一句话描述:多任务 Prompt 可以明确影响 Zero-shot 学习。
论文:[2110.08207] Multitask Prompted Training Enables Zero-Shot Task Generalization
Code:bigscience-workshop/promptsource: Toolkit for collecting and applying prompts
摘要:大语言模型显示出可观的 Zero-shot 泛化能力,被假设成是语言模型中多任务训练暗含的结果,所以这个能力能不能体现的直接点?本文使用一大堆有监督数据集,每个又有多个不同自然语言的 prompt,通过微调一个预训练的 Encoder-Decoder 模型,取得不错的 Zero-shot 性能。真可谓是大数据集、大 prompt 出奇迹。
背景
近年来的工作显示,语言模型虽然用语言模型的目标训练的,但在没训练过的新任务上表现出了不错的泛化能力。有影响力的假设是说,这是多任务学习隐式处理的结果。问题是,到底有多含蓄?本文就 focus 在以监督和大规模多任务的方式有意和明确地训练大型语言模型。主要研究两个问题:
- 多任务提示训练能否提升泛化性?答案自然是能,太能了。
- 广泛的提示训练能否提升鲁棒性?每个数据集上更多的 prompt 提升性能且更加稳定,基于 prompt 更多的数据集也能提升性能但不能减少可变性。
已有的一些研究:
- 多任务一次训练
- 简单的 Prompt 模板
- Prompt 作为通用方法:
- 主流:作为说明
- 本文:聚焦 Zero-shot 泛化
- 对 prompt 成功的解释:
- 主流:学习理解作为任务说明的 prompt,这有助于模型泛化
- 本文:Prompt 作为木任务训练的自然语言格式经验上有助于模型泛化
泛化测量
四类任务:
- 推理
- 句子补全
- 词义消歧
- 共指解析
推理作为 held-out 任务,因为人类能够 Zero-shot 到这样的任务上,类似基于三段式那样。`

统一的Prompt格式
定义一个包含输入模板、目标模板和一组相关 meta 信息的 prompt。

Prompt 是社区开源编写的,来自 24 个地区和 8 个国家的 36 位贡献者。要求如下:
- 用自己的风格创造出多样的 prompt
- Prompt 应当语法正确,且能够被英语为母语的无相关任务经验人理解
- 需要明确计数或数字索引的将稍作改变,比如抽取式 QA 的 span,模型将会预测 span 的文本
实验
模型
在多任务训练+prompt 的数据集上微调一个预训练模型,模型使用 Encoder-Decoder 架构(T5),Encoder 输入,Decoder 通过极大似然法自回归生成目标。使用开源的 T5 模型作为【T5+LM】,如下。
Brian Lester, Rami Al-Rfou, and Noah Constant. The power of scale for parameter-efficient prompt
tuning. CoRR, abs/2104.08691, 2021.
训练
三个模型:
- T0:主模型(11B 和 3B)
- T0+:增加 GPT-3 评估数据集
- T0++:增加 GPT-3 和 SuperGLUE 数据集
所有的数据样本放在一起 shuffle,因为不同数据集样本数量不同,对超过 500000 样本的使用 500000/num_templates 个作为采样样本,num_templates 是为该数据集创建的模板数量。多个样本被 pack 成一个单独的序列以达到最大长度(1024 输入,256 输出)。BatchSize=1024,Adafactor 优化器,LearningRate=1e-3,Dropout=0.1。
评估
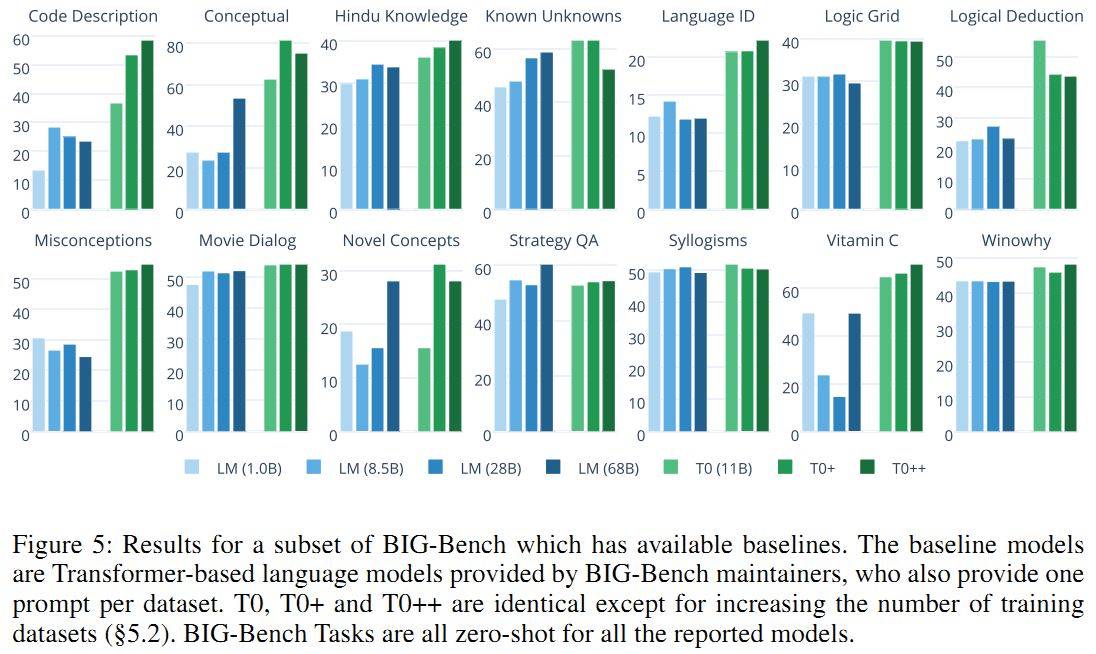
如前所述,主要在四个任务上进行评估,共 11 个数据集。同时也在 BIG-Bench 的 14 个数据集上进行了评估。
- 对于涉及选择正确的补全(如多选),使用 rank scoring,即计算每个目标的最大似然然后选择分数最高的。
- 对 log 似然不使用任何归一化策略。
- 每个数据集都报告精准率。
- 不在验证集做 prompt 选择的性能对比,因为可能会导致信息泄露。
- 对每个数据集,报告不同 prompt 结果的中位数,以及分位数区间(Q3-Q1),用来评估模型对 prompt 措辞的敏感度。
结果
泛化能力
- T0 在 8/11 的任务(所有的 NLI)上超过 GPT-3
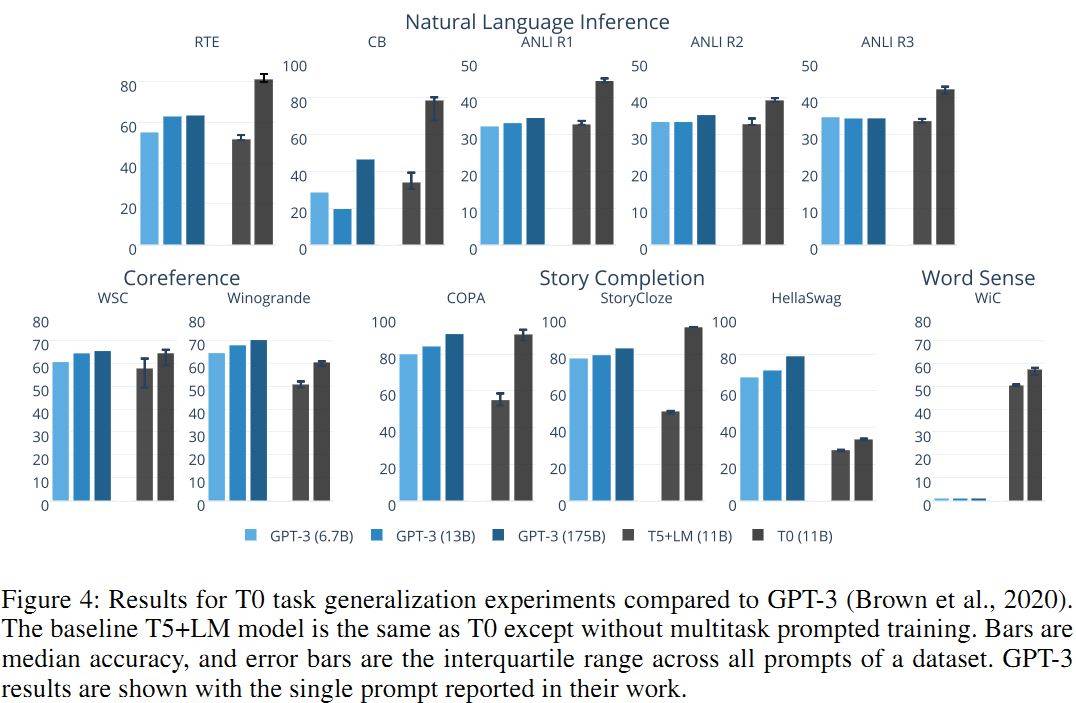
- 至少一个 T0 的变种超过了除 StrategyQA 外的所有 baseline,且大部分情况下训练集增加时效果增加
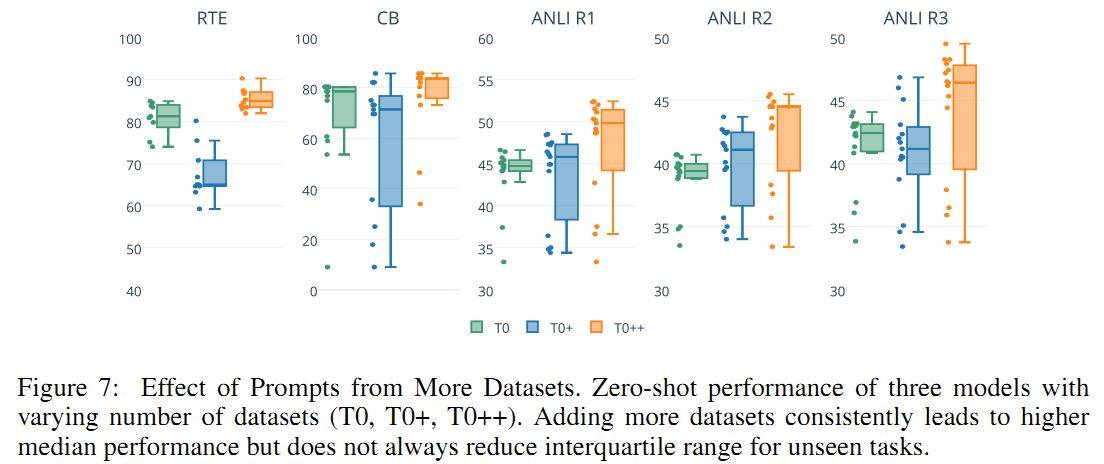
Prompt 鲁棒性
两个消融实验:
- 单数据集 prompt 数量:即便每个数据集只有一个 prompt,泛化能力也相当可观;继续增加 prompt 可以带来更多提升。

- 数据集的数量:每个数据集使用所有的 prompt。增加数据集并不能一直让模型对 prompt 的表达更鲁棒。
讨论
之前已有两个比较相似的工作,分别是 OpenAI 的 “instruct series”,另一个是 FLAN。值得一提的是(其实就一个点)FLAN 作者发现多任务训练后在 held-out 任务上性能会下降。本文结果与此相反,相关解释如下(以下均为 FLAN 与本文的对比):
- 使用 Encoder-Decoder 架构,在多任务上微调前,作为预训练模型包含了 MLM 目标,MLM 已经被证实是更有效的预训练策略。
- Prompt 在长度和创造性方面上更加多样,而多样就有效果。
- 一次多个任务,而不是一次单个任务。