论文:[1905.03197] Unified Language Model Pre-training for Natural Language Understanding and Generation
一句话概述:一个通过参数共享训练多种语言模型以同时适应下游 NLU 和 NLG 微调的统一框架。
摘要:UniLM,统一的预训练语言模型,可以同时微调 NLU 和 NLG 任务。做法是使用三个不同类型的语言模型任务:单向、双向、Seq2Seq 预测。具体是使用一个共享的 Transformer 网络,并利用不同的 Self-Attention Mask 来控制预测基于哪些上下文。结果自然是很好(不,极好)的。
背景
Bert 后的一篇文章,拜读的时间有点晚,不过开场很清晰,表格一览无遗:
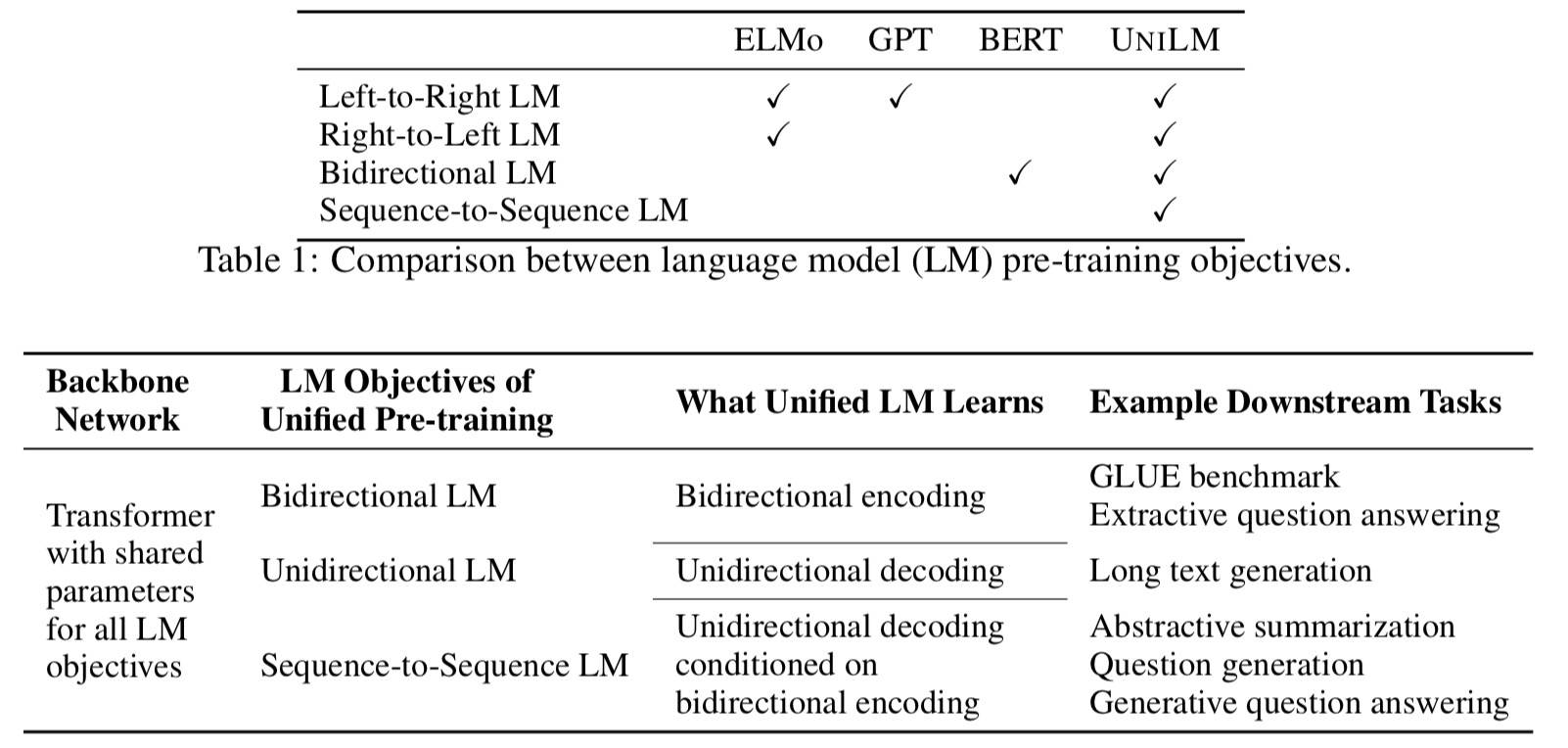
单向的都很好理解,双向的就是用的 Bert 的方法,这个 Seq2Seq 的 LM 第二个(目标)序列中待预测词的上下文由第一个(源)序列中的所有词和目标序列中其左侧的词组成。
UniLM 的三个优势:
- 统一的预训练过程导致单个 Transformer LM 使用不同类型 LM 的共享参数和架构,减轻了单独训练和使用的需要。
- 参数共享使得学习的文本表示更加通用,减轻了对任何单个 LM 的过度拟合。
- 可以应用于 NLU 和 NLG 任务。
UniLM
主要就是使用 Mask 来控制在计算上下文表征时需要哪些以及多少上下文的 Token,高清大图:
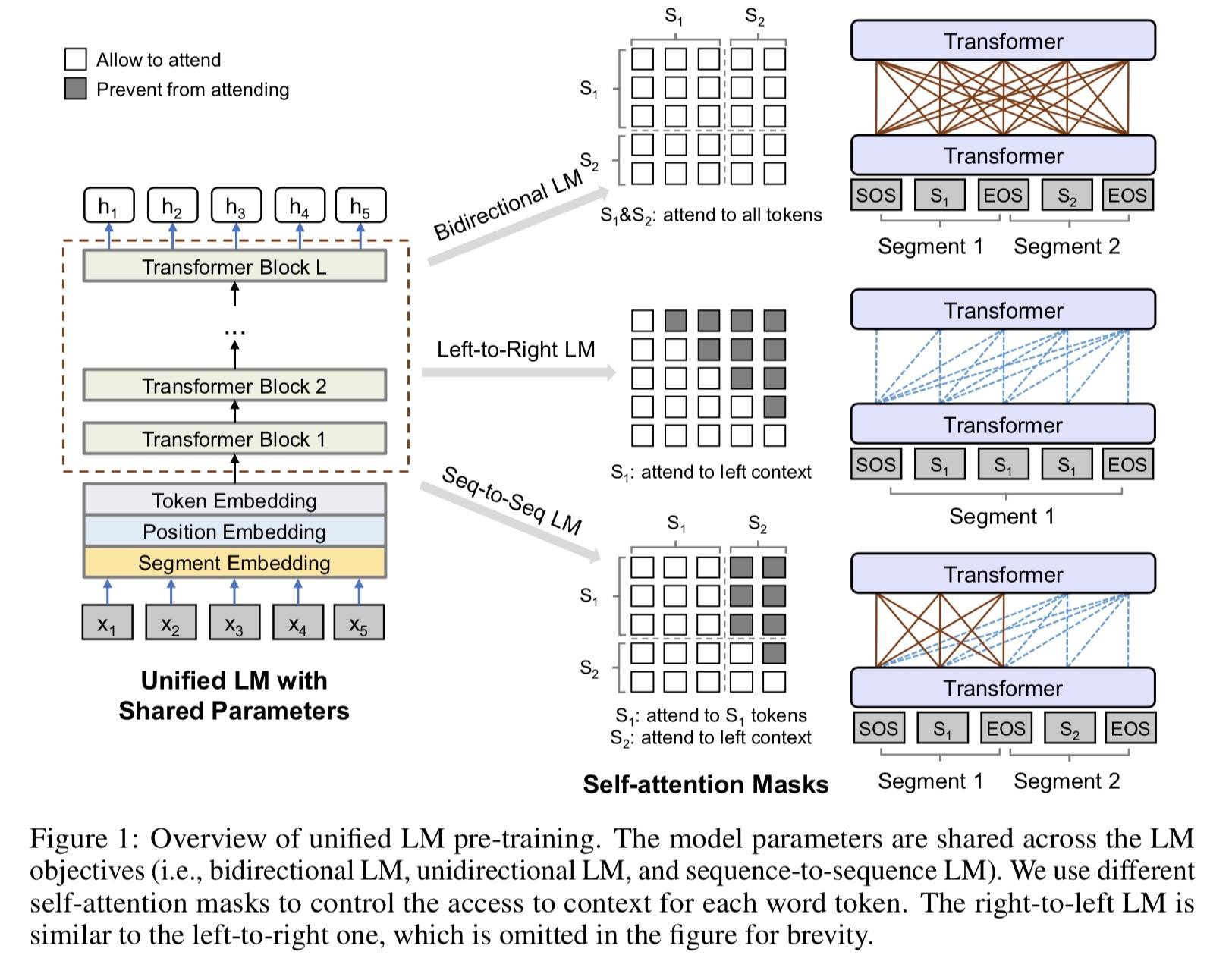
输入
- 单向 LM:一个文本分割
- 双向 LM + Seq2Seq LM:一对分割(与 Bert 同)
- Segment Embedding 起 LM 标识的作用
基本网络
主要是 Mask:
0 表示所有 Token 可以互相使用。稍稍需要注意的是,这里的 Mask 和平时使用的 Attention Mask 略有不同。
预训练目标
训练时,随机选择一些 WordPiece Token,然后替换成【MASK】,然后将 Transformer 计算的相关输出向量喂入 SoftMax 预测 Masked 掉的 Token。
- 单向 LM:包括 L→R 和 R → L。比如预测 x1 x2 [MASK] x4 中的 MASK,只使用 x1 x2 和它自己。
- 双向 LM:每个 Token 可以使用输入中的所有位置来预测。
- Seq2Seq LM:预测时,第一个分割(Source)可以使用所有位置的 Token,第二个分割(Target)只能使用它左边的 Token 和它自己(与单向 LM 一样)。比如 [SOS] t1 t2 [EOS] t3 t4 t5 [EOS],t1 和 t2 可以使用前 4 个 Token(所有位置),t4 能使用前 6 个 Token。
- NSP:BERT 的 Next Sentence Prediction 任务。虽然 RoBERTa 说 NSP 没啥用,不过我还是觉得得分下游任务和使用场景,这个任务关注的是句子间的关系(而且是上下文衔接关系)。目前数据集中这样的任务并没有,自然可能没体现出优势。
预训练启动
- 在一个 batch 中,1/3 的时间使用双向 LM 预训练目标,1/3 的时间是 Seq2Seq LM 目标,两种单向 LM 分别是 1/6
- BERT Large 的架构,GELU 激活
- 使用 BERT Large 初始化,然后在 Wikipedia 和 BookCorpus 上预训练
- MASK 概率是 15%,80% 替换成【MASK】,10% 替换成随机 Token,10% 保持不变。80% 的时间每次随机 Mask 一个 Token,20% 的时间 Mask 一个 Bigram 或 Trigram。
- β1=0.9,β2=0.999,LR=3e-5,Warmup 40000 step,Linear Decay 0.01,dropout=0.1,batch_size=330,total=770000 steps
下游任务微调
- NLU:以文本分类为例,【SOS】Token 作为句子表征。
- NLG:以 Seq2Seq 任务为例,随机 Mask 掉 Target 一定比例的 Token,然后重建 Mask 掉的 Token,【EOS】标记了 Target 的结尾,在微调时可以 Mask,此时当模型能够学习何时生成【EOS】以结束 Target 的生成过程。
实验
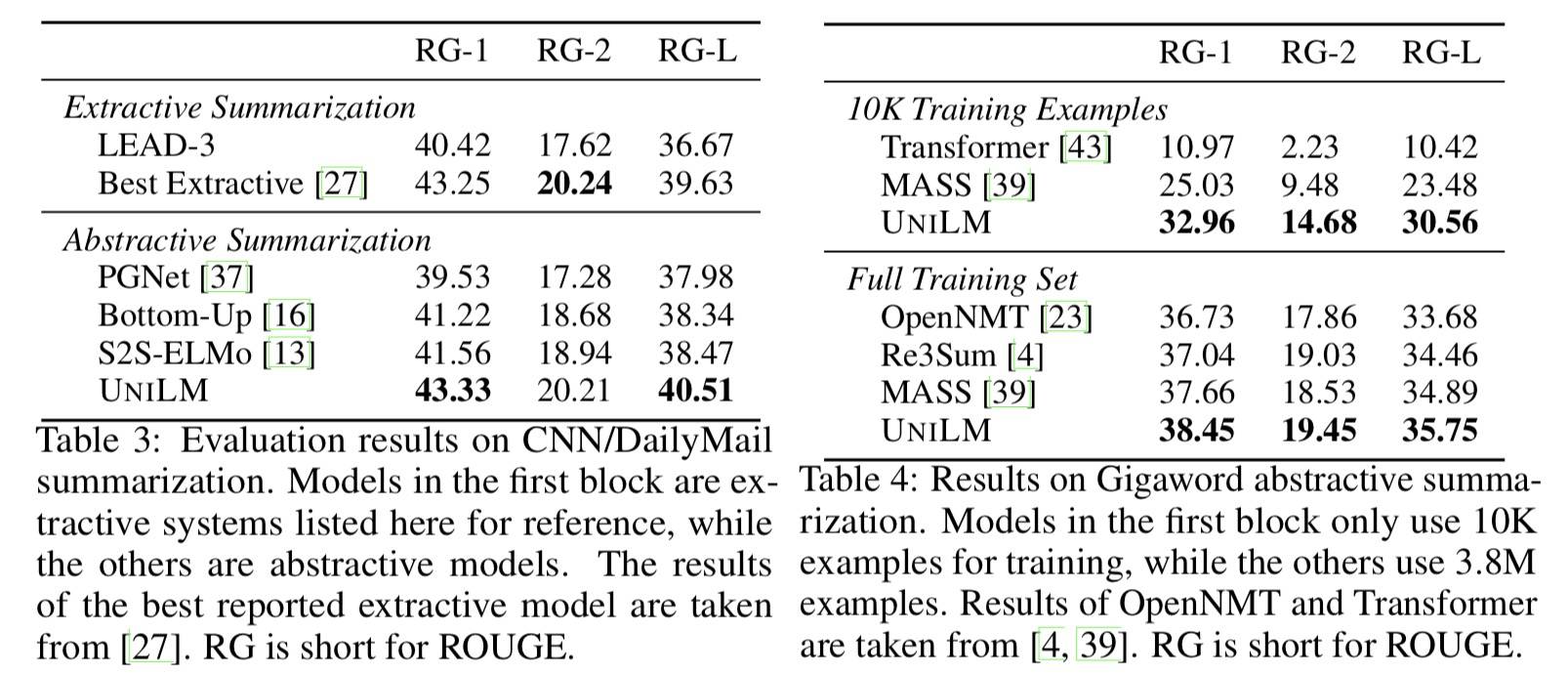
生成式文本摘要
- 作为 Seq2Seq 模型进行微调,Document 作为第一个分割,Summary 作为第二个分割。
- 微调 30 Epoch,MaskProb=0.7,Label 平滑 rate=0.1,BeamSearch BeamSize=5
QA
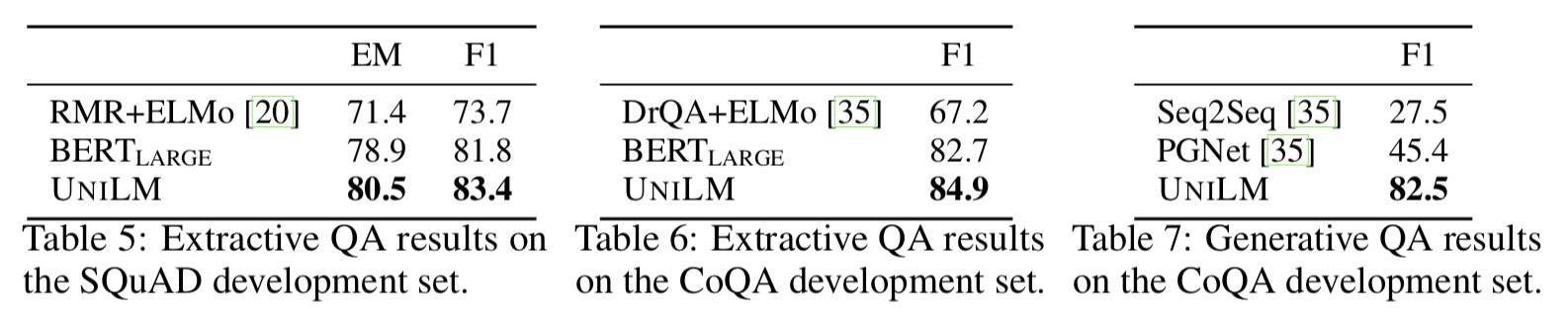
- 抽取式 QA:
- 预测 answer span 的 start 和 end position
- 作为双向 Encoder 微调
- SQuAD:BERT Large 和 UniLM 都微调 3 Epoch,BatchSize=24,MaxLen=384
- CoQA:将历史 QA 加入第一个分割,对 yes/no 问题,使用最后一个隐层的【SOS】Token;对其他问题,选择具有最高 F1 的子片段。
- 生成式 QA:
- 作为 Seq2Seq 模型微调
- 第一个分割是对话历史、问题和段落,第二个分割是 Answer
- 微调 10 Epoch,BatchSize=32,MaskProb=05,MaxLen=512,Label 平滑 rate=0.1
- Decoding 时:BeamSearch BeamSize=3,输入问题和段落的 MaxLen=470,对长度超过限制的,使用滑动窗口将文本切割成若干片段,选择和问题具有最多词重叠的片段。
问题生成
- 给定输入段落和 Answer Span,生成答案的问题。
- 定义为 Seq2Seq 问题
- 第一个分割是段落和答案的拼接,第二个分割是生成的问题
- 微调 10 Epochs,BatchSize=32,MaskProb=0.7,LR=2e-5,Label 平滑 rate=0.1
- Decoding 时:长度为 464 Token 包含 Answer 的段落块
- 问题生成任务生成的增强数据能够提升 QA 模型的效果
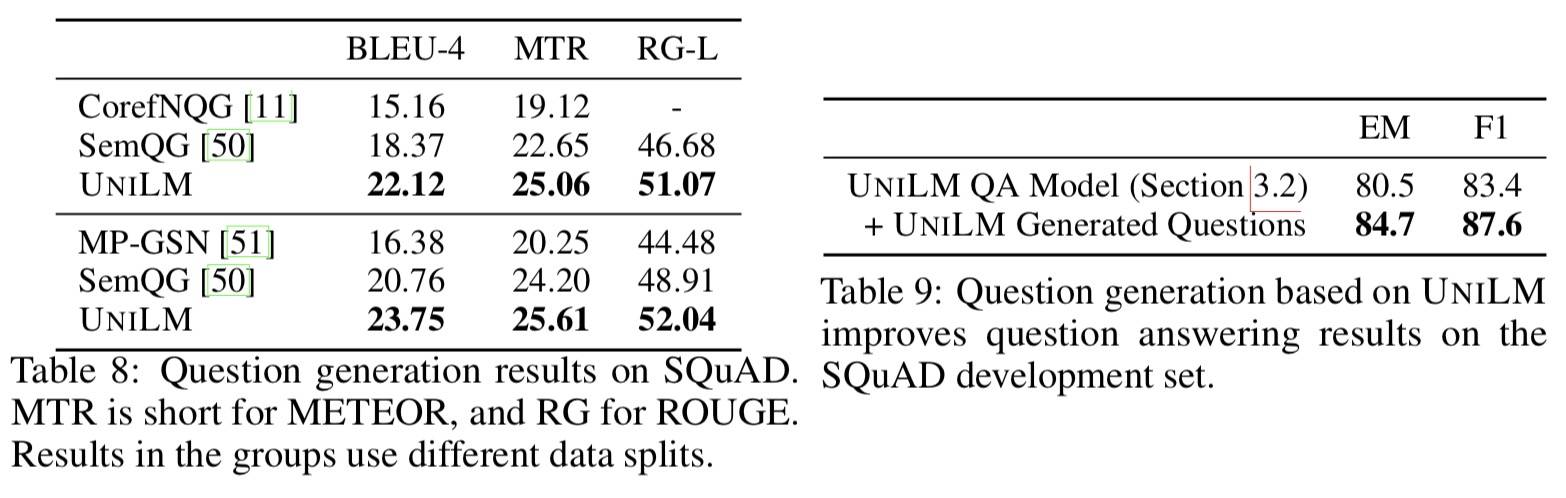
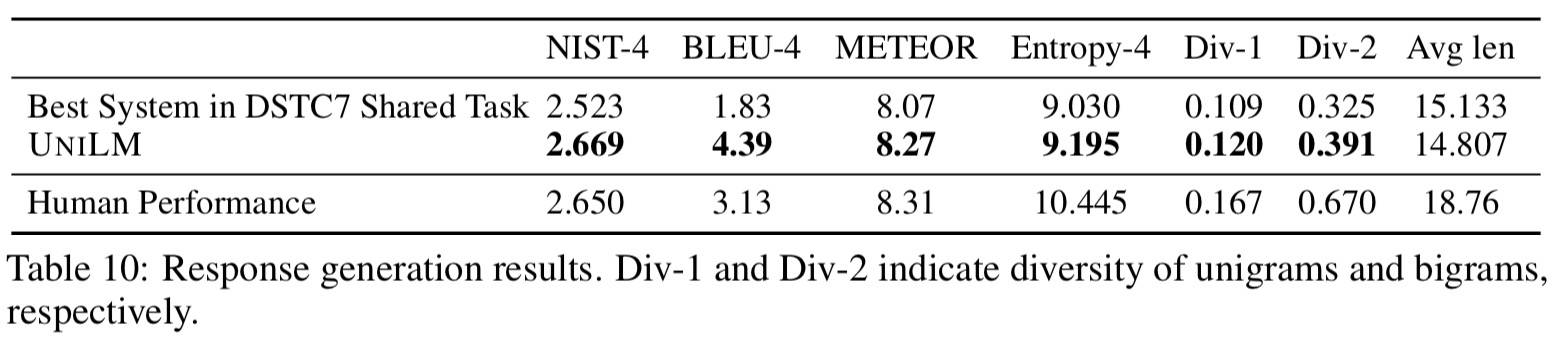
Response 生成
- 生成多轮对话的回复,既要使会话恰当,同时也能反映文档内容
- 作为 Seq2Seq 模型微调
- 第一个分割是文档和对话历史的拼接,第二个分割是回复内容
- 微调 20 Epoch,BatchSize=64,MaskProb=0.5,MaxLen=512
- Decoding:BeamSearch BeamSize=10,回复的 MaxLen=40
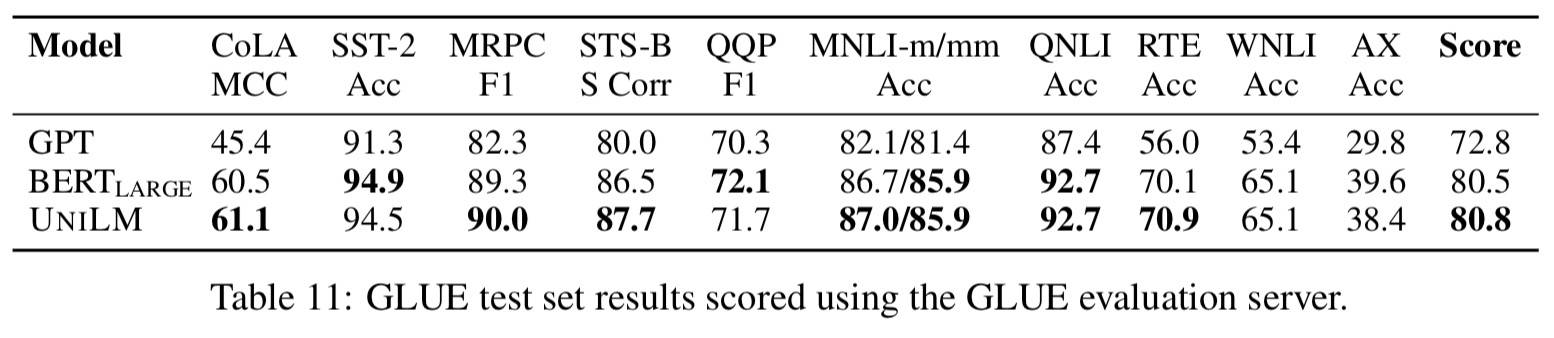
GLUE
- 作为双向 LM 微调,最大 Epoch=5
- Adamax 优化器,LR=5e-5,BatchSize=32,Linear LR Decay,Warmup 0.1,最后的线性连接 Dropout=0.1(MNLI 0.3,CoLA/SST-2 0.05),梯度截断 1,MaxLen=512
结论
提出了一个统一的预训练模型,使用参数共享同时优化几个不同的 LM,使得预训练模型可以同时在 NLU 和 NLG 上进行微调。未来的改进方向:
- 训练更多 Epoch 和使用更大的模型探索极限,更多终端应用和消融实验研究模型能力和使用同一网络预训练多语言建模任务的好处。
- 扩展以支持跨语言任务
- 对 NLU 和 NLG 进行多任务微调