LLM的训练策略非常讲究,本文主要记录Ziya2的继续训练策略。
梗概
Ziya2主要关注继续训练,训练过程包括3个阶段:
- 阶段一: 在大量中英文高质量数据集上无监督LLM训练。
- 阶段二:有监督数据无监督训练。
- 阶段三:主要在数学数据上无监督训练。
如下图所示:
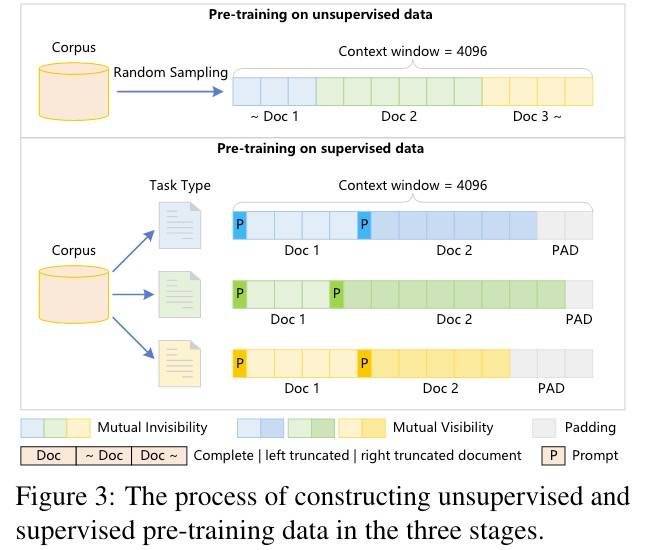
架构
Tokenizer
Tokenizer采用BPE Tokenizer,词表重用了原始LLaMA的600个,额外增加了7400个常用中文字符(同时包含简体和繁体中文,以及标点符号)。
原因是原始编码方式编码中文需要2-4个Tokenizer,比较低效,调整后大概提升了34%的编码和解码效率。
Position Embedding
依然是RoPE,不过观察到CT(Continual Training)数据集和原始LLaMA2的数据集的文本长度分布存在差异,因此需要根据数据分布调整位置编码(模型适配)。为了避免与混合精度相关的溢出问题,使用了 FP32。
LN 和 Attention
和上面同样的原因(分布不同导致的溢出),重新优化了LLaMA2的:
- LN 用了 APEX RMSNorm,可以在 FP32 下运行。
- Attention 使用融合运算符替换注意力模块中的缩放、掩码和Softmax运算符,加速计算(没看到代码)。同样为了防止溢出使用 FP32 训练。
继续训练
整体就是前面的三阶段,我们具体展开来看。
初始化
考虑到扩充了词表,对这些新Token,使用随机初始化。对那些在LLaMA2中已有的中文相关Token(2-4个构成一个汉字),直接加权平均作为中文字的Embedding。看个例子。
1 | from transformers import LlamaTokenizer |
29871是插入的空白字符,后面3个Token表示”谢“字。
其实,LLaMA2词表里还有一些中文是字符(也就是”字“)粒度的,虽然论文这里没说明,但一般情况下这些Token(一个Token就是一个汉字)都是直接复制原模型的Embedding。
训练策略
为了防止灾难性遗忘(调完中文,英文能力废了),分了三阶段继续训练。基本思路就是一开始的图,这里展开一些细节。
- 阶段一:
- 采样和LLaMA2接近的英文数据,从Wudao-Ziya和Yuan1.0采样中文数据,采样Code数据。
- 共650B,Shuffle后将不同的数据分割拼接成4096个Token一个样本(需要Mask防止不同的数据彼此影响)。
- 阶段二:
- 为了提升下游任务表现,使用中英文指令的有监督的数据,但并不是做指令微调,依然做无监督继续训练。
- 与阶段一不同的是,只有同类型指令的数据才会拼接成4096长度的样本,不够的用特殊Token Padding。
- 为了保留获得的知识,同时采样(与指令有监督数据)同比例的无监督中英文数据。
- 阶段三:
- 加入推理相关的有监督数据,比如Wanjuan-Ziya和MetaMath-Ziya。
- 数据混合方法和阶段二一样。
- 阶段三后,模型数学推理能力和编程能力得到显著提高。说明数学推理技能对需要推理的任务(如编程)至关重要。
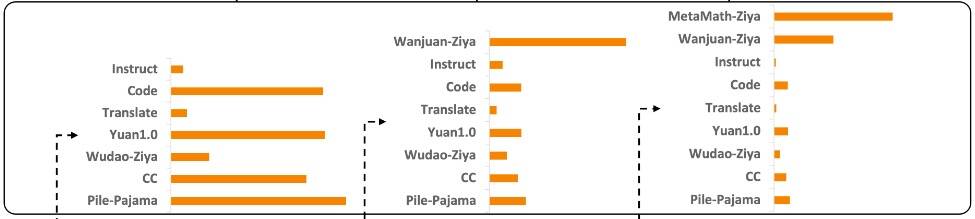
数据如下图所示。
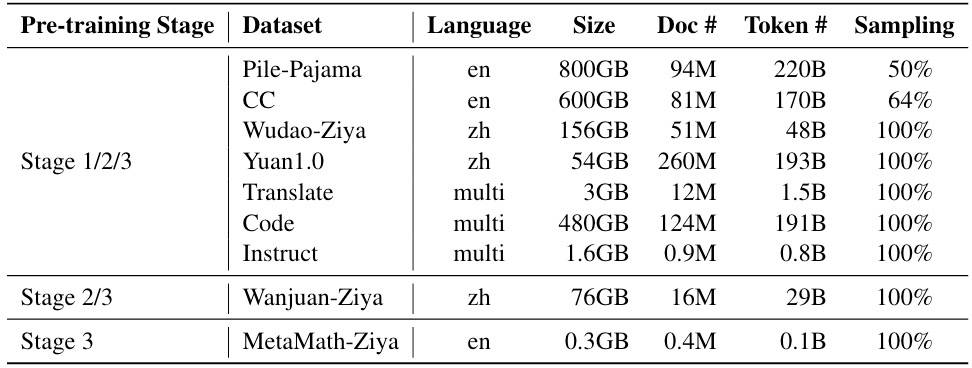
各个阶段的数据分布如下图所示。
优化器
AdamW,β1=0.9,β2=0.95。
由于数据集中加入了额外的中文和代码数据导致和原模型数据分布有差异,因此需要额外的Warmup。所以将LLaMA2的0.4%的Warmup比例调到了1%。
同时使用了cosine decay,学习率最后降到1e-5。
Weight decay设置为0.1,Gradient Clipping设置为1.0。
训练效率
使用Megatron+DeepSpeed,前者我们知道是3D并行框架,后者的ZeRO策略主要用于优化显存。
另外也用了Flash-Attention和Fused-Softmax提升训练效率。
训练稳定性
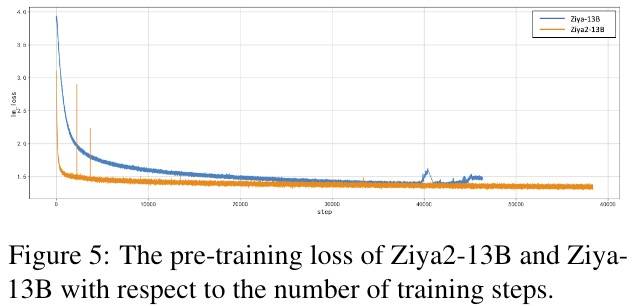
从Ziya-13B的FP16换成了BF16,保证收敛稳定性。
评测情况
Ziya2的评测方法是通用方法,即在多个Benchmark上跑分。Base是ChatGPT和7个开源模型,结果如下表所示。

MMLU和CMMLU是NLU相关测评,涵盖多个主题的问题。C-Eval是中文的各专业多选题。GSM8K是小学数学题。MATH是数学竞赛题,有详细的分步解决方案。HumanEval是根据提供的文档进行编程的题。
不说Base,光说和Ziya-13B的对比,确实提升非常明显。这除了归功于本文介绍到的各种优化,还有高质量的数据。效果如下图所示。
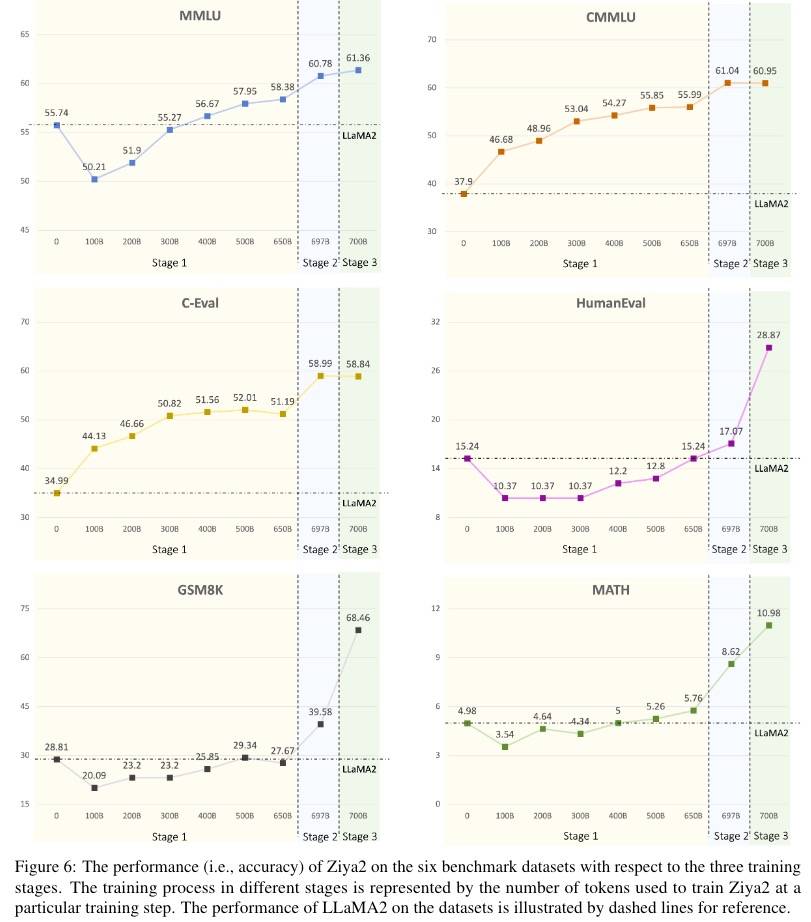
阶段一:MMLU在训练开始时分数下降是因为加入了大量中文数据,随着训练增加分数增加;同时中文分数得到极大提升(CMMLU和C-Eval)。
阶段二:在所有Benchmark上都有提升,尤其是C-Eval、GSM8K和MATH,说明加入监督数据能降低训练步数。
阶段三:GSM8K、MATH和HumanEval得到极大提升,同时通用任务上分数基本没变,说明特定任务数据能显著提高特定任务分数,但另一方面这种提高不一定有益,因为可能只是学习到了问题的格式,而不是真正的能力。
小结
本文主要介绍了Ziya2的继续训练,它的三阶段继续训练确实显著提高了模型表现。不过二阶段和三阶段数据的获取成本是比较高的,虽然用的是无监督方式训练,但其实算是有监督数据。这也许对特定领域的继续训练有参考意义。一阶段是英文能力的进一步增加和额外的中文能力,这和预训练的数据直接相关,看起来也比较符合直觉。总的来说,Ziya2的继续训练策略为继续训练这个方向提供了不少启示和经验。