NER 任务主要有三种类型:Flat(平铺)、overlapped(重叠或嵌套)、discontinuous(不连续),越来越多的研究致力于将它们统一起来。当前的 STOA 主要包括基于 Span 和 Seq2Seq 模型,不过它们很少关注边界,可能会导致后续的偏移。本文提出的统一方法(W2NER)是将其视为词词关系分类,为此引入两种词词关系:NNW(Next-Neighboring-Word)和 THW-*(Tail-Head-Word-*)。具体而言,构造一个 2D 的词词关系网格,然后使用多粒度 2D 卷积,以更好地细化网格表示。最后,使用一个共同预测器来推理词-词关系。
背景
针对多类型 NER,之前的工作主要可以概括为四种类型。
- 序列标注:BIO 及其变种
- Span:Span 级分类,MRC 任务
- Seq2Seq:生成方法
W2NER词词关系
大多数现有的 NER 工作主要考虑更准确的实体边界识别,不过在仔细重新思考了三种不同类型 NER 的共同特征后,作者发现统一 NER 的瓶颈更多在于实体词之间相邻关系的建模。这种邻接相关性本质上描述了部分文本片段之间的语义连通性,尤其对于重叠和不连续的部分起着关键作用。如下图 a 所示:

因此,本文提出了一种词-词关系分类的架构——W2NER,有效地对实体边界和实体词之间相邻关系进行建模。如下图所示:
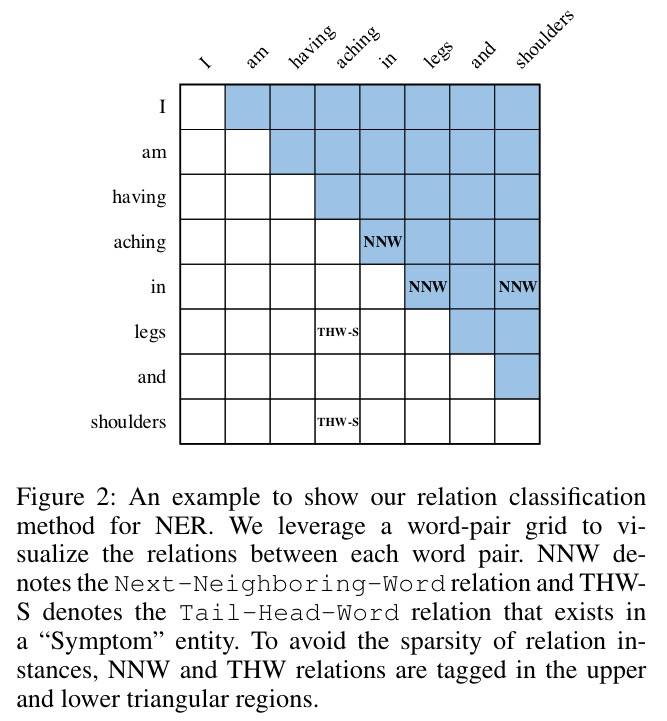
关系包括以下几种类型:
NONE:表示词对没有任何关系;NNW:词对属于一个实体 Mention,网格中行的 Token 在列中有一个连续的 Token;THW-*:THW 关系表示网格中行的 Token 是一个实体 Mention 的尾部,网格中列的 Token 是一个实体 Mention 的头部,*表示实体类型。
上图的例子中包含两个实体:aching in legs 和 aching in shoulders,可以通过 NNW 关系(aching→in)、(in→legs)和(in→shoulders)和 THW 关系(legs→aching,Symptom)和(shoulders→aching,Symptom)解码得出。
而且 NNW 和 THW 关系还暗示 NER 的其他影响,比如 NNW 关系将同一不连续的实体片段关联起来(如 aching in 和 shoulders),也有利于识别实体词(相邻的)和非实体词(不相邻的)。THW 关系有助于识别实体的边界。
模型架构
整体的网络架构如下图所示:
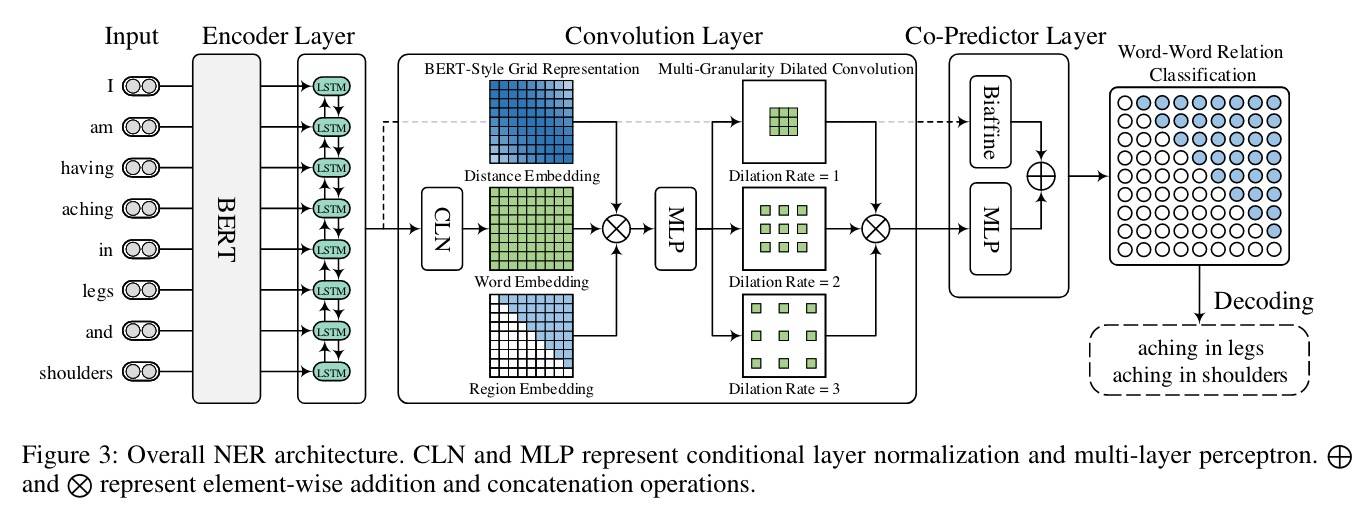
总的来看,首先 BERT 和 LSTM 提供上下文特征,然后一个词-词关系的 2D 网格被构建,接下来是一个多粒度 2D 卷积用来精调词对表示,有效捕获相邻或不相邻词对的交互。最后一个联合预测器对词-词关系进行推理并产生所有可能的实体 Mention,其中 Biaffine 和 MLP 被联合使用以获得互补好处。
输入
假设使用如下量句训练数据:
1 | inp = [ |
模型输入的构造比较复杂,主要包括下面几个部分:
-
模型输入:
-
BERT 的 Token。
-
Label 网格 Mask。
-
子词 Mask。
-
位置编码。
-
句子长度。
-
-
损失函数:
- Label 网格。
- Label 网格 Mask。
-
评估:
- 实体对应的 index 和实体类型的 id。
首先是 bert_inputs,它和正常使用 BERT Tokenizer 直接 encode 是一样的。注意英文会有子词,所以长度比单词数要多。
1 | # tokens(按空格分开后再执行 tokenize) |
接下来是 grid_labels,具体结果如下:
1 | # grid_labels Bx8x8 |
以论文中的例子(第一句)来说明,左上三角的三个 1 就表示 NNW,右下三角的 3 则表示 THW(就是对应的类型:CONT),是实体的尾部。具体代码如下:
1 | for entity in instance["ner"]: |
需要注意的是,shape 的大小是根据句子的长度(词数)来确定的,第一句话长度为 8,第二句为 6,所以第二句会 Padding。
下一个是 grid_mask2d,这个和 grid_labels 对应,将其中 Padding 的部分 Mask 住。
1 | # Bx8x8 |
接下来是 pieces2word,这个主要是针对子词的,中文一般一个 Token 就是一个字(词),英文可能几个 Token 合成一个词。因为我们在 NER 时并不是针对子词,而是针对一个个独立的词的,所以这块需要单独标记。
注意和前面的 tokens 结合起来看。另外需要注意,这里的首尾各增加了 BERT 的特殊标记。
1 | # 中文 |
当然,如果两句话在一个 Batch 中,Padding 也是必须的,Padding 部分会被 Mask 住。
再接下来是位置编码:dist_inputs,根据词对的相对距离设计了 20 个 Embedding,并根据前后顺序与距离的 2 进制(2**0, 2**1, 2**2, ...)进行分配。
1 | # Bx8x8 |
代码如下:
1 | dis2idx = np.zeros((1000)) |
相对位置最大相差 9,句子长度可达 2**10,不过代码中将其限制到了 1000。
下一个是句子长度,比较简单:
1 | tensor([8, 6]) |
最后是 entity_text,其实就是实体对应的 index 和实体类型的 id,这个用于评估。
1 | [{'3-4-5-#-3', '3-4-7-#-3'}, {'0-1-2-#-2'}] |
其实,输入中还少了一个(在模型内部实现)用来区分上下三角的 reg_inputs,它等于对 grid_mask 下三角 Mask 与 grid_mask 之和:
1 | tril_mask = torch.tril(grid_mask2d.clone().long()) |
具体实例如下:
1 | # tril_mask |
注意 reg_inputs 的值域是 {0, 1, 2},分别代表 Padding,上三角和下三角区域。
Encoder
将 Token 或词转为子词后喂入模型,子词表征通过 MaxPooling 得到词表征,同时额外的 Bi-LSTM 也被用来生成最终的词表征。也就是说输入的字符粒度 Token 需要转为词再送入后续模型(主要针对英文的子词)。
1 | bert_embs = self.bert(input_ids=bert_inputs, attention_mask=bert_inputs.ne(0).float()) |
Convolution
然后是卷积层,因为它能很好地处理二维关系,具体又包括三个模块:
- 一个包含归一化的 condition layer,用来生成词对表示;
- 一个 BERT 风格的网格表示来丰富词对表示;
- 一个多粒度扩张卷积来捕获远近词之间的交互;
条件层归一就是上图的 CLN 部分:
Vij 表示词对(xi,xj)的表示,可以看作 xi 和 xj 词表征(hi 和 hj)的组合,也意味着 xi 是 xj 的条件。hi 是获取层归一化参数 γ 和 λ 的条件,μ 和 σ 是 hj 的均值和标准差。
来自 Paper《Modulating Language Models with Emotions》
代码均来自官方,做了一定简化,后续不再重复说明。
1 | class LayerNorm(nn.Module): |
卷积网络如下:
1 | class ConvolutionLayer(nn.Module): |
网格表示主要引入三个张量分别表示:词信息(CLN)、每对词的相对位置信息和用于区分网格上下三角的区域信息。三个张量拼接后丢给后面的层进行降维和混合信息,以此得到网格「位置-区域敏感的表示」。然后是接一个多粒度卷积(粒度=1,2,3),用以捕获不同距离词的交互。最后将三组结果拼起来就是最终的词对网格表示。
大致流程如下:
1 | self.cln = LayerNorm(config.lstm_hid_size, config.lstm_hid_size, conditional=True) |
Co-Predictor
这一步除了 MLP 外,还有一个 Biaffine Predictor,所以会分别得到两个结果,然后合并后作为最后输出。
s 和 o 分别表示主语和宾语。s 和 o 的输入就是前面的词表征(而不是卷积),卷积这部分特征被丢给了 Biaffine。代码如下:
1 | class Biaffine(nn.Module): |
Decoding
模型预测的是词和它们的关系,可以看作有向图,解码目标是使用 NNW 关系在图中查找从一个单词到另一个单词的某些路径。每个路径对应于一个实体 Mention。除了 NER 的类型和边界标识外,THW 关系还可以用作消除歧义的辅助信息。

如上图所示几个例子:
- a:两个路径对应平铺的实体,THW 关系表示边界和类型。
- b:如果没有 THW 关系,则只能找到一条路径(ABC),借助 THW 可以找到嵌套的 BC。
- c:包含两条路径:ABC 和 ABD,NNW 关系有助于连接不连续的跨度 AB 和 D。
- d:如果只使用 THW 关系,将会识别到 ABCD 和 BCDE,如果只使用 NNW 则会找到四条路径,结合起来才能识别到正确的实体:ACD 和 BCE。
目标函数
如下式所示:
N 表示句子中词数,y^ 是二元向量表示词对的真实关系 Label,y 是预测的概率,r 表示预先定义的关系集合中的第 r 个关系。可以看出,整个就是个词对分类问题。
结果
共 14 个数据集,包括平铺的、重叠的和不连续的。Baseline 包括常用的几种方法(前文介绍过)。
平铺NER
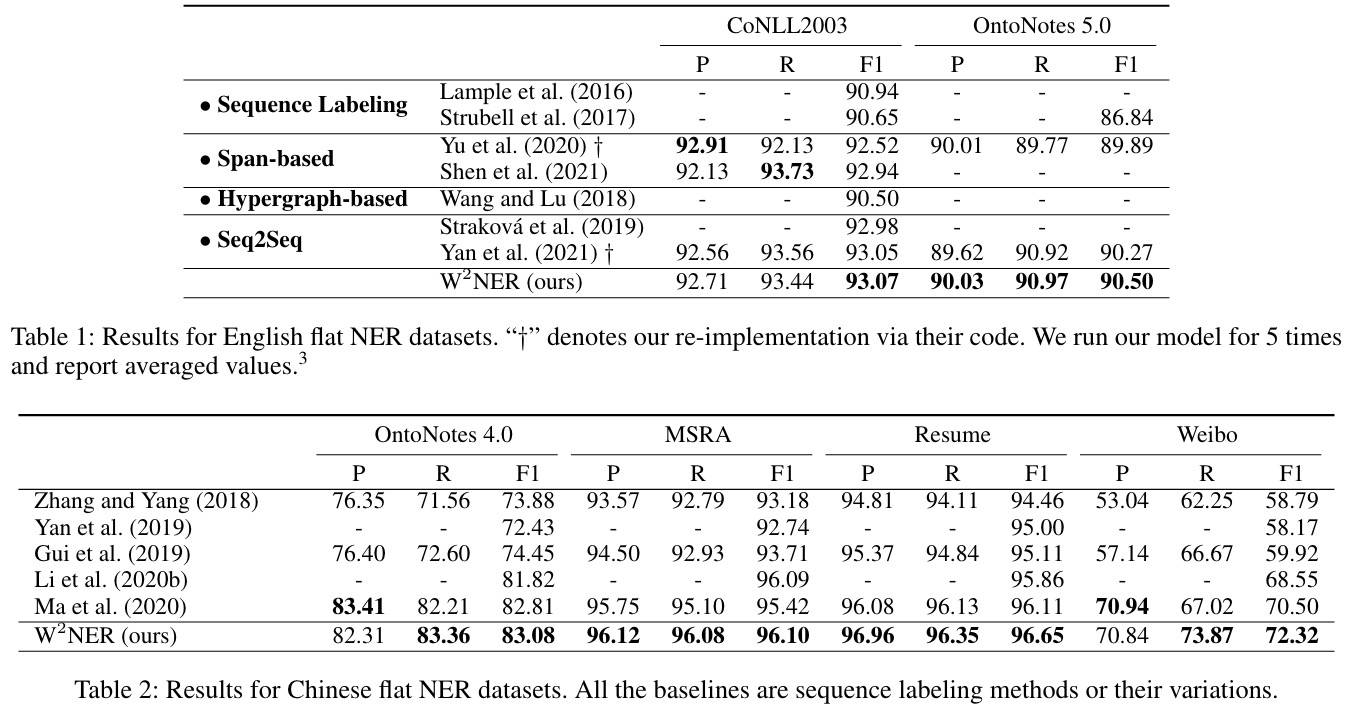
在中英文数据集均取得不错的效果。
重叠NER
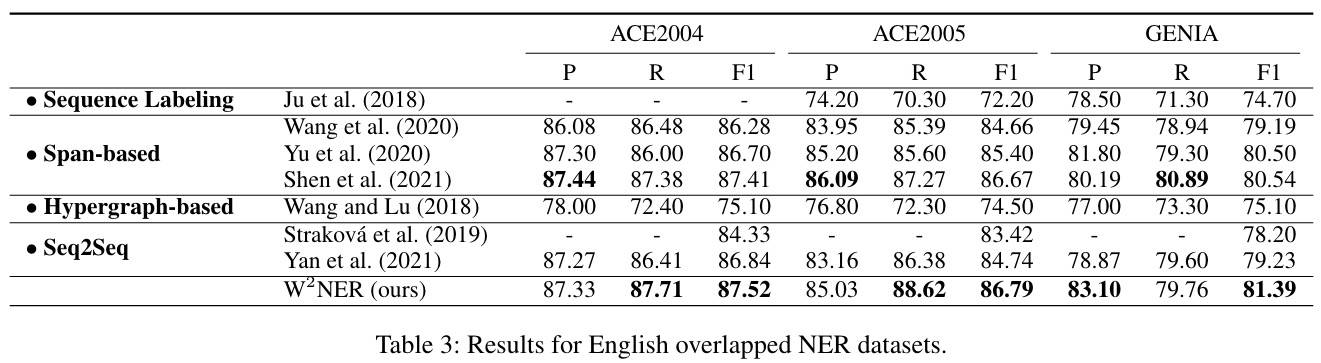
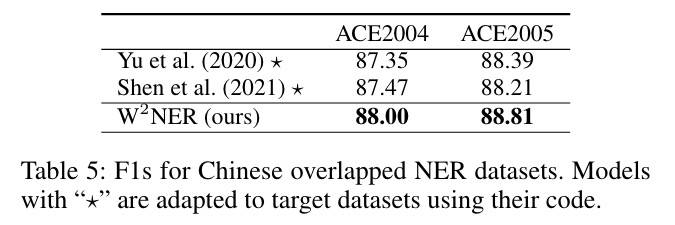
通过上面的结果可以发现,除了本文的方法,其实基于 Span 的方法也是效果不错的。
不连续NER
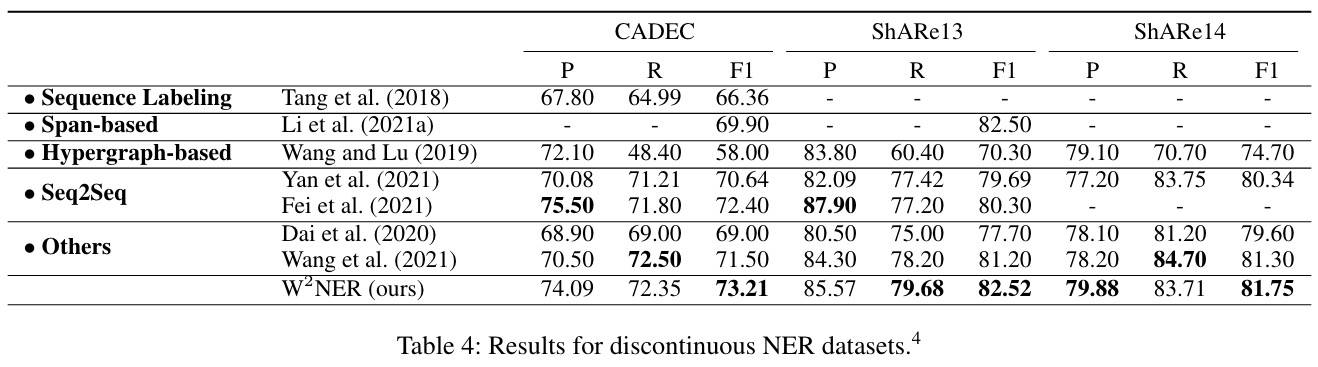
此外,考虑到后面两种情况中也包含了平铺 NER,所以,也评估了只有重叠和不连续 NER 的效果:

这下效果明显了,尤其是不连续 NER,效果好出一大截。
消融
结果如下图所示:
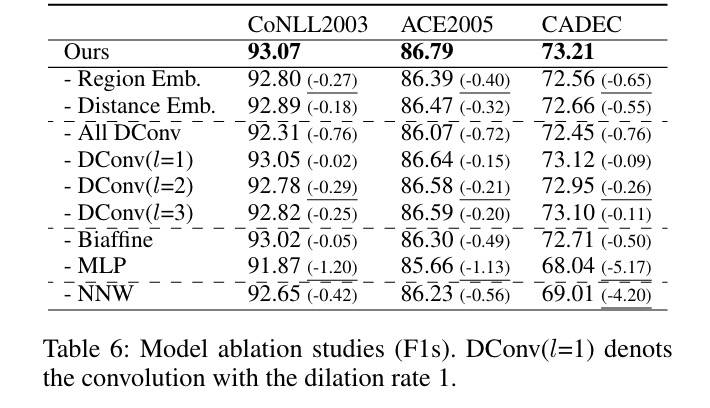
列出比较重要的因素:
- NNW:尤其对不连续 NER 效果明显(CADEC 数据集)
- MLP:主导作用
- DConv(L=2)
- Region Emb
小结
本文基于词-词关系分类,提出一个统一的实体框架 W2NER,关系包括 NNW 和 THW。框架在面对各种不同的 NER 时非常有效。另外,通过消融实验,发现以卷积为中心的模型表现良好,其他几个模块(网格表示和共同预测器)也是有效的。总的来说,本文更加关注边界词和内部词之间的关系,另外 2D 网格标记方法也可以大大避免 Span 和序列标注模型中的缺点。