled by a B in CCG diagrams, accompanied by a
< or >to indicate the direction.X/Y Y/Z => X/Z: forward compositionY\Z X\Y => X\Z: backward composition
- type raising: elevates simple categories to the status of functions. The category T in these rules can correspond to any of the atomic or functional categories already present in the grammar.
X ⇒ T/(T\X)X ⇒ T\(T/X)
CCGBank
It was created by automatically translating phrase-structure trees from the Penn Treebank via a rule-based approach.
Summary
-
Groups of consecutive words act as a group or a constituent, which can be modeled by context-free grammars (which are also known as phrase-structure grammars).
-
A context-free grammar consists of a set of rules or productions, expressed over a set of non-terminal symbols and a set of terminal symbols. Formally, a particular context-free language is the set of strings that can be derived from a particular context-free grammar.
-
A generative grammar is a traditional name in linguistics for a formal language that is used to model the grammar of a natural language.
-
There are many sentence-level grammatical constructions in English; declarative, imperative, yes-no question, and wh-question are four common types; these can be modeled with context-free rules.
-
An English noun phrase can have determiners, numbers, quantifiers, and adjective phrases preceding the head noun, which can be followed by a number of postmodifiers; gerundive VPs, infinitives VPs, and past participial VPs are common possibilities.
-
Subjects in English agree with the main verb in person and number.
-
Verbs can be subcategorized by the types of complements they expect. Simple subcategories are transitive and intransitive; most grammars include many more categories than these.
-
Treebanks of parsed sentences exist for many genres of English and for many languages.
-
Any context-free grammar can be converted to Chomsky normal form, in which the right-hand side of each rule has either two non-terminals or a single terminal.
-
Lexicalized grammars place more emphasis on the structure of the lexicon, lessening the burden on pure phrase-structure rules.
-
Combinatorial categorial grammar (CCG) is an important computationally relevant lexicalized approach. It consists of three major elements: a set of categories, a lexicon that associates words with categories, and a set of rules that govern how categories combine in context.