Paper: Language Models are Unsupervised Multitask Learners
Code:
- openai/gpt-2: Code for the paper “Language Models are Unsupervised Multitask Learners”
- minimaxir/gpt-2-simple: Python package to easily retrain OpenAI’s GPT-2 text-generating model on new texts
核心思想:基于 Transformer 的更加 General 的语言模型。
What
动机和核心问题
作者认为目前这种对单域数据集进行单任务训练的普遍性,是造成当前系统缺乏普遍性的主要原因。另外,目前最好的方法是预训练模型 + 下游任务的监督训练。本文是将二者结合起来,提供更加 general 的迁移方法,它可以使下游任务能够在 zero-shot 下实施,不需要参数或架构调整。证明了语言模型有在 zero-shot 下执行一系列任务的潜力。所以本文核心点有两个:
- 更加 general 的预训练模型
- zero-shot 实施的多下游任务
前者是后者的基础,后者是前者的应用。
模型和算法
其核心是:多领域文本建模,以实现在不同任务上的迁移。所以 model 是这样的:p(output | input, task).
具体方法是:基于 Transformer,对 GPT-1 的改进:
- Layer normalization 移动到每个 sub-block 的 input
- 最后一个 self-attention block 后面加 layer normalization
- 在初始化时按 1 /√N 的比例缩放残差层的权重,其中 N 是残差层的数量
- Vocabulary 扩展到 50,257
- 上下文 token 数从 512 调整到 1024
- 更大的 batch size(512)
看这些貌似没啥感觉(当你对底层不理解时,顶层的东西看似懂了的其实都没懂,又称 “司机的知识”),还是代码来的实在。这部分的代码主要来自官方代码。正式开始前,先把参数放出来:
1 | class HParams: |
输入
首先是输入的 X:
1 | context = tf.fill([batch_size, 1], start_token) |
这里的 context 就是 start 不为 None 时的 token,我们假设 batch_size 为 1,tf.fill 就是把 start_token 填充为 [batch_size, 1] 的 shape,后面的 1 是指序列长度,我们是按一个一个 token 依次生成的。
然后是 position 和 token 的 embedding:
1 | # weight of position embedding |
n_ctx 是上下文的 token 数,n_vocab 是词表大小。合并两个 embedding:
1 | h = tf.gather(wte, X) + tf.gather(wpe, positions_for(X, past_length)) |
position_for 的目的是给 position 编码,它的结果是和 x 类似的一个 Tensor,可以看出这里采用的是绝对位置编码。tf.gather 就是根据索引从参数轴收集切片,即 X 这里的 one hot token 编码使用 wte 索引 X 的向量,和 lookup 类似。这样就得到了最终的输入 h,它的 shape 为:[batch_size, 1, embedding_shape],在本例中即为:[1, 1, 768]。
Transformer
接下来就是核心的模型部分了,也就是我们熟知的 Transformer。先看一下整体的流程:
1 | pasts = tf.unstack(past, axis=1) if past is not None else [None] * hparams.n_layer |
tf.unstack 是从 axis 维对张量从 R 级调整为 R-1 级,我们从 None 开始,暂时不需要考虑。可以看到就是 n_layer 个 block 叠加,最后做了个归一化处理。tf.stack 和 tf.unstack 的作用恰好相反。
在 block 前,可以先简单看一下 norm 函数:
1 | def norm(x, *, axis=-1, epsilon=1e-5): |
tf.compat.v1.rsqrt 是计算平方根的倒数,上面这其实就是 z 分数标准化过程。
block
先看 block 是什么:
1 | def block(x, scope, *, past, hparams): |
它的结构如下:
- attention layer:注意力层
- skip connection:残差连接
- mlp:就按字面理解为感知机吧
- skip connection
attention
无疑这个地方是最核心的了:
1 | # x: [1, 1, 768], nx: 768, past: None |
这里出现了好几个操作:conv1d, split_heads, multihead_attn, merge_heads,我们分别来看一下。
1 | # conv1d |
我不知道这里为什么会有这么个操作,不过在 Transformers 源代码中看到这么一句注释:Conv1D layer as defined by Radford et al. for OpenAI GPT (and also used in GPT-2). Basically works like a Linear layer but the weights are transposed. 姑且就这样吧。如果只看输入输出的话,它无非就是把输入的维度做了调整,在这里就是把维度放大 3 倍(真不知道怎么想出来的)。这里的目的是为了后面的 q k v。
1 | def split_heads(x): |
最后的 shape:[batch, heads, sequence, features] 也就是 q k v 的 shape,也就是把输入 X 的维度分配到 12 个 head 上。
1 | def multihead_attn(q, k, v): |
tf.cast 是改变类型,w 其实就是 Transformer 中的标准 w 计算方式,后面的这个 mask_attn_weights 是对权重 mask,即 masked self-attention,这里其实没有发生作用,我感觉它的主要作用是 mask 未来的字符,这里的 LM 模型利用的是已生成文本,所以并不需要 mask。softmax 没啥好说的,也是 self-attention 的标准配置。
1 | def merge_heads(x): |
这步是 合并 head 操作,最终的 shape 为 [batch_size, sequence, n_state],即 [1, 1, 768]。然后后面再接一个 conv1d 就是最终的输出。
mlp
接下来是一个 mlp 层:
1 | def mlp(x, scope, n_state, *, hparams): |
gelu 是个激活函数,其实就是两层 conv1d,最终 h2 的 shape 和输入的 x 其实一样,只不过中间的隐层这里为 4 倍的 n_state。
所有的 block 跑完后,最后接一个归一化层,就这样 Transformer 部分就执行完了。简单总结一下大致的结构:
- 若干个(n_layer)block + 归一化。
- 每个 block 包括一个 self_attention 层和 mlp 层,以及分别对应了残差连接。
- self_attention 和 mlp 的输入都做了归一化。
- self_attention 分为:
conv1d => split_heads => multihead_attention => merge_heads => conv1d。 - mlp 分为就是一个两层的
conv1d,其实就是一个感知机。
Language model loss
Transformer 之后接的是语言模型的损失函数:
1 | h_flat = tf.reshape(h, [batch*sequence, hparams.n_embd]) |
特点和创新
- 更加 general(更加庞大的数据集和参数)
- 下游任务 zero-shot
How
官方代码也没提供训练代码,下面这部分的代码部分来自 gpt-2-simple,注意这个并不适用于 Tensorflow 2.0 及以上版本(无法读取预训练模型),其他的倒是没有啥问题。
如何构造数据
输入的数据可以是最原始的纯文本,只不过进来后需要 Token 化,将文本变成 One-Hot 编码。参考官方的实现:
1 | def encode(self, text): |
这个就是把原始的输入 text 转为 one-hot 编码的代码,Tokenize 的模型是 bpe,encoder 类似 word2id,作者这里利用了 unicode 编码,先将 token 换成 unicode 的统一编码,然后再利用 bpe 模型去 token 化。中文的处理方式类似。
如何开始训练
这里主要是定义好 loss function:
1 | context = tf.compat.v1.placeholder(tf.int32, [batch_size, None]) |
label 其实就是输入 one-hot 的下一个 token,logits 可以看出没有取最后一个。这里 context 可以批量训练,序列的长度在 GPT-2 中是 1024。
如何使用结果
使用 gpt-2-simple 结合官方代码,代码如下:
1 | import gpt_2_simple as gpt2 |
如果需要进一步理解,可以仔细阅读下 gpt-2-simple 的代码,可以算是一个最佳实践了。在此基础上调整为中文的也非常方便。
数据和实验
文章一共做了八个项目的对比实验,分别是:
- Language Modeling:
- Children’s Book Test:考察 LM 在命名实体,名词,动词和介词等不同类别单词上的性能。
- LAMBADA:测试系统对文本中的远程依存关系建模的能力。
- Winograd Schema Challenge:测量系统解决文本歧义的能力来衡量系统执行常识推理的能力。
- Reading Comprehension:测试阅读理解能力及模型根据历史对话记录回答问题的能力。
- Summarization
- Translation
- Question Answering
内容着实有点多,就不一一列出来了,重点看一下 LM 的吧。
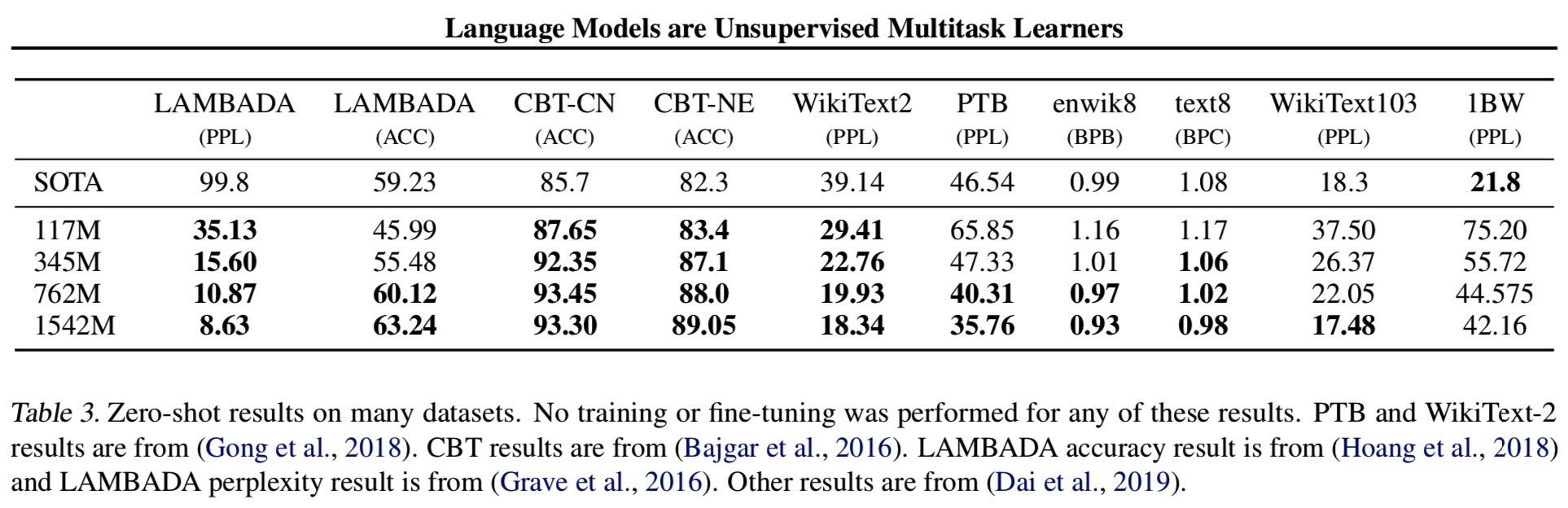
Discussion
相关工作
- RNN + 1 Billion Word: Jozefowicz, R., Vinyals, O., Schuster, M., Shazeer, N., and Wu, Y. Exploring the limits of language modeling. arXiv preprint arXiv:1602.02410, 2016.
- 更大的数据集:Bajgar, O., Kadlec, R., and Kleindienst, J. Embracing data abundance: Booktest dataset for reading comprehension. arXiv preprint arXiv:1610.00956, 2016.
- 深入分析了模型的性能如何随模型容量和数据集大小的变化:Hestness, J., Narang, S., Ardalani, N., Diamos, G., Jun, H., Kianinejad, H., Patwary, M., Ali, M., Yang, Y., and Zhou, Y. Deep learning scaling is predictable, empirically. arXiv preprint arXiv:1712.00409, 2017.
- 生成模型如何学习:Karpathy, A., Johnson, J., and Fei-Fei, L. Visualizing and understanding recurrent networks. arXiv preprint arXiv:1506.02078, 2015.
- 生成 Wikipedia 文章的模型也学会了在语言之间翻译名称:Liu, P. J., Saleh, M., Pot, E., Goodrich, B., Sepassi, R., Kaiser, L., and Shazeer, N. Generating wikipedia by summarizing long sequences. arXiv preprint arXiv:1801.10198, 2018.
- 过滤和构建网页的大型文本语料库的替代方法:Davies, M. The 14 billion https://corpus.byu.edu/iWeb/, 2018.
- GloVe 引入全局词频统计:Pennington, J., Socher, R., and Manning, C. Glove: Global vectors for word representation. In Proceedings of the 2014 conference on empirical methods in natural language processing (EMNLP), pp. 1532–1543, 2014.
- Skip-thought 向量:Kiros, R., Zhu, Y., Salakhutdinov, R. R., Zemel, R., Urtasun, R., Torralba, A., and Fidler, S. Skip-thought vectors. In Advances in neural information processing systems, pp. 3294–3302, 2015.
- 机器翻译模型中的向量表示:McCann, B., Bradbury, J., Xiong, C., and Socher, R. Learned in translation: Contextualized word vectors. In Advances in Neural Information Processing Systems, pp. 6294–6305, 2017.
- 基于 RNN 精调:Howard, J. and Ruder, S. Universal language model fine-tuning for text classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), volume 1, pp. 328–339, 2018.
- 自然语言推理模型的迁移表示:Conneau, A., Kiela, D., Schwenk, H., Barrault, L., and Bordes, A. Supervised learning of universal sentence representations from natural language inference data. arXiv preprint arXiv:1705.02364, 2017a.
- 大型多任务训练:Subramanian, S., Trischler, A., Bengio, Y., and Pal, C. J. Learning general purpose distributed sentence representations via large scale multi-task learning. arXiv preprint arXiv:1804.00079, 2018.
- 预训练模型对 Seq2Seq 模型的 Encoder 和 Decoder 有益:Ramachandran, P., Liu, P. J., and Le, Q. V. Unsupervised pretraining for sequence to sequence learning. arXiv preprint arXiv:1611.02683, 2016.
- 预训练模型对下游生成任务有效:
- Wolf, T., Sanh, V., Chaumond, J., and Delangue, C. Transfertransfo: A transfer learning approach for neural network based conversational agents. arXiv preprint arXiv:1901.08149, 2019.
- Dinan, E., Roller, S., Shuster, K., Fan, A., Auli, M., and Weston, J. Wizard of wikipedia: Knowledge-powered conversational agents. arXiv preprint arXiv:1811.01241, 2018.
特殊情况
训练集和测试集数据重叠问题。好的去重技术:可伸缩的模糊匹配(Scalable fuzzy matching),目前建议在切分训练集和测试集时,将基于 n-gram 重叠的重复数据删除方法作为重要的验证步骤和健全性检查。另一个确定模型性能是否由重复数据导致的方法是,根据数据本身的测试集(而不是另外的数据集)检查性能(其实这也可能有重复)。
打开脑洞
我:这 GPT-2 怎么看起来好像就是一个 Transformer 的 Language Model 啊?
小 A:可不是么,怎么有点大力出奇迹的感觉呢:更大的词表、更大的 batch size、更长的 context、更多的参数……然后结果就——更加 general……
小 B:也不能这么说,至少它证明了两点,第一,Transformer 的表征能力;第二,大模型的表征能力。而且也让我们的武器库里又多了一件不错的工具不是么?
小 C:确实如此,NLP 领域 LM 是最基本的模型,纵览发展历史,从 N-gram 到 RNN 再到 LSTM 再到 GPT-2,每个模型背后都隐藏着一次大的创新。现在是 Attention 的高光时刻。大家觉得下一个创新点可能在哪里?
小 A:我觉得肯定是某个新东西 + 大力出奇迹!
小 B:那你说这个新东西可能的方向是什么?
小 C:我觉得这样干想不现实,可能还是从人的认知方面去借鉴一些思想。我们再次概览历史,N-gram 可以看作局部建模,RNN 建模范围更广,LSTM 让建模范围更广的同时更加符合人的机制(遗忘、更新等),Transformer 则是关注更广范围内的重点信息,就像人会关注核心词和关键词一样。如果再从人的角度往下推,可能就是背景知识这些外部信息了,因为同样的文本在不同的背景下,我们关注的点可能不一样。也许可以可以借鉴 GloVe 的方式,也许是使用 Knowledge Graph。
小 B:我之前看过一篇关于 AI 建模体系的文章,作者对不同种类的 AI 方法进行了整合,最终的结论就是多种方法融合。不过那个有点大,而且也是一家之言。
小 A:你们想的可真多,我还就喜欢大力出奇迹,简单粗暴,就是干!
众人:……
Appendix
补充两篇我觉得不错的博客文章和本文可以相互补充: