论文:[2106.14448] R-Drop: Regularized Dropout for Neural Networks
Code:dropreg/R-Drop
一句话概述:用 KL 散度作为损失的 SimCSE。
摘要:Dropout 是深度学习训练时广泛使用的正则化工具,本文提出 R-Drop,强迫不同 Dropout 模型(就是带 Dropout 的模型跑两次数据)的输出分布彼此保持一致。具体通过最小化两个输出的双向 KL 散度,R-Drop 降低了模型参数的自由度并补充了 Dropout,从而降低了模型的空间复杂度,增强了泛化能力。效果那自然也是非常不错的。
简介
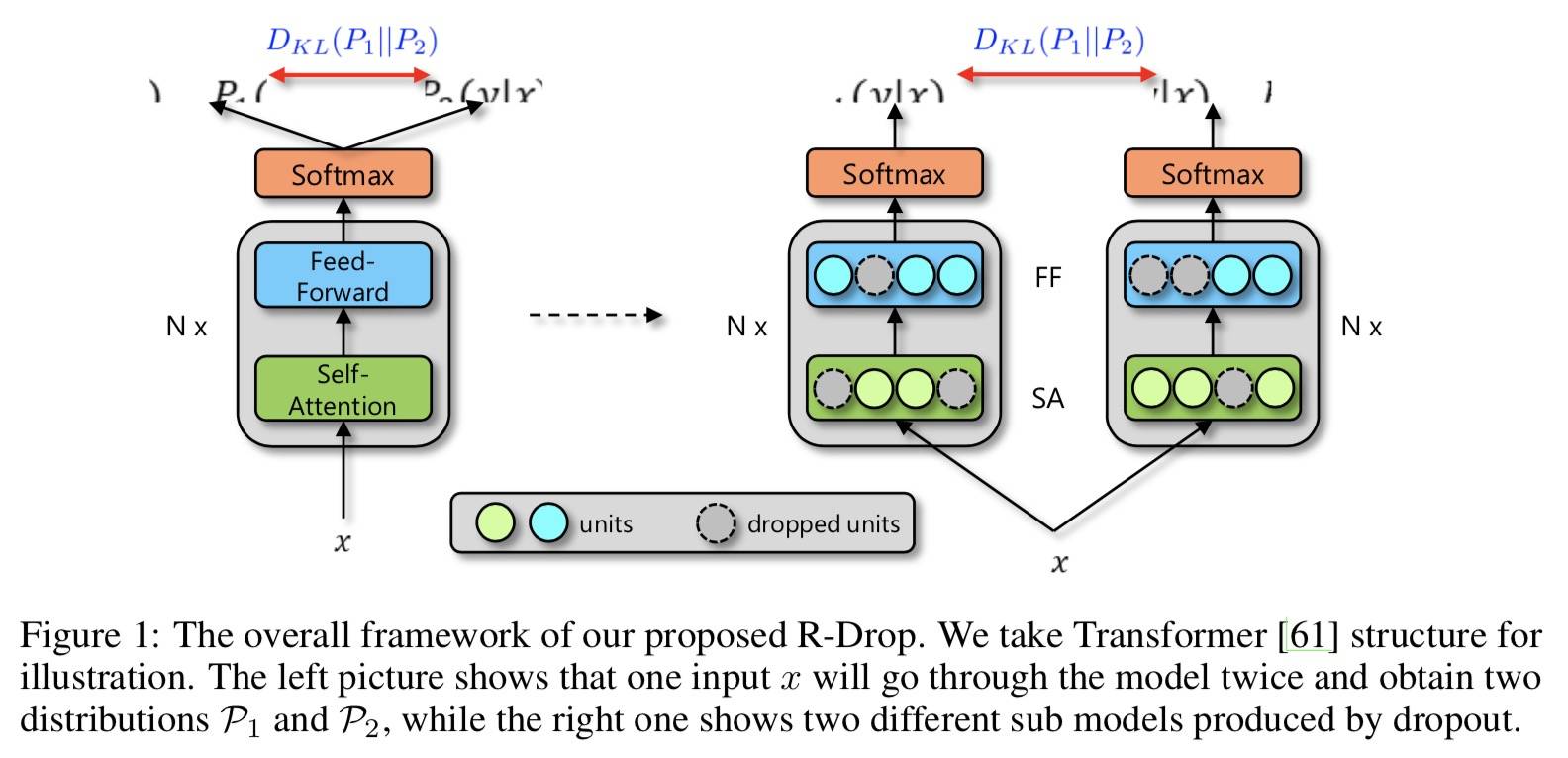
- 提出一种基于 Dropout 的简单有效的正则化方法,可以普遍应用于训练不同类型的深度模型。具体就是增加一个 KL 散度损失,模型架构不需要做任何改动。
- 可以减少模型参数的自由度,与其他适用于隐藏单元或模型权重的正则化方法互补。正常的正则化是泛化。
- 4 个 NLP 任务和 1 个 CV 任务共 18 个数据集上表现出极好的结果。
相关工作
- 正则化方法:权重衰减(L2 正则化)、Dropout、归一化、添加噪音(数据增强)、逐层预训练和初始化、Label 平滑等等。
- 自蒸馏:有点类似自蒸馏——不是从模型自身或不同的层,而是实例化的自知识蒸馏,也有点像共同学习,但没有额外的参数。
注:L2 正则化(目标函数上增加正则项,修改了优化目标)和权重衰减(训练每一步结束后,对网络中的参数值直接裁剪一定比例,优化目标不变)在简单梯度下降时是一个意思,但那些学习率随时间变化的优化方法就不一样了,此时 L2 正则化的效果会随之变化,但权值衰减的比例是固定的,与学习率无关。
方法
因为 Dropout 是随机的,所以过两次模型相当于跑了两个子模型,而最小化两次输出的双向 KL 散度可以对参数的自由度进行限制,进而避免过拟合,提升泛化能力。
交叉熵损失为:
最终损失函数为:
官方提供了实现,也是异常简单:
1 | # Code From: https://github.com/dropreg/R-Drop |
Tensorflow 有苏神的实现:
1 | # Code From: https://github.com/bojone/r-drop |
实验
一共 4 个 NLP 任务和 1 个 CV 任务,在 MT,NLU 和 LM 任务上效果还行,Summarization 和 Image Classification 任务提升较小。此处仅展示 MT 和 NLU 任务:
MT
α=5

NLU
α 在 0.1 0.5 和 1.0 之间动态调整。
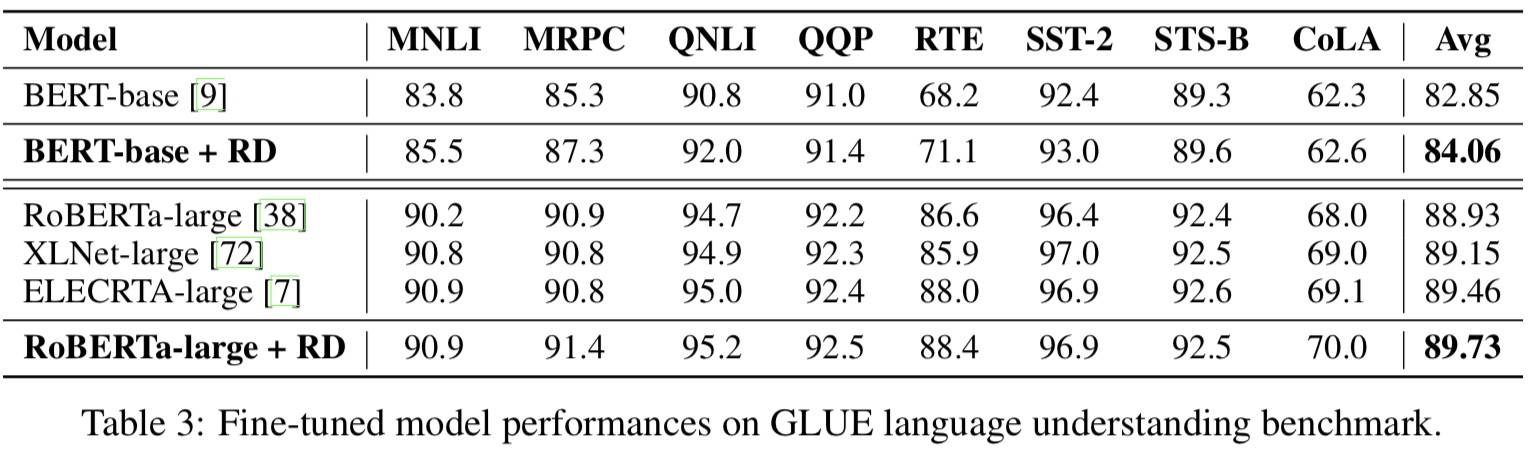
其他实验 Summarization 的 α=0.7,LM 的 α=1.0/0.5(Transformer/Adaptive Input Transformer),图像分类任务 α=0.6。
研究
主要对 R-Drop 相关配置的变化做了一些实验。
正则化和成本分析
- R-Drop 有更低的验证 loss,可以在训练过程中提供持续的正则化。
- 训练早期,Transformer 提升了 BLEU,但不久会陷入局部最优,R-Drop 持续提升 BLEU。
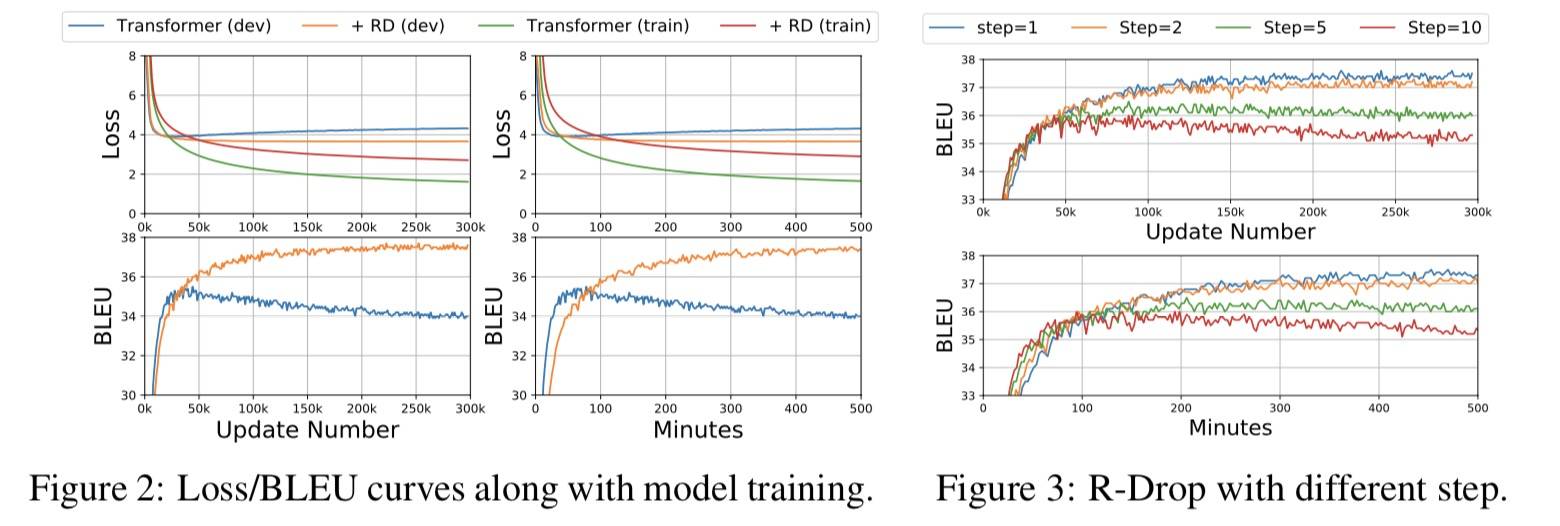
k-步 R-Drop
每隔 k 步执行 R-Drop,而不是每步都执行,具体效果见上图(右):
- k 越大收敛越快,但不是最优(过拟合),而且随着 k 增加 BLEU 越来越差。
- 每一步都执行比较好。
m-次 R-Drop
默认是两次(m=2),实验了 m=3,结果显示差不太多。
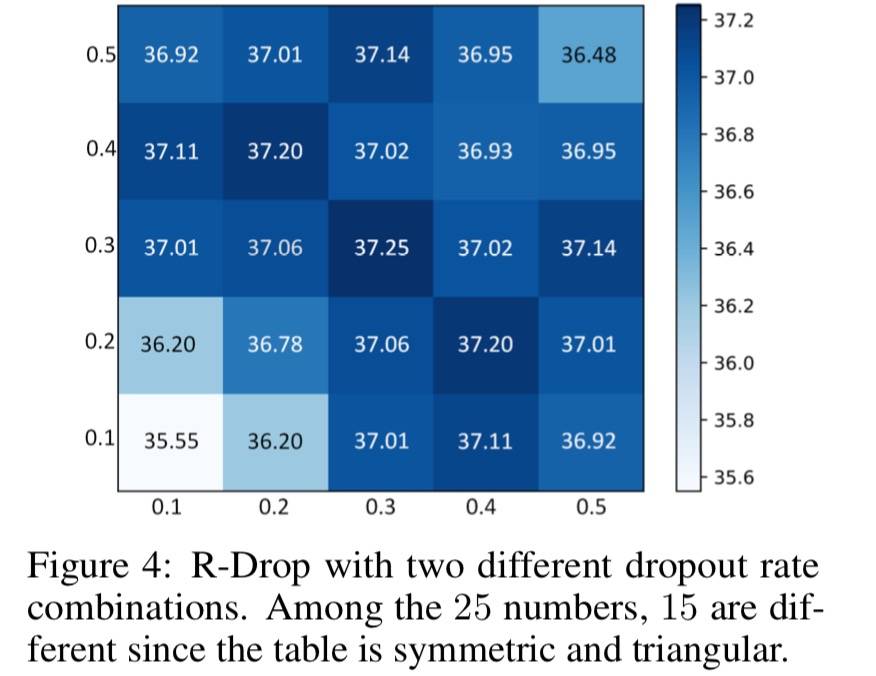
两个不同的 Dropout 比例
- Dropout 比例一致时(0.3,0.3)效果最好。
- 两个比例在适当区间(0.3-0.5)效果最好。
α 的效果
在 NMT 任务上做了 1 3 5 7 10 等多组对照实验,结果发现:
- 小的没大的好。
- 太大也不好。
- 最佳值 5,相比 1 提升 1 个多点。
结论
提出一种基于 Dropout 的简单有效的正则化方法,最小化从模型训练中的 Dropout 采样的任何一对子模型的输出分布的双向 KL 散度。不仅可以增强大模型(BART、Roberta-Large),同时在大规模数据集上也取得了很好的效果。唯一的不足怕是训练时间要加倍。