GitHub:BytedTsinghua-SIA/DAPO: An Open-source RL System from ByteDance Seed and Tsinghua AIR
Paper:DAPO: An Open-Source LLM Reinforcement Learning System at Scale
DAPO
DAPO,一个对GRPO全方位优化的Policy优化算法,有必要单独记录一下。损失如下:
其中:
看着和GRPO有点像。为了便于对比,把GRPO损失一并贴出来:
其中:
r和A同上。oi表示输出的第i个Token。
DAPO去掉了KL,观点是,模型分布可能与初始模型有很大差异,因此不需要这种限制。这点和我本人之前的认知不太一样,我认为Base是相对稳定的,分布差异应该不大。所以自然就有个疑惑:去掉KL到底是因为RL后续训练偏离Base较大导致限制没作用,还是偏离Base较小所以没作用?后来X哥提醒了一句:“这个应该不是偏离过大,而是针对Base到LongCoT本来变化大”,从这个角度看KL确实没太多意义。
奖励函数还是简单的规则:正确1分,否则-1分。
Clip-Higher
这个主要源于使用PPO或GRPO训练时观察到的熵坍缩现象(本节后面的图),就是Policy的熵迅速下降,导致某些组生成的结果几乎相同,限制了探索。
clip的上限会限制Policy的探索能力,导致Exploitation的Token比Exploration的Token更可能出现。
为什么clip的机制会影响概率?准确来说,是限制了低概率Token的概率增长,从而限制了多样性。
请看下式:
该式很容易通过前面的损失函数推导,可得出:
- 旧概率较大的Token,其变化范围较大。
- 旧概率较小的Token,其变化范围很小。
举个例子(方便起见假设low和high不区分),ϵ=0.2,对于概率0.01的Token:
而对于概率0.9的Token:
高概率Token的概率变化范围比低概率Token的大的多,低概率即使调整后,最高也只能到0.012,实验结果表面,被裁剪影响的Token最高概率大约 < 0.2;而高概率的Token变化相对自由。
所以说,clip 机制确实抑制了低概率Token的增长,它们可能永远无法成为高概率Token,因为模型更倾向于维持原有的高概率Token(高概率Token更容易保持高概率或继续增加),而不是探索新的Token,导致生成的内容缺乏多样性。
这就是第一个改进点:设置两个不同的ϵ,low设置的小一点,high设置的高一点。从而给低概率Token一定增长空间。论文中low被设置成0.2,high被设置成0.28。看起来好像也没增加多少;)
low相对较小,太大的low(1-low很小)可能导致Token概率被压缩到0,从而导致采样空间崩溃。
效果如下:
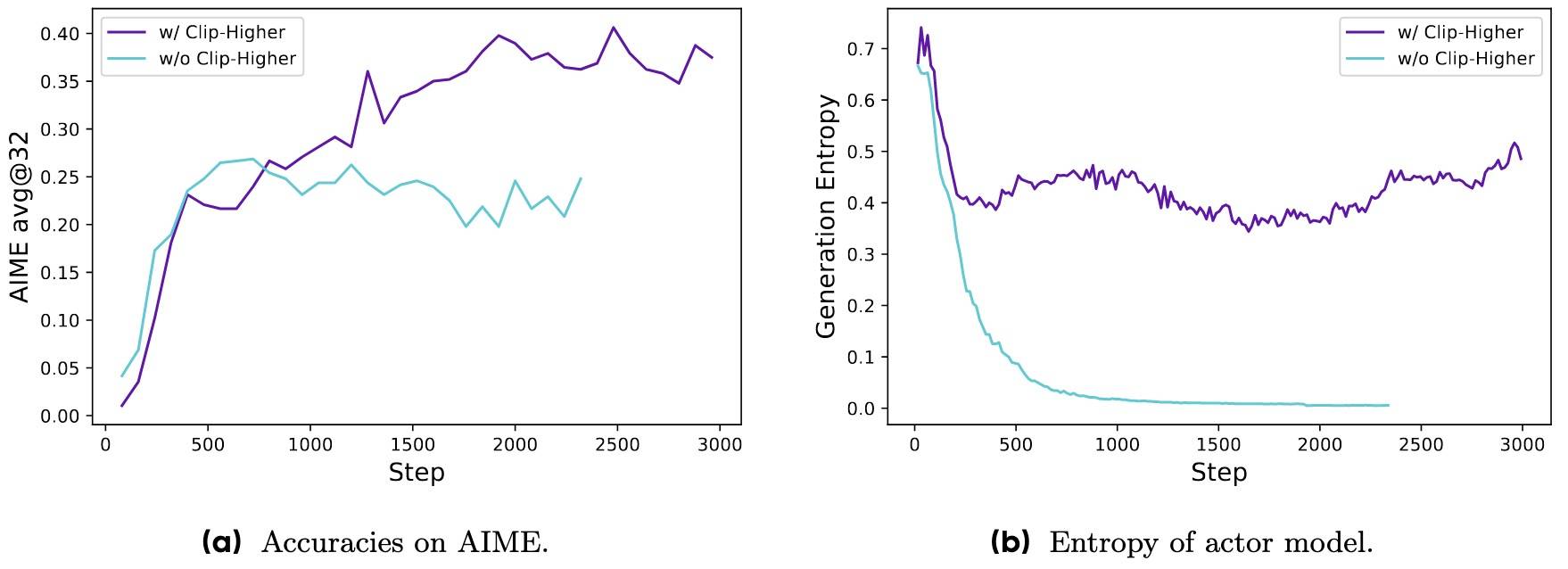
该调整有效提升了Policy的熵,并促进了更多样化样本的生成。
Dynamic Sampling
现有RL算法的问题:当某些提示词Acc等于1时的梯度消失问题。因为Acc为1时,GRPO一组输出的Reward都是1,Advantage等于0,此时Policy没有优化,因此降低了样本效率。根据经验,精度等于1的样本数量会在训练过程中持续增加。
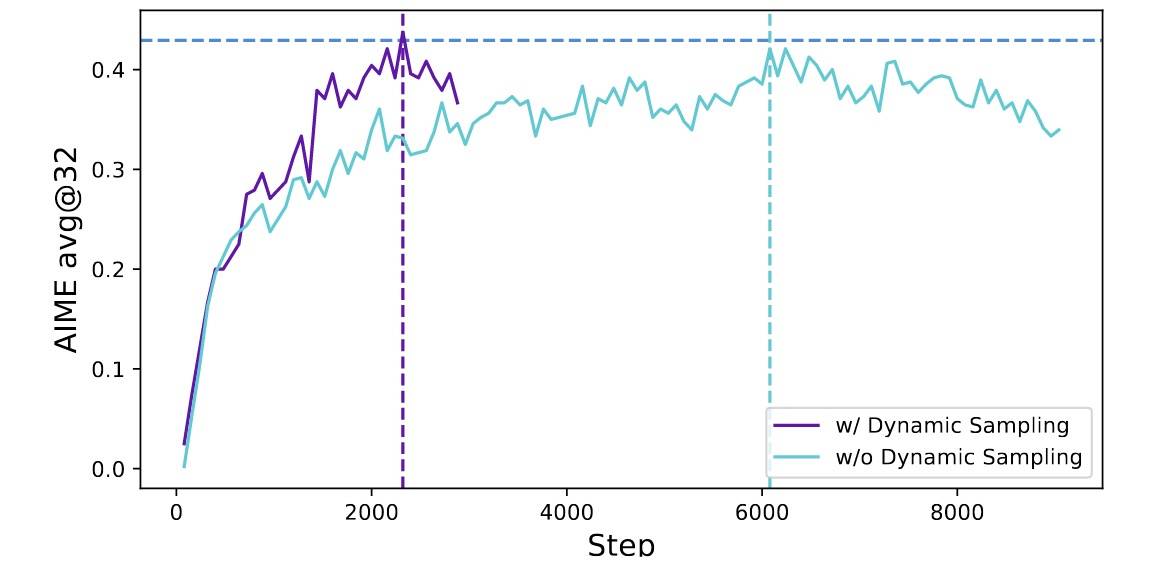
因此,使用过采样并过滤掉准确度等于1和0的提示词,也就是损失函数中的 s.t. 部分,equivalent的意思是样本是等效的(过滤掉无效的)。具体做法是:在训练前持续采样,直到批次被准确率既不为 0 也不为 1 的样本完全填充。
这个策略不一定会影响训练效率。但是更快地达到相同的性能。效果如下:
Token-Level Policy Gradient Loss
GRPO采用样本级别的Loss计算,即首先在每个样本内按Token对损失进行平均,然后在样本之间聚合损失。每个样本对总Loss是等权的。
论文发现,较长回复中的Token可能对总体损失的贡献不成比例地较低,这可能导致两个不良影响。
-
对于高质量的长样本,这种效应可能会妨碍模型学习其中与推理相关的模式。
-
观察到过长的样本通常会表现出低质量的模式,如无意义的词语和重复的词汇。由于样本级损失计算无法有效地惩罚长样本中的这些不良模式,导致了熵和响应长度的非正常增加,如图所示。
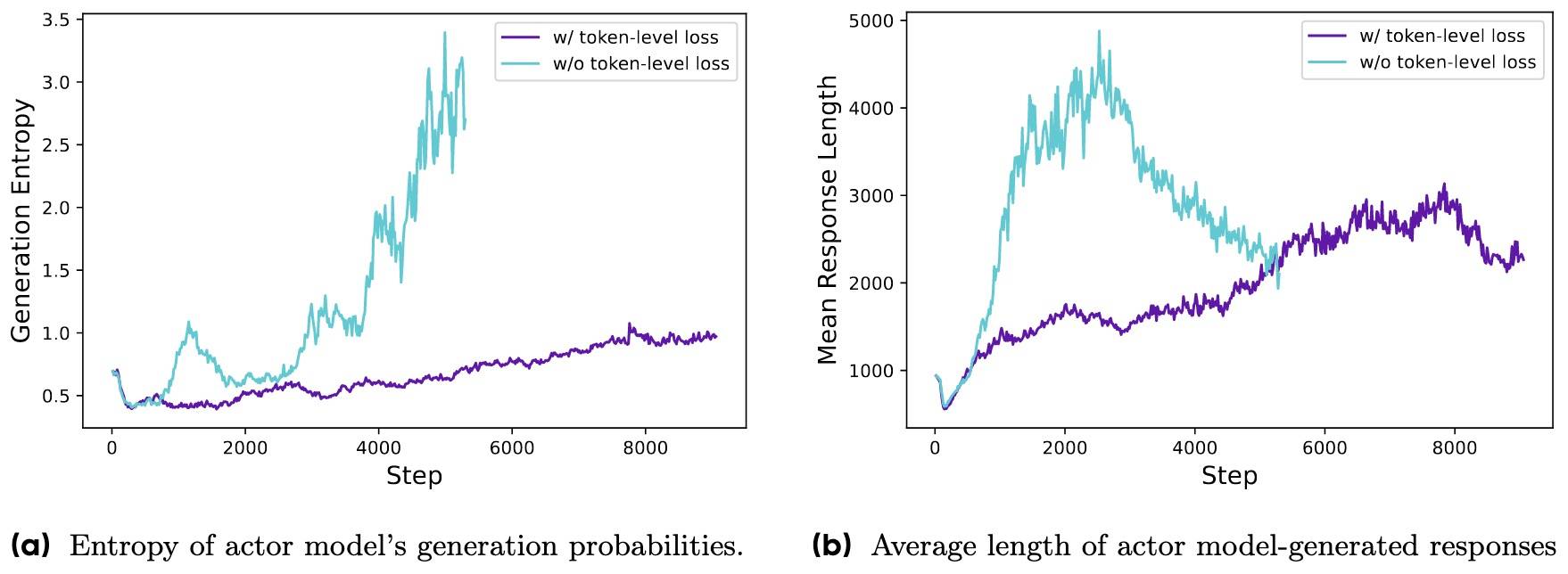
为什么较长回复中的Token对总体损失的贡献更低?因为每个样本都被平均到Token级别了,和长度无关了,导致长样本的影响被“稀释”了,对总Loss的贡献和短样本相同。所以就可能导致高质量的长样本学习的较差,而低质量的长文本又无法得到惩罚。
改进部分体现在损失函数的求和部分。此时,较长的序列(相比短的)对整体Loss的影响更大。此外,从单个Token的角度来看,如果某种特定的生成模式能够导致奖励的增加或减少,那么无论该模式出现在多长的回复中,它都会被同等地促进或抑制。
Overlong Reward Shaping
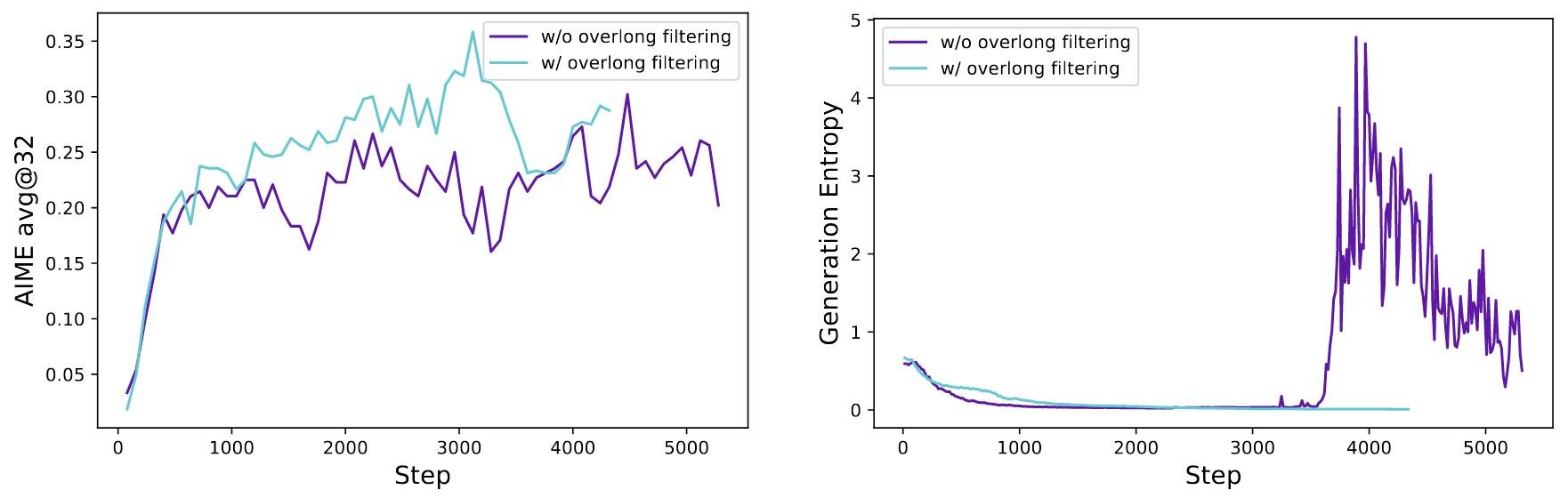
在 RL 训练中,通常为生成设置最大长度,过长的回复会相应截断。论文发现,截断样本的不当奖励塑造(一般提取不到答案,所以Reward为-1)会引入奖励噪声,并严重扰乱训练过程。因为一个合理的推理过程可能仅因长度过长而受到惩罚,使模型对其推理过程的有效性产生困惑。
因此采用过长样本过滤(Overlong Filtering)策略,对被截断的样本屏蔽其损失。论文发现,此方法能显著稳定训练并提升模型性能。如下图所示。
另外,提出了一种基于长度的惩罚机制——软过长惩罚(Soft Overlong Punishment)。
具体来说,当响应长度超过预设的最大值时,定义一个惩罚区间。在区间内,响应越长,受到的惩罚越大。该惩罚将被添加到原始的基于规则的正确性奖励中,从而引导模型避免生成过长的响应。
论文中,预期的最大长度设为 16384 个 Token,并额外分配 4096 个 Token 作为软惩罚缓冲区。因此,生成的最大 Token 数被设定为 20480 个。
各改进贡献
四个改进的贡献分别如下:
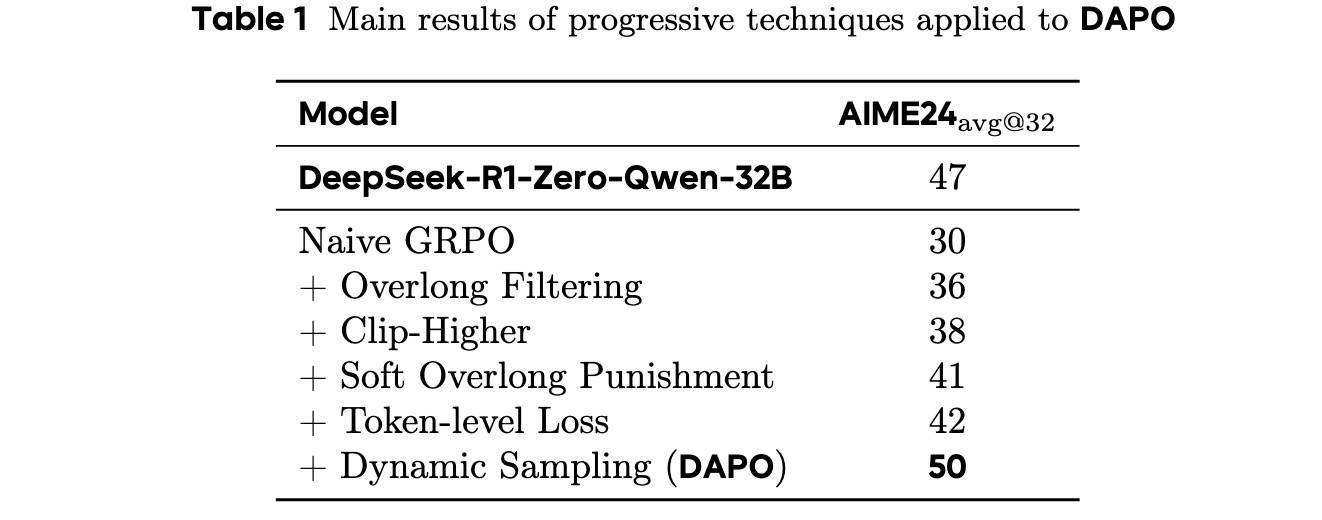
Token级别损失提升很小,但它可以增强训练的稳定性,并使长度增长更加合理(参考上面《Token-Level Policy Gradient Loss》的图)。
对于动态采样,尽管需要采样更多数据,但整体训练时间并未受到显著影响。因为所需的训练步数减少,模型的收敛时间反而缩短(参考《Dynamic Sampling》的图)。
实验过程监控
实验过程中监控关键的中间结果对于快速识别差异来源及最终改进系统至关重要。本文给出了下面几个关键指标:
- 生成回复长度:长度与验证准确性结合使用可作为指标来评估实验是否恶化,如下图a所示。
- 奖励:奖励的增长趋势相对稳定,并不会因实验设置的调整而出现显著波动或下降,如下图b所示。
- Actor(Policy)的熵和生成概率:与模型的探索能力相关,熵需要保持在适当的范围内。过低的熵表明概率分布过于尖锐,导致探索能力丧失;相反,过高的熵通常与过度探索问题相关,如无意义的内容和重复生成,如下图c所示。对于生成概率,情况恰恰相反,如下图d所示。实验发现,保持熵的缓慢上升趋势有助于模型性能的提升。
具体如下图所示:
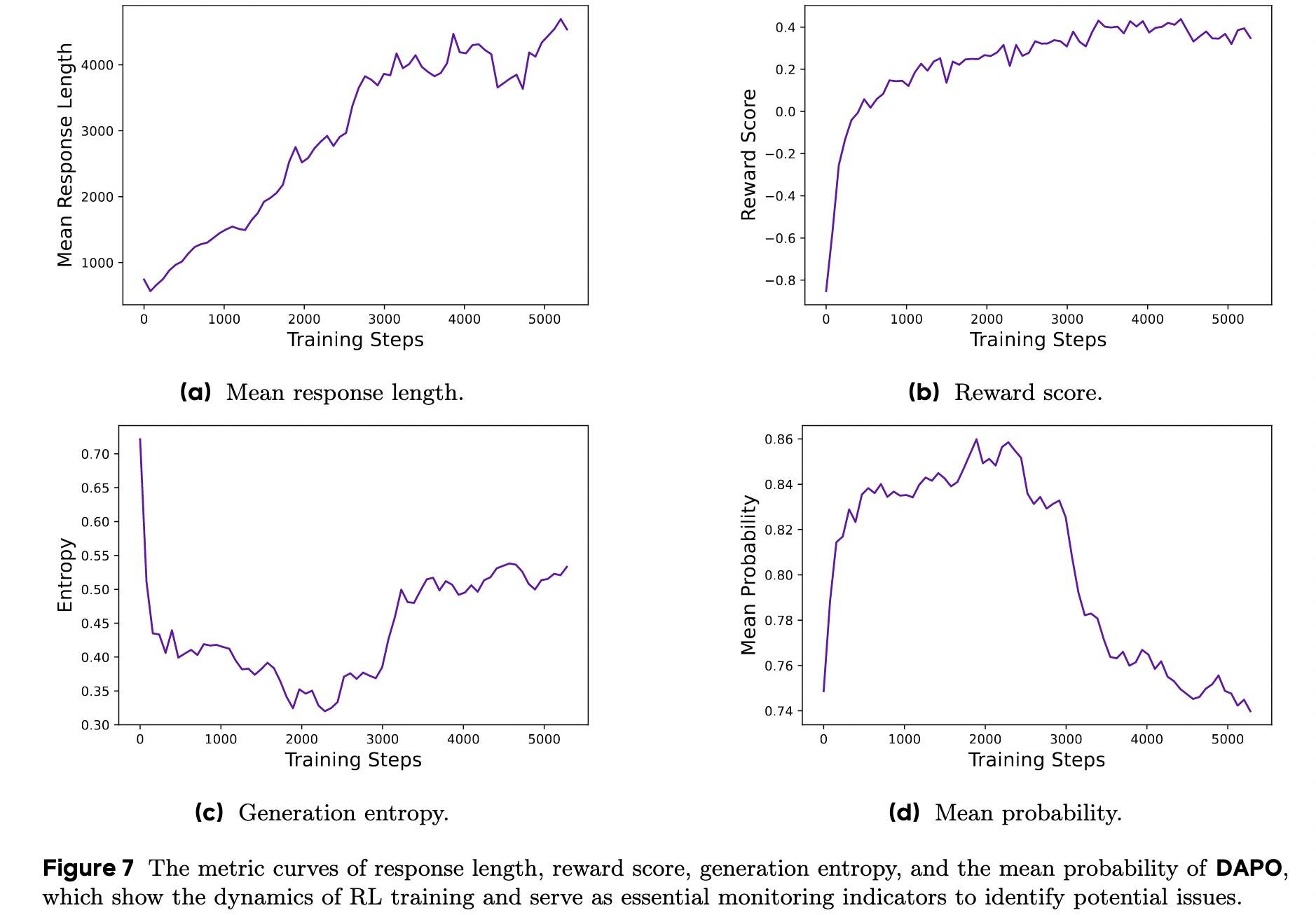
额外补充一下熵,它一般用来衡量系统的不确定性,熵越大不确定性越大。很大的熵意味着稍微有一点额外信息就可能带来大的“确定性”(所以有最大熵模型);相反则意味着系统趋于稳定状态。训练过程中保持熵的缓慢增加意味着保持进一步探索。
最大熵原理的核心思想:在满足已知约束的情况下,选择熵最大的概率分布。这个原则可以解释为:在不知道更多信息的情况下,假设分布尽可能“均匀”或“无偏”,即最大化熵。
小结
本文主要介绍了DAPO及它的四个改进:提高上限(Clip-Higher)、动态采样(Dynamic Sampling)、Token 级策略梯度损失和过长奖励塑造,分别对应clip、数据采样、损失计算和最大长度设计四个方面,都是细节,非常有实际价值。论文整体清晰、干净,非常值得一读。
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。