Introduction
本篇文章主要介绍如何使用 Tensorbay 和 Tensorflow 进行简单的文本分类。
我们首先介绍 Tensorbay 相关使用,然后简单介绍 NLP 领域常用的分类模型:TextCNN,最后将所有的串起来完成一个简单的文本分类任务。
TensorBay
TensorBay 是什么?借用官方的介绍:
作为非结构化数据管理专家,TensorBay 提供数据托管、复杂数据版本管理、在线数据可视化和数据协作等服务。 TensorBay 的统一权限管理,让您的数据共享和协同使用更加安全。
简单来说,它提供了统一的数据集管理方案。官方提供了 Python SDK,用于:
通过 Pythonic 的方式访问数据资源
易于使用的 CLI 工具
统一的数据集结构
1 2 3 4 5 6 7 8 9 10 from tensorbay import GASfrom tensorbay.dataset import Segmentfrom tensorbay.dataset import Dataset as TensorBayDatasetfrom tensorbay.dataset import Notesfrom tensorbay.opendataset import Newsgroups20
GAS
首先,需要在官方网站注册一个账号:https://gas.graviti.cn/tensorbay/
登陆后,在【开发者工具】里面的【AccessKey】中新建一个 Key,就可以用于连接 TensorBay 了。
创建 GAS 后,之后的操作就都基于该账号进行。
1 2 access_key = "<YOUR_ACCESS_KEY>" gas = GAS(access_key)
TensorBayDataset
一般会在此定义数据集,当然官方也内置了一些数据集。数据集结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 dataset ├── notes ├── catalog │ ├── subcatalog │ ├── subcatalog │ └── ... ├── segment │ ├── data │ ├── data │ └── ... ├── segment │ ├── data │ ├── data │ └── ... └── ...
dataset:最顶层的概念,每个数据集包括一个目录和一些 Segment,对应的 class 是 Dataset
notes:包含一个数据集的基本信息,对应的 class 是 Notes,包括:
数据集中数据的时间连续性
数据集中的 bin 点云文件的字段
catalog:用于存储标签元信息,它收集与数据集对应的所有标签,一个目录下可以有一个或多个子目录(标签格式),每个子目录只存储一种标签类型的标签元信息,包括对应的注解是否有跟踪信息。注意:如果没有标签信息,则不需要 catalog
以 BSTLD 数据集(Box2D 为 label)为例,它的 catalog 如下所示:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 { "BOX2D" : { "categories" : [ { "name" : "Red" } , { "name" : "RedLeft" } , { "name" : "RedRight" } , { "name" : "RedStraight" } , { "name" : "RedStraightLeft" } , { "name" : "Green" } , { "name" : "GreenLeft" } , { "name" : "GreenRight" } , { "name" : "GreenStraight" } , { "name" : "GreenStraightLeft" } , { "name" : "GreenStraigntRight" } , { "name" : "Yellow" } , { "name" : "off" } ] , "attributes" : [ { "name" : "occluded" , "type" : "boolean" } ] } }
segment:数据集的不同部分,每个部分存在一个 Segment 中,比如训练集、测试集,对应的 class 是 Segment
data:一个 Data 包含一个数据集样本和对应的标签,以及其他任何信息(如时间戳),对应的 class 是 Data
公开数据集
在 TensorBay 公开数据集平台找到想要的数据集,然后 fork。
1 2 3 4 5 6 7 8 9 10 11 12 news = TensorBayDataset("Newsgroups20" , gas) news """ Dataset("Newsgroups20") [ Segment("20_newsgroups") [...], Segment("20news-18828") [...], Segment("20news-bydate-test") [...], Segment("20news-bydate-train") [...] ] """
四个 Segment 分别表示:
20_newsgroups:Ver1.0,原始的 20 Newsgroups 数据集20news-bydate-*:Ver2.0,根据 date 排序,并删除了重复项和一些标题20news-18828:Ver3.0,只包括发件人和主题两个标题
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 news.catalog.classification.categories """ NameList [ CategoryInfo("alt.atheism"), CategoryInfo("comp.graphics"), CategoryInfo("comp.os.ms-windows.misc"), CategoryInfo("comp.sys.ibm.pc.hardware"), CategoryInfo("comp.sys.mac.hardware"), CategoryInfo("comp.windows.x"), CategoryInfo("misc.forsale"), CategoryInfo("rec.autos"), CategoryInfo("rec.motorcycles"), CategoryInfo("rec.sport.baseball"), CategoryInfo("rec.sport.hockey"), CategoryInfo("sci.crypt"), CategoryInfo("sci.electronics"), CategoryInfo("sci.med"), ... (5 items are folded), CategoryInfo("talk.religion.misc") ] """
本地数据集
或者,也可以使用自定义的数据集,比如我们把 20news-18828 数据集下载到本地:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 tree . -L 2 . └── 20news-18828 ├── alt.atheism ├── comp.graphics ├── comp.os.ms-windows.misc ├── comp.sys.ibm.pc.hardware ├── comp.sys.mac.hardware ├── comp.windows.x ├── misc.forsale ├── rec.autos ├── rec.motorcycles ├── rec.sport.baseball ├── rec.sport.hockey ├── sci.crypt ├── sci.electronics ├── sci.med ├── sci.space ├── soc.religion.christian ├── talk.politics.guns ├── talk.politics.mideast ├── talk.politics.misc └── talk.religion.misc 21 directories, 0 files
正好 20 个类别。
1 2 !head -20 data/20news-18828 /talk.religion.misc/84277
From: bd@fluent@dartmouth.EDU (Brice Dowaliby)
Subject: Re: Who's next? Mormons and Jews?
dic5340@hertz.njit.edu (David Charlap) writes:
>Someone in the government actually believed Koresh knew the "seven
>seals of the apocalypse", and ordered the invasion so that they'd all
>be dead and unable to talk about them in public.
Everything we need to know about the seven seals is already
in the bible. There is no "knowledge" of the seals that
Koresh could have.
Unless the FBI were to kill all publishers of the bible, it
would seem the story of the seven seals would be bound to
leak out.
Assuming for the moment that the FBI believed in the bible and
were afraid of the seven seals, then they would also know
that God is the one who has to open the seals, not some
1 2 3 4 5 6 7 8 ds = Newsgroups20("./data/" ) ds """ Dataset("Newsgroups20") [ Segment("20news-18828") [...] ] """
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 ds.catalog.classification.categories """ NameList [ CategoryInfo("alt.atheism"), CategoryInfo("comp.graphics"), CategoryInfo("comp.os.ms-windows.misc"), CategoryInfo("comp.sys.ibm.pc.hardware"), CategoryInfo("comp.sys.mac.hardware"), CategoryInfo("comp.windows.x"), CategoryInfo("misc.forsale"), CategoryInfo("rec.autos"), CategoryInfo("rec.motorcycles"), CategoryInfo("rec.sport.baseball"), CategoryInfo("rec.sport.hockey"), CategoryInfo("sci.crypt"), CategoryInfo("sci.electronics"), CategoryInfo("sci.med"), ... (5 items are folded), CategoryInfo("talk.religion.misc") ] """
这里,只需要将数据集按指定的格式和目录放置即可,要求如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 <path> 20news-18828/ alt.atheism/ 49960 51060 51119 51120 ... comp.graphics/ comp.os.ms-windows.misc/ comp.sys.ibm.pc.hardware/ comp.sys.mac.hardware/ comp.windows.x/ misc.forsale/ rec.autos/ rec.motorcycles/ rec.sport.baseball/ rec.sport.hockey/ sci.crypt/ sci.electronics/ sci.med/ sci.space/ soc.religion.christian/ talk.politics.guns/ talk.politics.mideast/ talk.politics.misc/ talk.religion.misc/ 20news-bydate-test/ 20news-bydate-train/ 20_newsgroups/
Segment
Segment 是数据集的不同部分
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 seg_name = "20news-18828" dataset_client = gas.get_dataset("Newsgroups20" ) segment = Segment(seg_name, dataset_client) segment """ Segment("20news-18828") [ RemoteData("alt.atheism_49960.txt")(...), RemoteData("alt.atheism_51060.txt")(...), RemoteData("alt.atheism_51119.txt")(...), RemoteData("alt.atheism_51120.txt")(...), RemoteData("alt.atheism_51121.txt")(...), RemoteData("alt.atheism_51122.txt")(...), RemoteData("alt.atheism_51123.txt")(...), RemoteData("alt.atheism_51124.txt")(...), RemoteData("alt.atheism_51125.txt")(...), RemoteData("alt.atheism_51126.txt")(...), RemoteData("alt.atheism_51127.txt")(...), RemoteData("alt.atheism_51128.txt")(...), RemoteData("alt.atheism_51130.txt")(...), RemoteData("alt.atheism_51131.txt")(...), ... (18813 items are folded), RemoteData("talk.religion.misc_84570.txt")(...) ] """ segment[0 ] """ RemoteData("alt.atheism_49960.txt")( (label): Label( (classification): Classification( (category): 'alt.atheism' ) ) ) """ seg = ds["20news-18828" ] seg[0 ] """ Data("/path/to/data/20news-18828/alt.atheism/49960")( (label): Label( (classification): Classification( (category): 'alt.atheism' ) ) ) """
Data
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 ele = seg[0 ] type (ele) ele.label """ Label( (classification): Classification( (category): 'alt.atheism' ) ) """ ele.open ().read()[:500 ] """ b'From: mathew <mathew@mantis.co.uk>\nSubject: Alt.Atheism FAQ: Atheist Resources\n\nArchive-name: atheism/resources\nAlt-atheism-archive-name: resources\nLast-modified: 11 December 1992\nVersion: 1.0\n\n Atheist Resources\n\n Addresses of Atheist Organizations\n\n USA\n\nFREEDOM FROM RELIGION FOUNDATION\n\nDarwin fish bumper stickers and assorted other atheist paraphernalia are\navailable from the Freedom From Religion Foundatio' """ i = 0 for v in seg: i += 1 pass i type (v)
TextCNN
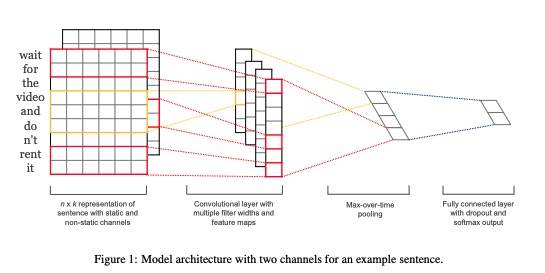
TextCNN 是 CNN 的 NLP 版本,来自 Kim 的 [1408.5882] Convolutional Neural Networks for Sentence Classification
结构如下:
大致原理是使用多个不同大小的 filter(也叫 kernel) 对文本进行特征提取,如上图所示:
首先通过 Embedding 将输入的句子映射为一个 n_seq * embed_size 大小的张量(实际中一般还会有 batch_size)
使用 (filter_size, embed_size) 大小的 filter 在输入句子序列上平滑移动,这里使用不同的 padding 策略,会得到不同 size 的输出
由于有 num_filters 个输出通道,所以上面的输出会有 num_filters 个
使用 Max Pooling 或 Average Pooling,沿着序列方向得到结果,最终每个 filter 的输出 size 为 num_filters
将不同 filter 的输出拼接后展开,作为句子的表征
1 from tensorflow import keras as tfk
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def text_cnn (config, inputs ): embed = tfk.layers.Embedding( config.vocab_size, config.embed_size, input_length=config.max_len)(inputs) embed = embed[:, :, :, None ] pool_outputs = [] for filter_size in map (int , config.filter_sizes.split(',' )): conv = tfk.layers.Conv2D( config.num_filters, kernel_size=(filter_size, config.embed_size), strides=(1 , 1 ), padding='valid' , activation="relu" , )(embed) pool = tfk.layers.MaxPool2D( pool_size=(config.max_len - filter_size + 1 , 1 ), strides=(1 , 1 ), padding='valid' )(conv) pool_outputs.append(pool) z = tfk.layers.concatenate(pool_outputs, axis=-1 ) z = tf.squeeze(z, [1 , 2 ]) z = tfk.layers.Dropout(config.dropout)(z) return z
1 2 3 4 5 6 7 8 9 10 11 import tensorflow as tffrom pnlp import Dict config = Dict ({ "vocab_size" : 21128 , "embed_size" : 256 , "max_len" : 512 , "num_filters" : 128 , "filter_sizes" : "2,3,4" , "dropout" : 0.1 , "num_classes" : 20 })
1 2 z = text_cnn(config, tf.constant([[1 ]*512 ])) z.shape
AllTogether
1 2 3 4 5 6 7 8 9 import numpy as npfrom typing import Union import tensorflow as tfimport mathimport pnlpfrom tensorflow.data import Datasetfrom transformers import AutoTokenizer
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class NewsGroupSegment : def __init__ ( self, client: Union [str , GAS], segment_name: str , tokenizer_path: str , label_file: str , max_length: int = 512 ): if isinstance (client, GAS): self .dataset = TensorBayDataset("Newsgroups20" , client) elif isinstance (client, str ): self .dataset = Newsgroups20(client) else : raise ValueError("Invalid dataset client" ) self .segment = self .dataset[segment_name] self .max_length = max_length self .tokenizer = AutoTokenizer.from_pretrained(tokenizer_path) labels = pnlp.read_lines(label_file) self .category_to_index = dict (zip (labels, range (len (labels)))) def __call__ (self ): for data in self .segment: with data.open () as fp: txt = fp.read().decode("utf8" , errors="ignore" ) ids = self .tokenizer.encode( txt, max_length=self .max_length, truncation=True , padding="max_length" ) input_tensor = tf.convert_to_tensor(np.array(ids), dtype=tf.int32) category = self .category_to_index[data.label.classification.category] category_tensor = tf.convert_to_tensor(category, dtype=tf.int32) yield input_tensor, category_tensor
1 2 3 4 5 6 def build_model (config, module ): inputs = tfk.Input(shape=(config.max_len, )) z = module(config, inputs) outputs = tfk.layers.Dense(config.num_classes, activation='softmax' )(z) model = tfk.Model(inputs=inputs, outputs=outputs) return model
1 2 3 4 5 6 7 model = build_model(config, text_cnn) model.compile ( optimizer=tfk.optimizers.Adamax(learning_rate=1e-3 ), loss=tfk.losses.SparseCategoricalCrossentropy(), metrics=[tfk.metrics.SparseCategoricalAccuracy()], )
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 max_len = 512 batch_size = 32 segment_name = "20news-18828" client = "./data/" data = NewsGroupSegment(client, segment_name, "./bert/" , "labels.txt" , max_len) epochs = 10 steps_per_epoch = math.ceil(len (data.segment) / batch_size) dataset = Dataset.from_generator( data, output_signature=( tf.TensorSpec(shape=(max_len, ), dtype=tf.float32), tf.TensorSpec(shape=(), dtype=tf.int32), ), ).shuffle(buffer_size=len (data.segment), reshuffle_each_iteration=True ).batch(batch_size).repeat(epochs)
根目录如下:
1 2 3 4 5 6 7 8 tree . -L 2 . ├── bert │ ├── config.json │ └── vocab.txt ├── data │ └── 20news-18828 ├── labels.txt
1 model.fit(dataset, epochs=epochs, steps_per_epoch=steps_per_epoch)
Epoch 1/10
589/589 [==============================] - 391s 564ms/step - loss: 2.3371 - sparse_categorical_accuracy: 0.3687
Epoch 2/10
589/589 [==============================] - 411s 592ms/step - loss: 1.2920 - sparse_categorical_accuracy: 0.6325
Epoch 3/10
589/589 [==============================] - 480s 709ms/step - loss: 0.9563 - sparse_categorical_accuracy: 0.7256
Epoch 4/10
589/589 [==============================] - 490s 737ms/step - loss: 0.7665 - sparse_categorical_accuracy: 0.7844
Epoch 5/10
589/589 [==============================] - 547s 836ms/step - loss: 0.6326 - sparse_categorical_accuracy: 0.8221
Epoch 6/10
589/589 [==============================] - 368s 522ms/step - loss: 0.5288 - sparse_categorical_accuracy: 0.8528
Epoch 7/10
589/589 [==============================] - 435s 625ms/step - loss: 0.4422 - sparse_categorical_accuracy: 0.8812
Epoch 8/10
589/589 [==============================] - 494s 706ms/step - loss: 0.3728 - sparse_categorical_accuracy: 0.9026
Epoch 9/10
589/589 [==============================] - 679s 1s/step - loss: 0.3131 - sparse_categorical_accuracy: 0.9152
Epoch 10/10
589/589 [==============================] - 676s 976ms/step - loss: 0.2641 - sparse_categorical_accuracy: 0.9348
需要注意:
数据集文件或 Segment 无法 shuffle 的,可以加载后 shuffle
数据加载比较慢,尤其是在线加载,可以先把文件 Load 到本地
Summary
本文我们借助 TensorBay,使用 TextCNN 完成了简单的文本分类任务。TensorBay 本身并没有什么黑魔法,只是提供了一个统一管理数据的视角和工具,借助该工具,我们可以方便快捷地管理和使用数据集。
本文使用 Tensorflow 为例进行说明,TensorBay 也支持 PyTorch,使用方法大同小异,具体可以参考文档。
Reference