Paper:2105.00828 BERT memorisation and pitfalls in low-resource scenarios
Code:无
核心思想:结合原型网络,将少样本的标签表征为稠密向量。
为了更好理解预训练模型是如何学习的,本文研究了在噪声和少资源场景下泛化和记忆的能力。结果如下:
- 标签或数据噪声几乎不影响模型表现
- 在少资源任务(如 few-shot 学习或稀有实体识别)上完全失败
为了缓解这种限制,本文基于 BERT 和 prototypical 网络提出新的架构,提升在少资源情况下命名实体识别任务的表现。
背景动机
之前的研究更多关注学到了什么,但是怎么从下游任务数据中学习的过程,以及学习动力的定性性质仍不清楚。本文主要研究基于 transformer 的预训练模型在标签不足或噪声条件下的学习行为。结果发现一个预训练的 BERT 几乎不会忘记已经学到的样例,而且大部分的样例在前几个 epoch 就学到了,后面的训练过程更多记忆噪声。
记忆机制在少样本不均衡类型场景下尤其重要,如果一个类型少于 25 次,BERT 会完全失败,只有达到 100 次才会有合理的表现。为了解决这个限制,文章提出了一种方法,该方法使用受原型网络启发的层来增强 BERT(Snell 等人,2017)。该层在特征空间中以每个类为基础显式聚类示例,并通过找到它们最近的类质心对测试示例进行分类。
主要贡献如下:
- 确定了学习的第二阶段,BERT 不会过拟合噪声数据
- 实验证明 BERT 对标签噪声鲁棒性很好,即使标签噪声极强也能够达到接近最优的表现
- 相比其他一些替代方法,遗忘率低得多
- 针对有限样本少类型识别失败的问题,提出新的方案:ProtoBERT
算法模型
将 BERT 的预训练知识与具有 few-shot 能力的原型网络结合:
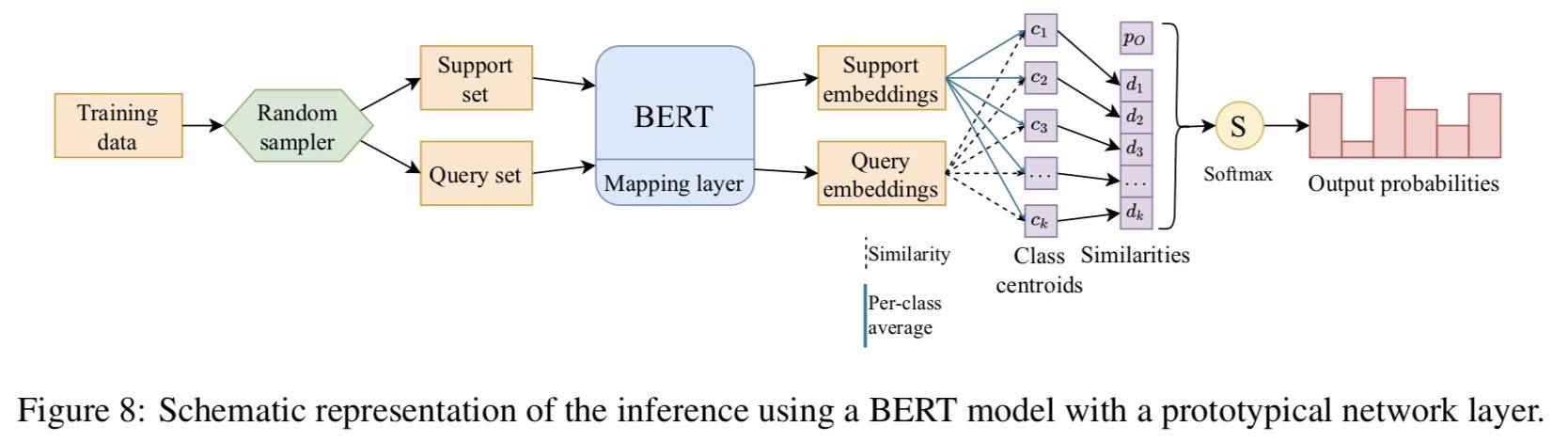
原型网络旨在构建一个 Embedding 空间,其中输入在每个类的基础上进行聚类,允许我们通过找到最接近的质心并将其分配给相应的类来对 Token 进行分类。
一些定义
- 定义支持集合 S,Sk 表示 S 中所有的元素 label 都是 k
- 定义要分类集合 Q,l(Qi) 表示 Q 中第 i 个元素的 label
- f 为 BERT + LinearLayer 产生的 M 维输出
对给定的输入 x 分类过程
-
对每个 label k 计算质心,它等于 S 中 label 为 k 的所有元素通过 f 得到的向量的平均值
-
计算 x 和质心的距离,并得到 k 维向量 v:
-
计算 x 属于 k 的概率:
训练过程就是优化此概率和 x 的 one-hot 真实 label。S 和 Q 每个训练步都会变化,d 采用欧氏距离。
对于 NER 任务,并不会学习 O 的通用表征,只需要模型将其作为一个【没有其他相似类型】的反馈,因此 v 可以表示为:
dO 表示【足够接近】的阈值。
S 和 Q 采样过程
- 随机从训练集 X 中选择属于每个稀有类的 s1 个样本,并将稀有类的剩余样本添加到 Q。
- 从 X 中选择 s2 个不属于稀有类的样本,并将它们添加到 S。
- 从 X 中选择 n·s1·cm 个样本没有同时在 S 或 Q 中,然后将它们添加到 Q 中。其中,n 是负样本比例,cm 是训练集中稀有类别的数量
采样后数据如下:
-
S 包含的样本数:
-
Q 包含的样本数:
Cm 是稀有类别的集合,Xk 是训练集中 label 是 k 的样本数。
总之,高 s1/s2 则稀有类别优先,反之则更关注其他类别。
如果在训练期间支持集中没有某个类的样本,则分配 400 的距离,从而不可能在该特定批次中将输入错误地分类为缺失的类。
测试环节
提供两种方法计算 Token 的类别:
-
第一种方法使用来自 X 的所有示例来计算测试时所需的质心,这会产生更好的结果,但对于较大的数据集来说计算成本很高。
-
第二种方法使用在每个训练步骤产生的质心的移动平均值来近似质心 ck:
其中 α 是权重因子。这种方法在训练期间产生的开销很小,并且只比第一种方法表现差一点。
实验报告
实验设置
数据集
- CoNLL03:NER
- JNLPBA:Bio-NER
- WNUT17:动机是观察到最先进的方法倾向于简单地记住在训练时和测试时都存在的实体,它侧重于识别模型无法简单记忆的异常或稀有实体。
Base
- BERT-base + 分类前馈层 + 交叉熵
- 每个数据集微调 lr 0.0001 + 4 epochs
- AdamW 优化器
- Weight decay 0.01 + linear warm-up 10%
本文
- 10 layers
- word 300 维,char 50 维
- Adam 优化器
- lr 0.0001 + 100 epochs
- CRF Loss
标签噪声
通过随机变换部分训练标签引入人工噪声。
BERT 学习时噪声的影响
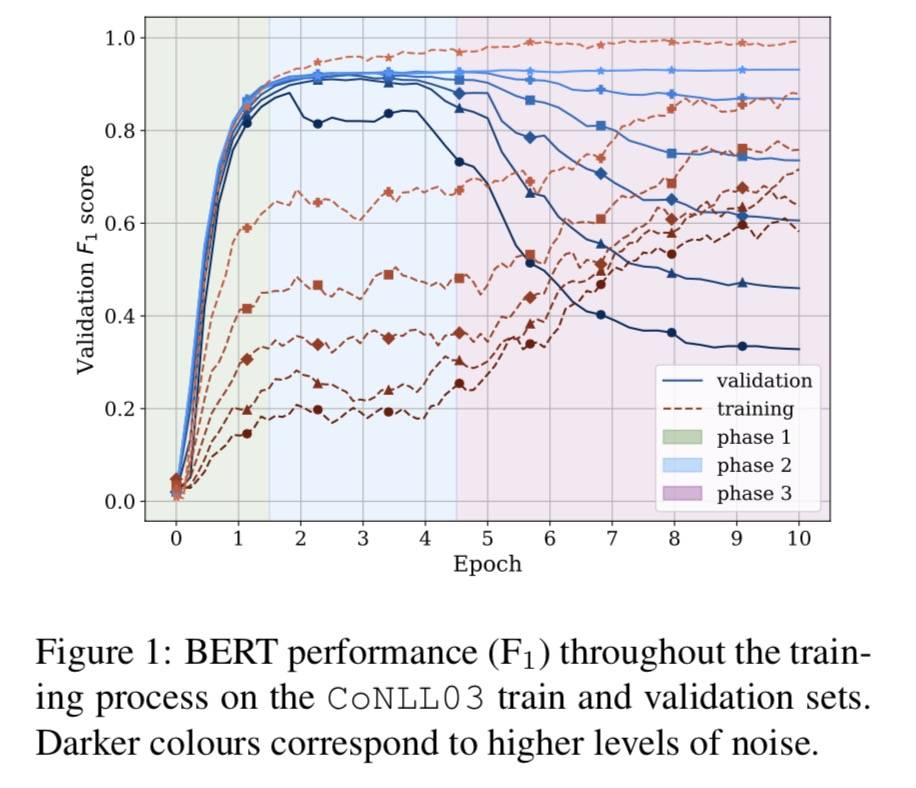
三个不同的阶段:
- 拟合:学习如何泛化,使用简单的模式尽可能解释更多的训练数据。
- 稳定:这个阶段的持续时间似乎与数据集中存在的噪声量成反比。
- 记忆:快速记住噪声样例,提高训练表现,同时验证集表现下降。
第二阶段学习
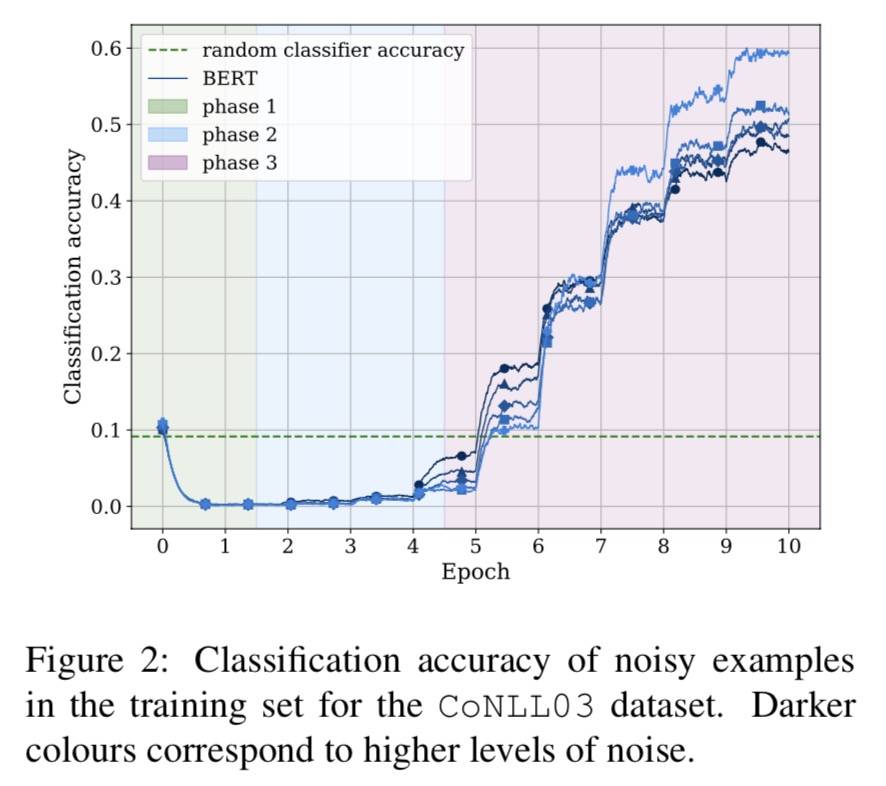
在第二阶段,BERT 完全忽略了带噪声的 Token,因此在它们上的表现比随机分类器更差。
噪声鲁棒性
图 1 中观察到 BERT 对噪声和一般过拟合非常稳健。在没有噪声的情况下,即使进一步训练,BERT 也不会过度拟合。即使有很大比例的噪声,也可以通过在第二阶段提前停止来获得与在干净数据上训练的模型相似的性能。
而且第二阶段的噪声,仅使用训练的 loss 聚类就可以达到 90% 的噪声检测 F1。
预训练影响
一个使用相同架构(BERT)随机初始化的模型不仅表现差,而且没有显示出第二阶段训练及对噪声鲁棒。
其他预训练模型
与 BERT 有相同的训练模式:
- 三个阶段
- 第二阶段对标签噪声鲁棒
- RoBERTa 对标签噪声更加适应
BERT 的遗忘
- 一个遗忘事件:epoch t-1 能够正确分类,epoch t 不能
- 一个学习事件:epoch t-1 不能正确分类,epoch t 能
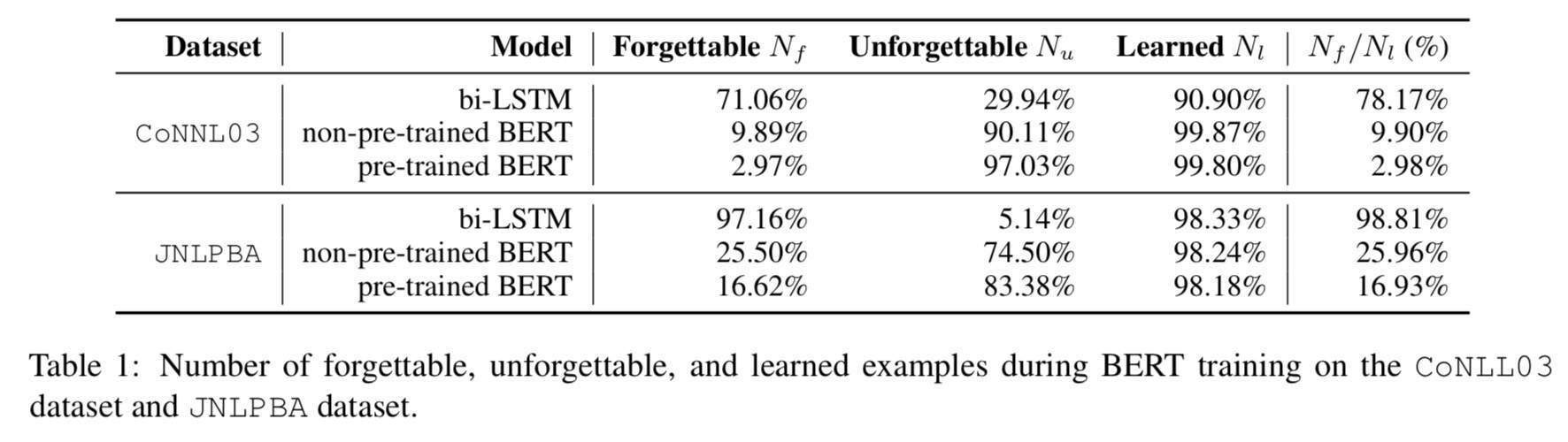
被遗忘的大多是相应类别的非典型示例。
少资源场景下的 BERT

可以观察到两个现象:
- 减少句子的数量会大大降低模型的泛化能力,但不会降低其记忆能力。
- 当可用的句子较少时,它们往往是在较早的时期首次学习的。
ProtoBERT
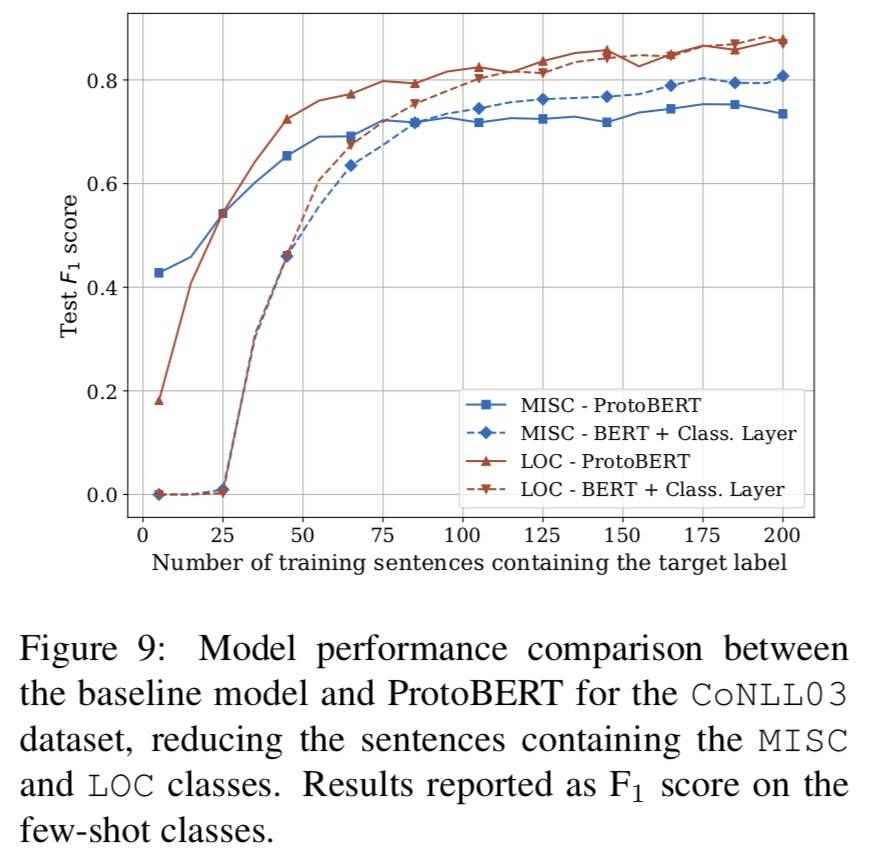
在少样本稀有类型上,ProtoBERT 超过基准,随着可用样例数量增加,BERT 和 ProtoBERT 不相上下。

在所有数据集全集上的表现与 baseline 相似,但是 WNUT17(侧重识别稀有实体)上要好很多。
相关讨论
- 记忆
- Carlini et al. 2019:LSTM 能够在训练的开始阶段记住 OOD(分布外)样例。
- Liu et al. 2020:训练的早期阶段正则化对于防止 CNN 残差模型在以后记住噪声样例至关重要。
- Li et al. 2020:早期停止和梯度下降有助于增加模型对标签噪声的鲁棒性。
- Petroni et al. 2019:预训练模型在回忆事实方面非常有效。
- Zhang et al., 2017b:记忆与泛化密切相关:已经观察到神经网络可以在噪声之前学习简单的模式并进行泛化,尽管能够完全记住随机样例。
- 遗忘
- Toneva et al. 2019:模型总是会忘记很大一部分训练数据,而这部分可遗忘的样例主要取决于训练数据的内在属性而不是特定模型。
- 本文:BERT 相比 BiLSTM 或其他非预训练的变种几乎不会忘记。
- OOD 和噪声数据
- Hendrycks et al 2020:与非预训练方法相比,预训练模型在分布外数据上表现更好,并且能够更好地检测此类数据,但它们仍然不能完全分离分布内和分布外示例。
- Kumar et al. 2020:预训练模型对拼写错误敏感。
- 本文:关注模型在存在标签噪声的情况下的学习动力,并发现预训练的方法对此类噪声具有显着的弹性。
小结
本文解决了 BERT 无法从极少量样本中学习的问题,具体是通过原型网络增强 BERT。同时分析了 BERT 在噪声下的性能,结果发现,即使标签损坏,BERT 也能够达到接近最佳的性能。这种能力是由于 BERT 倾向于将训练分为三个不同的阶段:拟合、稳定和记忆,这使得模型可以在早期忽略噪声样本。