高质量的数据对LLM的重要性无需赘述,本文记录Ziya2的数据管理。
Ziya2主要关注继续训练和数据质量与模型的关系。继续训练可以参考:Ziya2的继续训练,本文主要看数据处理、数据组合等方面内容。
数据预处理
Ziya2的数据预处理一共有五个步骤:DP、AS、RF、CD和DE。
DP
Data Preprocess,数据预处理,包含以下操作:
- 语言检测。只选择中文和英文数据。
- 标准化并将繁体中文转为简体。
- 移除不可用Token,比如不可见的控制字符、特殊符号、表情符号和不合适的标点符号。
AS
Automatic Scoring,自动打分。通过语言模型评分进行自动质量控制(过滤)。
- 使用KenLM和维基百科数据训练中英文两个语言模型。
- 计算数据的PPL。
- 按PPL排名选择数据,前30%为高质量,30%-60%为中等质量。
RF
Rule-based Filtering,基于规则的过滤。消除敏感和不安全的信息。
- 设计文档、段落和句子级别规则:30+条。
- 按从大到小粒度级别的规则过滤文本。
- 文档级别:主要围绕长度和格式。
- 段落和句子:主要关注内容。
在规则设计的初期,还对原文随机采样进行人工评估,根据人工反馈迭代规则。
CD
Content De-duplication,内容去重。有研究表明重复数据并不能显著提高效果,但却实实在在地降低了效率。Ziya2主要使用了布隆过滤器和SimHash。
- 使用布隆过滤器去除重复URL。尤其是Common Crawl和开源数据集里,有大量重复URL。
- 内容精准去重。分析发现很多Web页面内容非常相似,不同的只有特殊符号,比如标点和表情。
- 使用SimHash进行模糊去重。
另外对处理过的数据也用了缓存,这样新来的数据就不需要重新在所有数据上进行冗余检查。
DE
Data Evaluation,数据评估。主要包括自动和人工评估。
- 自动评估:随机选择1%的数据,计算得分。
- 人工评估:随机采样1000个样本评估。
评估完看看低质量的比例是否低于阈值,如果是则作为训练语料的一部分;如果不是则需要改进前面的流程(AS、RF、CD)。
评价指标如下表所示。
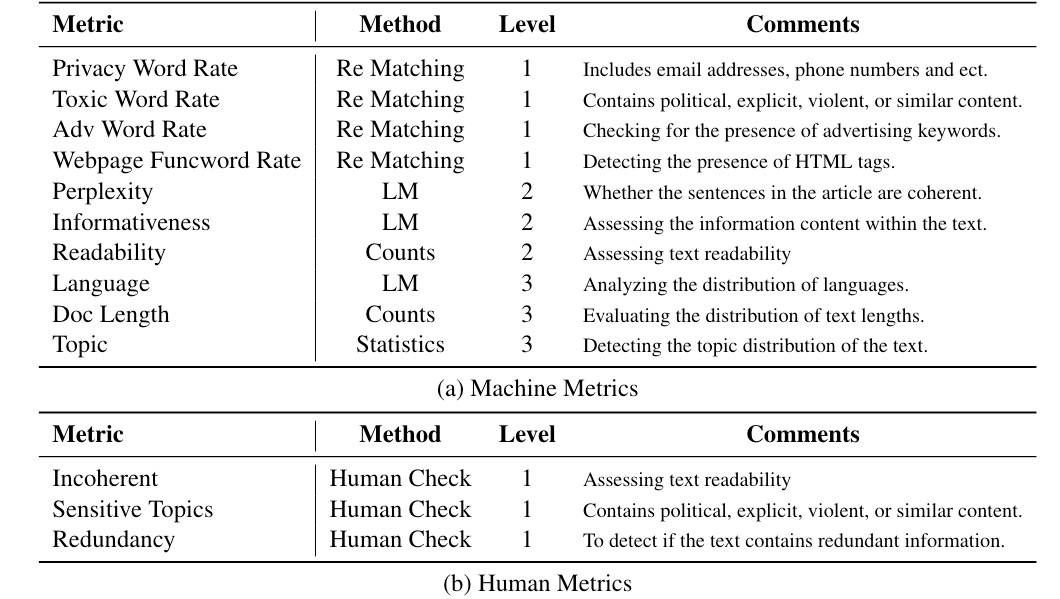
Level是级别,表示对相应指标应用的严格程度。不超过1‰(千分之一)就认为是合规的。
每一步处理完保留和过滤掉的数据情况如下图所示。
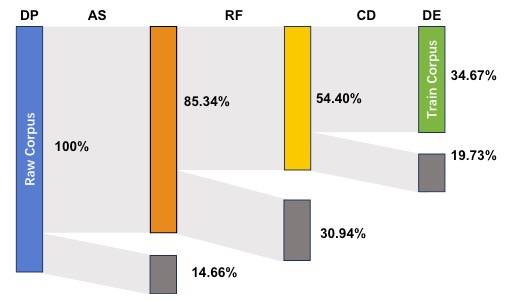
灰色部分是每一步过滤掉的数据,可以看到,最后数据只剩下1/3的样子。
数据分布
原始数据来自:Common Crawl、Wudao、Yuan1.0、Pile、Redpajama、Wanjuan、MetaMath以及自己收集的数据(代码和图书)。
原始数据13T,数据预处理完后得到4.5T,如下表所示。
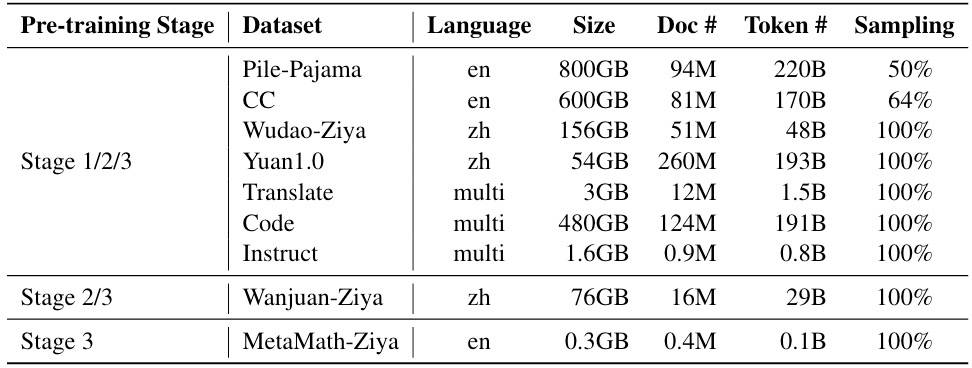
Sampling是指从原始数据集中抽取的数据的比率。
数据集信息如下。
- Pile-Pajama是删除Common Crawl数据后对Pile和Redpajama数据集进行去重合并。
- CC是源自Common Crawl的Pile和Redpajama数据的去重融合。
- Wudao-Ziya是一个将自己收集的数据与Wudao数据集相结合的数据集。
- Yuan1.0是浪潮科技提供的开源数据集,Ziya2使用清理规则对原始数据进行过滤。
- Translate是自己收集的多语言翻译数据集。
- Code是从GitHub收集的代码数据,其中包括C、C++和Python等多种编程语言。在代码之前添加程序语言类型,并将其更改为Markdown语法能够识别的格式。
- Instruct是根据自己收集的指令构建的数据集。
- Wanjuan-Ziya结合了来自Wanjuan数据集的高质量数据,以及自己收集的数学相关数据。
- MetaMath-Ziya是华为开源MetaMath数据集经过数据增强后衍生而来的数据集。
另外,为Instruct、WanjuanZiya和MetaMath-Ziya数据集构建了中英文的提示词,示例如下。
1 | # 中文监督数据 |
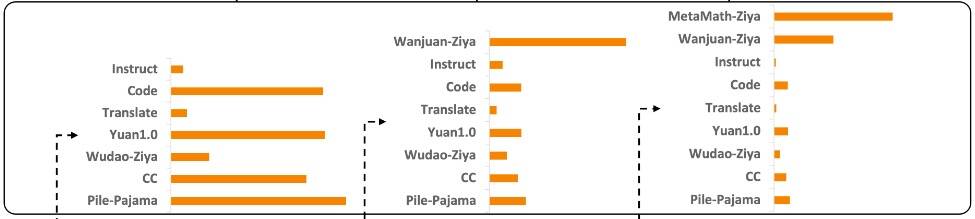
这些数据集主要用于二、三阶段预训练。
不同阶段训练数据分布如下图所示。
小结
Ziya2的标题是Data-centric Learning is All LLMs Need,重点讨论了继续训练和数据质量的重要性。数据质量的重要性早已经成为共识,我们不需要再强化这个认知了。但是怎么获取高质量数据,以及怎么调整数据集在预训练过程中的分布,相关的研究并不太多。Ziya2给出的方案看起来比较完整、通用,为我们提供了相关的经验。
另外,关于去重,有人可能会有疑问,为什么不用字面量的编辑距离,或者语义距离等。这个主要还是效率上的考虑,即使编辑距离相比SimHash(或MinHash)依然是极慢的。笔者在若干年前写过一个非常简单的相关库:hscspring/sto: MinHash and LSH Based Store and Query,感兴趣的读者可以查阅。
另外,关于SimHash和MinHash可以参考下面的资料。
- Near-Duplicate Detection - Moz
- 在茫茫人海中发现相似的你 —— 局部敏感哈希(LSH) - CodeMeals - 博客园
- Locality Sensitive Hashing (LSH): The Illustrated Guide | Pinecone
- 1e0ng/simhash: A Python Implementation of Simhash Algorithm
- ekzhu/datasketch: MinHash, LSH, LSH Forest, Weighted MinHash, HyperLogLog, HyperLogLog++, LSH Ensemble and HNSW