Paper:[2002.12327] A Primer in BERTology: What we know about how BERT works
核心:全方位研究 BERT 到底学到了什么,怎么学的,效果如何,怎么改善。
- 语言视角:学到了什么,存储在模型的哪里,怎么存储的?
- 技术视角:目前如何提升架构、预训练和微调的整体描述
BERT 的知识
句法知识:
- 表征是分层的
- Embedding 层编码了词性、句法块和角色信息
- 句法结构并没有直接被 Self-Attention 编码
- 但是可以从 Token 表征中恢复
- BERT 可以自然地学到了一些句法信息,虽然和语言学的不太相同
- 它学到的句法知识要么是不完整的,或者看起来更像是它并不依赖这些知识处理任务
语义知识:
- 学到一些语义角色知识
- 编码了实体类型、关系、语义角色和原型角色等信息
- 不能很好地表征数字
- 在实体替换上非常脆弱,说明模型没有学到实体一般性的概念
通用知识:
- BERT 虽然会学习务实的推理和基于角色的事件知识,以及对象的抽象属性、视觉和感知的性质,但效果并不理想
- BERT 在某些关系类型上可以和基于知识库的方法媲美
- 但是 BERT 不能基于它自己的知识进行推理
局限性:
- 在任务上没有观察到语言模式并不能保证它不存在,而且对模式的观察也并不能告诉我们如何使用它
- 不同的探测任务可能导致互补甚至相反的结论,给定的方法可能支持某一个模型而不支持另一个,换个方法又反过来了
- 一个替代方案是关注识别 BERT 在推理时依赖什么
- 另一个方向是信息理论探测,关注的不是表征中包含的信息总量,而是能够很容易地从中提取的
局部语言知识
Embeddings:指 Transformer Layer 的输出。下文讨论主要指 Token Embedding。
- 一些研究发现蒸馏的上下文 embedding 可以更好地编码词汇语义信息,具体做法有:
- 将上下文表示形式提炼成静态形式(包括在多个上下文中汇总信息)
- 编码语义苍白的句子(语义大部分依赖某个特定词)
- 直接使用上下文 embedding 训练静态 embedding
- 后面的层生产了更多的上下文表征,并且在向量空间上表现出狭窄的锥形,这种效应从前面的层到后面的层递增
- 之前有研究表明:各向同性有助于静态词表征,后面字节的 BERT-flow 和追一科技的 BERT-whitening 就是在这方面做了尝试
- BERT 的上下文 embedding 形成了与词义相对应的不同簇,可以很好地进行词义消歧
- 同一个词的表征依赖其在句子中出现的位置
- 分类时的句子表征一般用 CLS 表征,或者聚集 Token 表征
Self-Attention heads
- 语言功能
- 某些 head 看起来会注意句法关系中的特定类型
- 没有单一的 head 拥有完全的句法树信息
- 注意力权重是主语一致和反身回指的弱指示,注意力权重接近于一个统一的注意力基准
- 形态学方面,某些注意力 head 显现出合并 BPE token
- 语义关系方面,能够编码核心语义框架关系、词法和通用常识关系
- 特定 Token 的注意力
- 大多数 head 不会直接编码任何不重要的语言学信息,至少在 GLUE 上微调时
- 前面的层更多在 CLS,中间层在 SEP,后面的层在句号和逗号
Layers
- 前面的层具有有关线性单词顺序的最多信息
- 中间的层句法信息最突出(base-BERT 6-9,large-BERT 14-19)
- 关于句法块,证据之间有冲突
- 最后一层最特定于任务
- 句法信息在模型早期出现,语义信息分布在整个模型
训练 BERT
模型架构选择:
- Head 数量没有层的数量重要,两者数量的改变会显示出不同的功能
- 不同的 Self-Attention Head 变体貌似学到了同样的模式,甚至有研究表明可以通过简单的预设置我们事先已经知道模型能够学到的 pattern,而不是从头到尾学习
- Self-Attention 和 Feed-Forward 层可能并不平衡,底层的 Self-Attention 和顶层的 Feed-Forward 提供更多的益处
训练机制改进:
- 大批次训练的益处:效果好、速度快
- Self-Attention 高层和底层的模式相似,模型训练可以递归方式进行,先训练较浅的版本,然后将训练后的参数复制到较深的层
预训练 BERT:对 MLM 进行优化
- 怎么 Mask
- 调整比例和 Span 长度
- 动态 Mask:每个 Epoch 不同的 Mask
- Mask 每个 Token 而不是随机选择
- 将 MASK 替换为 UNK(对翻译任务有用)
- 最大化模型在 Mask 和未 Mask Token 条件下可用的信息量,并让模型查看缺少的 Token
- Mask 什么
- 全词取代子词
- Token Span 而不是单个 Token
- 预测缺失了多少个 Token
- Mask 短语和实体提高结构化知识表征
- 在哪里 Mask
- 任意文本流取代句子对,且二次抽样高频的输出(与 Word2vec 类似)
- 使用特殊的伪 Mask Token 合并标准的自编码 MLM 和部分自回归 LM 对象
- Masking 替代方案
- 替换和丢弃 Span
- 删除、插入、句子排列、文档旋转
- 预测一个 Token 是不是大写,以及是否在同一个文档的另一部分出现
- 输入序列不同的词序组合,最大化原始词序的概率(Ngram 词序重建)
- 检测被一个 Generator 生成的 Token 替换而不是 Mask 掉的 Token
- NSP 替代方案
- 去掉 NSP
- 预测上一句和下一句
- 通过从正例中交换句子而不是来自不同文档的句子来替换负 NSP 示例
- ERNIE 2.0 包括句子重新排序和句子距离预测
- 通过段落、句子和 Token 索引 Embedding 的组合替换 NSP 和 Token 位置 Embedding
- 对多方对话的话语顺序预测任务(以及话语和整个对话层面的 MLM)进行实验
- 其他任务:
- 同时 7 项任务,包括话语关系分类和预测一个分割是否与 IR 相关
- 在语言模型预训练中包括一个潜在的知识召回器
- 使用 Span 预测任务替换 MLM(如抽取式问答)
- 预训练数据:
- 增加语料
- 增加预训练时间
- 加入语言学知识:语法、语义、标签
- 直接提供结构化知识:实体增强模型、额外的预训练知识库
- 修改 MLM:Mask 实体、文本+表格数据
- 使用特定任务的适配器通过语言和事实知识增强 RoBERTa
微调 BERT:
- 考虑更多的层
- 学习学习深层和输出层中信息的互补表示
- 使用所有层的加权组合而不是最后一层和层 Dropout
- 二阶段微调
- 在预训练和微调之间引入一个监督训练
- 提出一个基于轴的 MLM 变种来微调
- 对抗的 Token 扰动
- 增加鲁棒性
- 对抗的正则化
- 与 Bregman Proximal Point Optimization 结合缓解预训练知识遗忘
- 混合正则化
BERT 应该多大?
过度参数化:
- 110M Bert,175B GPT-3
- 除了少数 Head,都可以在不显著降低性能的情况下进行修剪
- 有些 Head 和 Layer 不仅多余,而且会损害下游任务性能
- 大模型并不是永远比小模型效果好
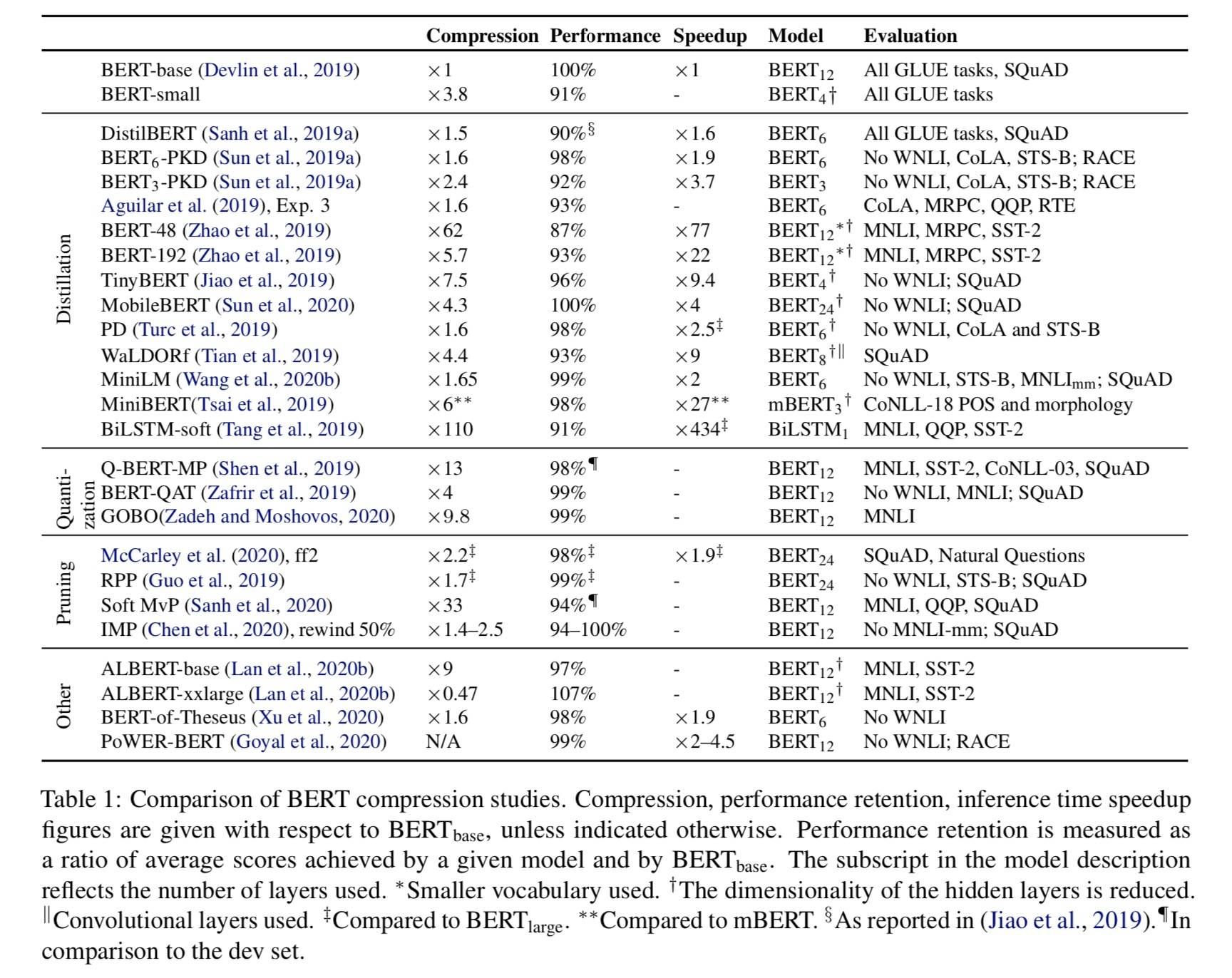
压缩技术:蒸馏、量化、剪枝
-
知识蒸馏使用经过培训的较小的学生网络来模仿较大的教师网络的行为。对于 BERT,是通过在预训练或微调阶段模仿教师网络各个部分的激活模式和预训练时的知识转移来实现的
-
量化通过降低参数的精度来减少内存占用
-
修剪通常通过将大型模型的某些部分归零来减少计算量
- 在结构化修剪中,架构块被删除,如 LayerDrop
- 在非结构化中,无论其位置如何,整个模型中的权重都会被修剪,如幅度修剪或移动修剪
-
其他:
- 训练大模型大比例压缩优于小模型小比例压缩
- 分解 Embedding 矩阵
- 更先进模块替换
- 中间编码器输出的动态消除
剪枝和模型分析:
- 基本思想是先验压缩模型由对预测有用的元素组成
- 分析
- 对 Transformer,语法和位置 Head 是最后被剪枝的
- 对 Bert,并非只有可能编码重要语言模式的 Head 才能在修剪后幸存下来
- 当前关于 Head/Layer 消融实验的局限是:假设 Head/Layer 包含知识,如果相同的信息在网络的其他地方重复,则组件消融的结论也有问题
未来方向
- 基准需要语言推理(BERT 在推理中依赖浅层启发式)
- 全方位语言能力的基准
- 开发 “教” 推理的方法
- 学习推理时发生的事情
一些感想
BERT 已经用了有很长一阵了,终于看到这么一篇全方位、足够深入、充分地研究 BERT 底层原理的文章,只看了摘要就足以让人迫不及待了。还记得 18 年 BERT 刚刷新榜单时,第一反应是这到底是模型好还是模型大?每一次的 SOTA 都伴随着巨量增长的参数和数据,Paper 几乎已经看不到多少理论分析的文章,都变成了一篇篇的实验报告。这多少和深度学习黑盒子的的繁荣有关,完全不讲武德。大家迫于各种压力,被迫绞尽脑汁去设计一些变化,以期能提点分,此时我们甚至不关心好的结果是不是因为随机的因素。突然想到《系统化思维讨论》里的一句话:这些年轻的 “暴发户” 用计算机来求解大量的方程,而不是利用物理 “直觉” 先减少方程的数量,以便在所谓的信封背面用铅笔演算出结果。以前经常警戒自己,读书要读经典,写文章一定要写十年后还能看的,结果依然不得不掉进 99% 并无多大意义的研究中……不过最近总算找到了一个平衡点,知道自己该怎么看待读论文、跟进研究,也算是这几个月的收获吧。希望我们的研究更加深入、有见地。