Paper: 1603.01360.pdf
code:
核心思想:pretrained + character-based 词表示分别学习形态和拼写,Bi-LSTM + CRF 和基于转移的模型均可以对输出标签的依赖关系建模。
看了 Related Work 后发现很多想法其实早就冒出来了,不同的论文在不同点上使用了不同的方法,本篇恰好用这样的方法取得了最好的效果。其实,我觉得更加有意思的是基于转移的模型,它构建了一个 action 的时间序列,感觉更加抽象,想法更加精妙。
Abstract
传统命名实体识别依赖人工设计特征和和领域知识。本文提出两种架构:
- Bi-LSTM + CRF
- transition-based 方法构建和标注分割
Introduction
NER 的挑战性:
- 大多数领域只有少量标注数据
- 实体的词几乎毫无限制,要从一个小数据集泛化太难
人工设计特征和领域知识在实际中使用广泛,但太耗时且很难迁移;无监督一般又是作为有监督的补充。本文提出的架构与语言和特征无关,模型被设计用来获取两个直觉:
- 实体经常由多个 token 组成,对每个 token 的 tag 进行联合推理很重要。对比了 Bi-LSTM +CRF 和一个新模型(使用了一种灵感来自基于堆栈 LSTM 表示的 transition-based 算法来构造和标记输入句子的 chunks)。
- 实体 token 级别的证据既包括拼写(被标记的单词看起来像什么),也包括分布证据(被标记的单词倾向于出现在语料中哪里)。使用了字符级别的词表示和分布表示。
LSTM-CRF Model
LSTM
这里的 LSTM 和我们平时见的稍微不一样:
它的更新有点像 GRU,输出像 LSTM。
CRF Tagging Models
NER 任务的标签之间相互不独立,CRF 比较合适:
-
给定句子序列:X = (x1, …, xn)
-
P 是 Bi-LSTM 的输出矩阵,n×k,k 是不同 tags 的数量,Pij 表示给定句子第 i 个 token 是第 j 个 tag 的分数
-
对预测序列:y = (y1, …, yn),score 定义如下:
A 是转移分数,Aij 表示 tag i 转移到 tag j 的分数
-
softmax
-
loss function
Yx 表示输入句子 X 所有可能的 tag 序列
-
decoding
Parameterization and Training
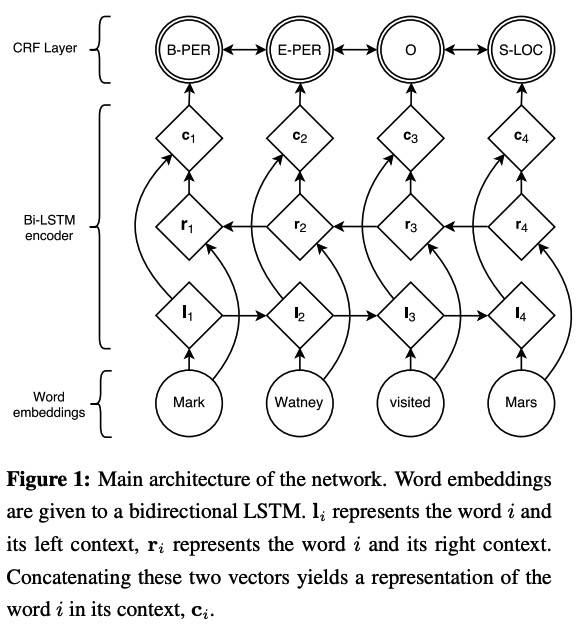
A 和 P 就是参数,c 和 CRF 层加一层能提升效果。训练就是最大化 loss function。
Tagging Schemes
没有用常规的 IOB,而是用了 IOBES,IOB 和常规的一样,S 表示一个 token 是一个实体,E 表示实体的结尾。不过并没有发现比 IOB 有明显的改善。
Transition-Based Chunking Model
这个模型直接对多个 token 的实体构建表示,它依赖 stack 数据结构来增量构造输入块(chunks)。使用了 Stack-LSTM(LSTM + 栈指针)架构,它允许 embedding 一个栈的对象(push 和 pop),看起来就像一个维持对内容 summary embedding 的栈。
关于 Stack-LSTM 的论文:Transition-Based Dependency Parsing with Stack Long Short-Term Memory - ACL Anthology。
Chunking Algorithm

-
两个 stack:output 和 stack,分别表示已完成的 chunks 和暂存空间
-
一个 buffer:包含将要处理的词
包括下面的转移:
- SHIFT 将 word 从 buffer 移动到 stack
- OUT 将 word 从 buffer 移动到 output stack:REDUCE(y) 从栈顶 pop 所有的 item 生成一个 “chunk”,标记为 label y,然后 push 一个这个 chunk 的表示到 output stack。

给定 content 的 stack,buffer 和 output,以及历史 action,针对每一个 time step 上 action 的分布建模。
具体而言,每一个 action 都计算一个固定维度的 embedding,然后 concat 后获得完整的状态表示,这个表示用于定义每个 time step 可能采取的行动分布。模型就是最大化给定输入句子参考 action 序列(从标记语料中提取)的条件概率。预测时,使用贪婪算法选择最大概率的 action。
因为是直接预测 “块” ,所以和使用的标记方法无关。
Representing Labeled Chunks
REDUCE 操作执行时,算法将一个序列的 token 从 stack 移到 output 作为一个 chunk。这个序列的表示用一个 Bi-LSTM 计算,输入是所有 token 的 embedding 加上一个表示 chunk 类型的 token,也就是 g(u, …, v, r),r 就是那个 label 类型的 embedding。最后 output buffer 就只包括一个向量,用来表示每个生成的与长度无关的标记了的 chunk。
Input Word Embeddings
- 字符级别的词表示(关注词的拼写)
- 大规模语料顺序敏感的 embedding(关注在大规模语料上的多变性)
- dropout(防止依赖某一个表示)
Character-based models of words
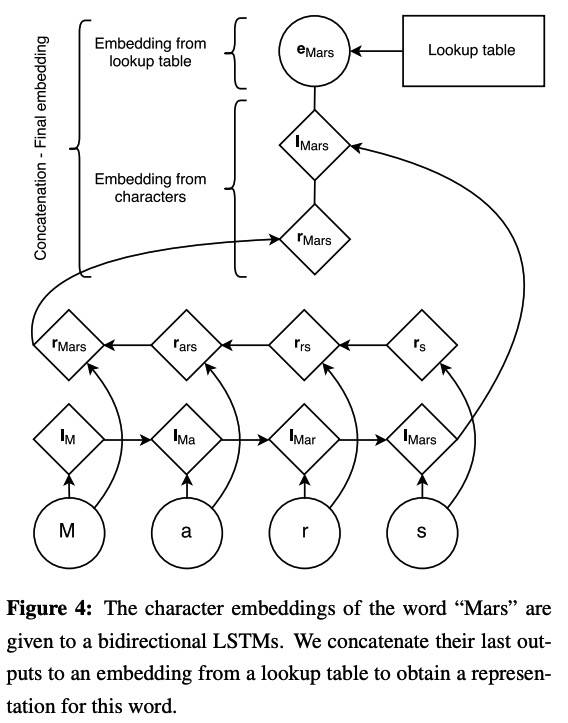
为了训练 UNK,用 UNK 按 50% 的概率替换单例。LSTM 的 hidden dimension 为 25,左右加起来是 50。由于 RNN 倾向于最近的输入,所以期望前向 LSTM 能够表示词的后缀,后向 LSTM 能够表示词的前缀。本文认为重要的信息是位置独立的,使得 LSTM 成为建模词和字母关系的一个很好的先验。
Pretrained embeddings
skip-n-gram(词顺序),训练时候精调。
Dropout training
最后一层 embedding layer(在图 1 的 Bi-LSTM 前)使用一个 dropout mask,模型效果提升显著。
Experiments
Training
BP + SGD + lr 0.01 + gradient clipping 5.0,效果好于 Adam 或 Adadelta
LSTM-CRF 双向都是单层 layer,维度 100,调整维度对模型影响不大,dropout 0.5,高比例负样影响结果,低比例训练时间加长。
Stack-LSTM 双层,维度 100,action 维度 16,output embedding 维度 20。
Dataset
CoNLL-2002, CONLL-2003,四类实体:地名,人名,组织名和杂项,没有使用 POS tag,除了在英文 dataset 上把数字替换成 0 外没有做任何其他预处理。
Results
Stack-LSTM 更加依赖基于字符的表示,猜测是,LSTM-CRF 因为 Bi-LSTM 获得更多的上下文信息因而可能需要较少的拼写信息;而 Stack-LSTM 逐个使用单词,并且对单词 chunk 时仅仅依赖词表示。
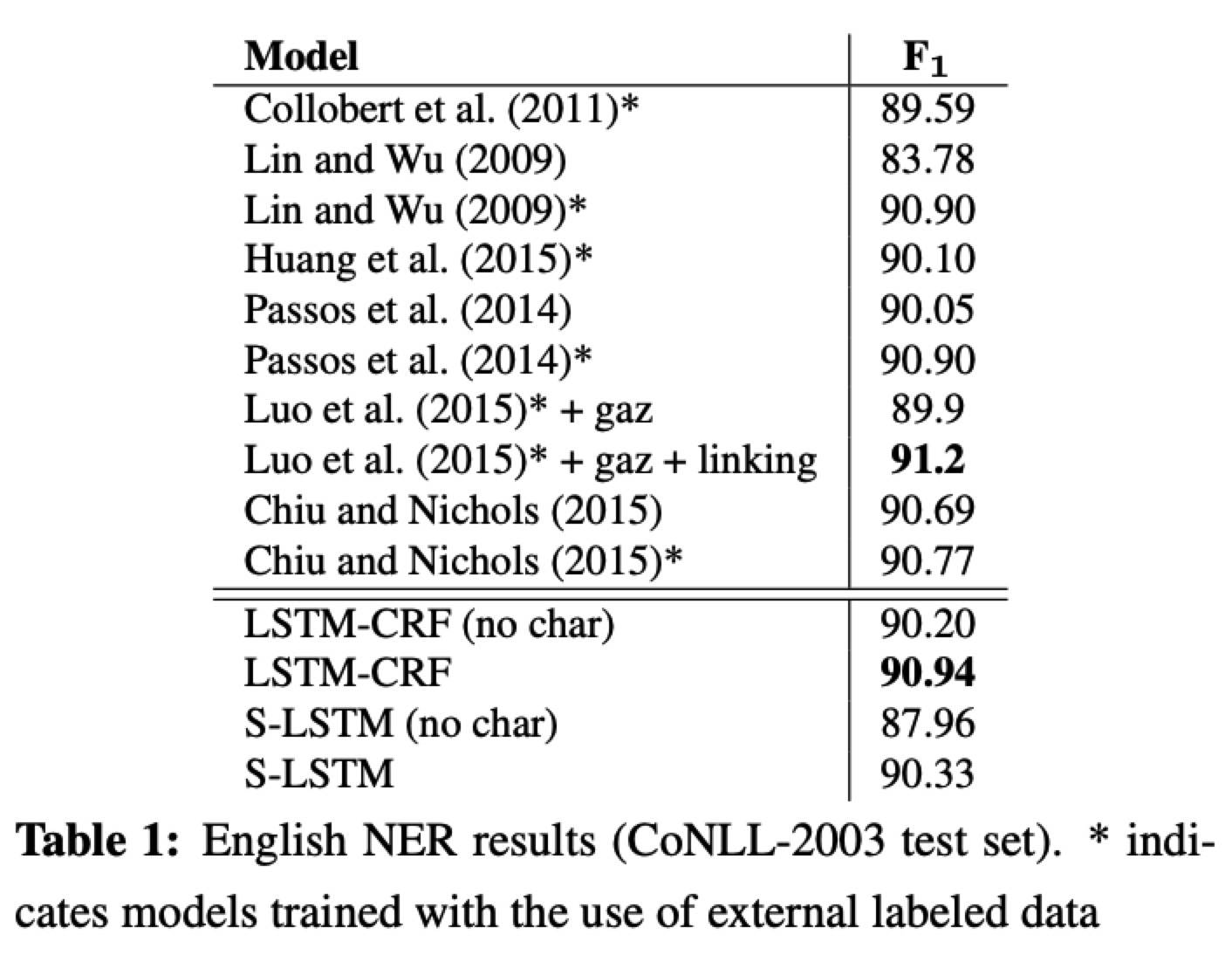
Network architectures

- word embedding +7.31
- CRF +1.79
- dropout +1.17
- character-level word embedding +0.74
Related Work
- Carreras et al. (2002) 组合小的固定深度的决策树
- Florian et al. (2003) 组合四个不同的分类器
- Qi et al. (2009) 大规模语料上使用神经网络无监督学习
神经网络:
- Collobert et al. (2001) 序列词 embedding + CNN + CRF(CRF 首次出现的地方)
- Huang et al. (2015) 和 LSTM-CRF 类似,但使用了人工设计的拼写特征
- Zhou, Xu (2015) 使用了类似模型,并将其用到语义角色标注任务
- Lin, Wu (2009) Linear chain CRF + L2 正则,他们添加了从网络数据中提取的词组聚类特征和拼写特征
- Passos et al. (2014) Linear chain CRF + 拼写特征 + gazetteers
语言独立模型:
- Cucerzan, Yarowsky (1999; 2002) 半监督 bootstrapping,联合训练字符级别和 token 级别的特征
- Eisenstein et al. (2011) Bayesian 非参数几乎无监督的方法构建命名实体数据库
- Ratinov, Roth (2009) 量化对比了一些 NER 方法,使用规范化的平均感知器并汇总上下文信息来构建监督模型
letter-based 表示:
- Gillick et al. (2015) 使用 seq2seq 模型,character-based 表示作为 encoder
- Chiu, Nichols (2015) 与本文结构类似,但使用了 CNN 来学习 character-based 特征
- Santos, Guimaraes (2015) 类上
Conclusion
模型的一个关键点是对 output label 的依赖性建模(CRF 和基于转移的算法);词表示也非常重要,pretrained 词表示和 character-based 表示分别捕获了形态和拼写信息;dropout 用来防止过拟合。