Recently, I wanted to build an information extraction system, so I searched for Google. However there were little Chinese articles, the quality was not so good as well. Fortunately, I found several English ones seemed well, and then the summary is here. The whole structure is based on my favorite NLP book Speech and Language Processing (use SLP instead below), also with some other materials in the reference.
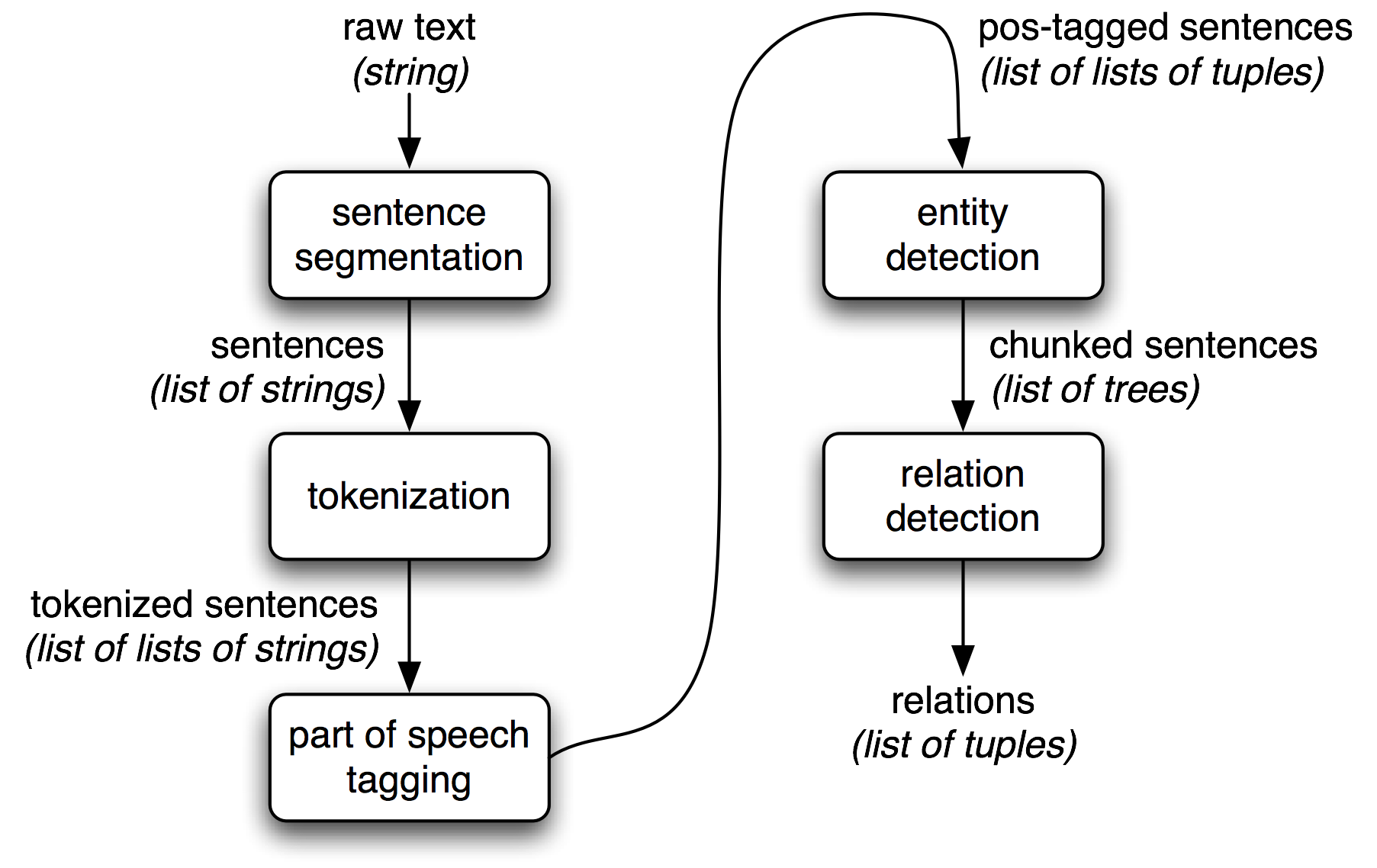
Information extraction (IE), turns the unstructured information extraction information embedded in texts into structured data, for example for populating a relational database to enable further processing. Here is a figure of: Simple Pipeline Architecture for an Information Extraction System.
From: https://www.nltk.org/book/ch07.html
By the way, this book provides actionable steps, focusing on specific actions.
Basic
This part is mainly the basic knowledge, which comes from ch17 of Speech and Language Processing.
Named Entity Recognition
The first step in information extraction is to detect the entities in the text. A named entity is, roughly speaking, anything that can be referred to with a proper name: a person, a location, an organization.
The term is commonly extended to include things that aren’t entities, such as dates, times, and other kinds of temporal expressions, and even numerical expressions like prices.
Named entity recognition means finding spans of text taht constitute proper names and then classifying the type of the entity. The difficulties are:
- ambiguity of segmentation, that’s even serious in Chinese.
- type ambiguity
NER as Sequence Labeling
A sequence classifier like an MEMM/CRF or a bi-LSTM is trained to label the tokens in a text with tags that indicate the presence of particular kinds of entities. Some details of data and training can be found here: 附录 — LTP 3.3 文档
A feature-based algorithm for NER
Typical features for a feature-based NER system:
- identity of wi, identity of neighboring words
- embeddings for wi, embeddings for neighboring words
- part of speech of wi, part of speech of neighboring words
- base-phrase syntactic chunk label of wi and neighboring words
- presence of wi in a gazetteer
- wi contains a particular prefix (from all prefixes of length ≤ 4)
- wi contains a particular suffix (from all suffixes of length ≤ 4)
- wi is all upper case
- word shape of wi, word shape of neighboring words
- short word shape of wi, short word shape of neighboring words
- presence of hyphen
In Chinese, things become a little different, there aren’t many clear features, and Chinese text are always connected together.
For example the named entity token L’Occitane would generate the following noon-zero valued feature values:
1 | prefix(w_i) = L suffix(w_i) = tane |
A gazetteer is a list of place names, often providing millions of entriesfor locations with detailed geographical and political information. A related resource is name-lists, similar lists also contain corporations, commercial products, and all manner of things biological and mineral. While gazetteers can be quite effective, list of persons and organizations are not always helpful.
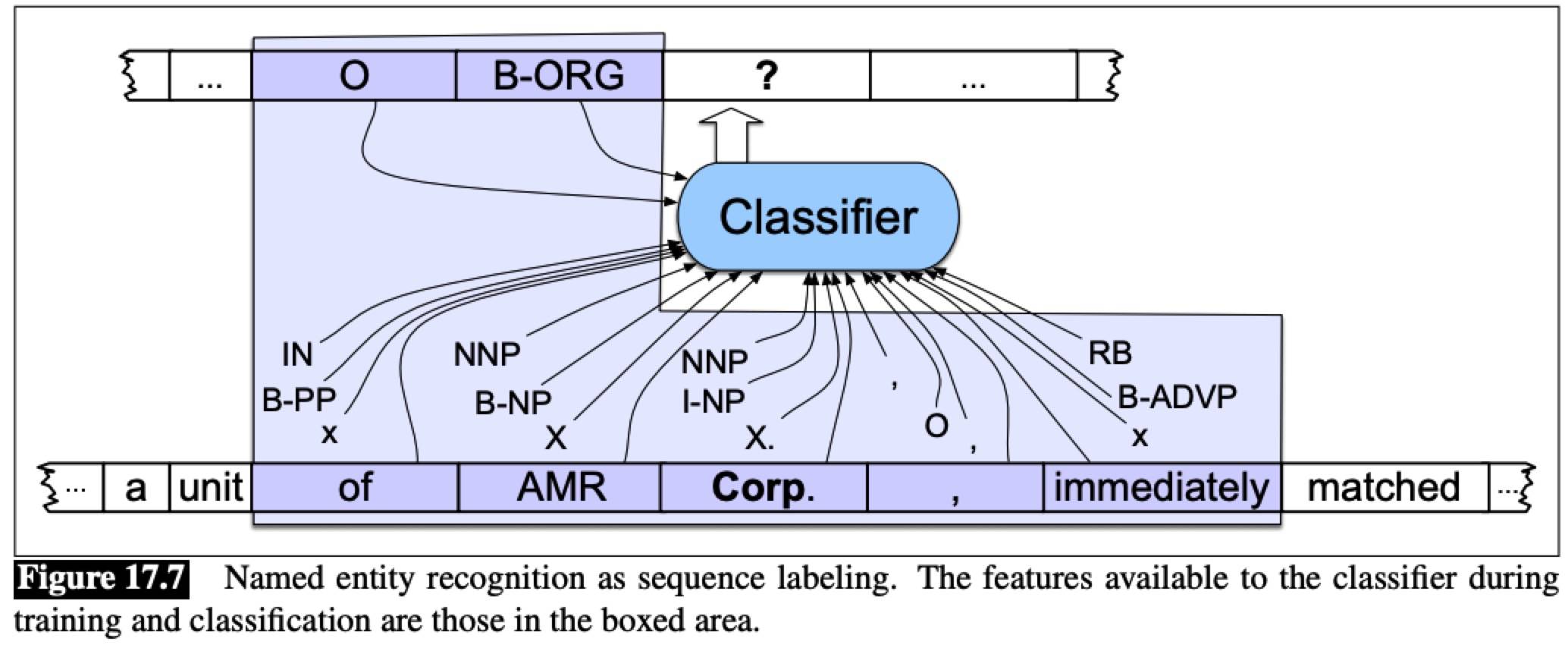
A sequence classifier like an MEMM can be trained to label new sentences. If we assume a context window that includes the two preceding and following words, then the features available to the classifier are those shown in the boxed area.
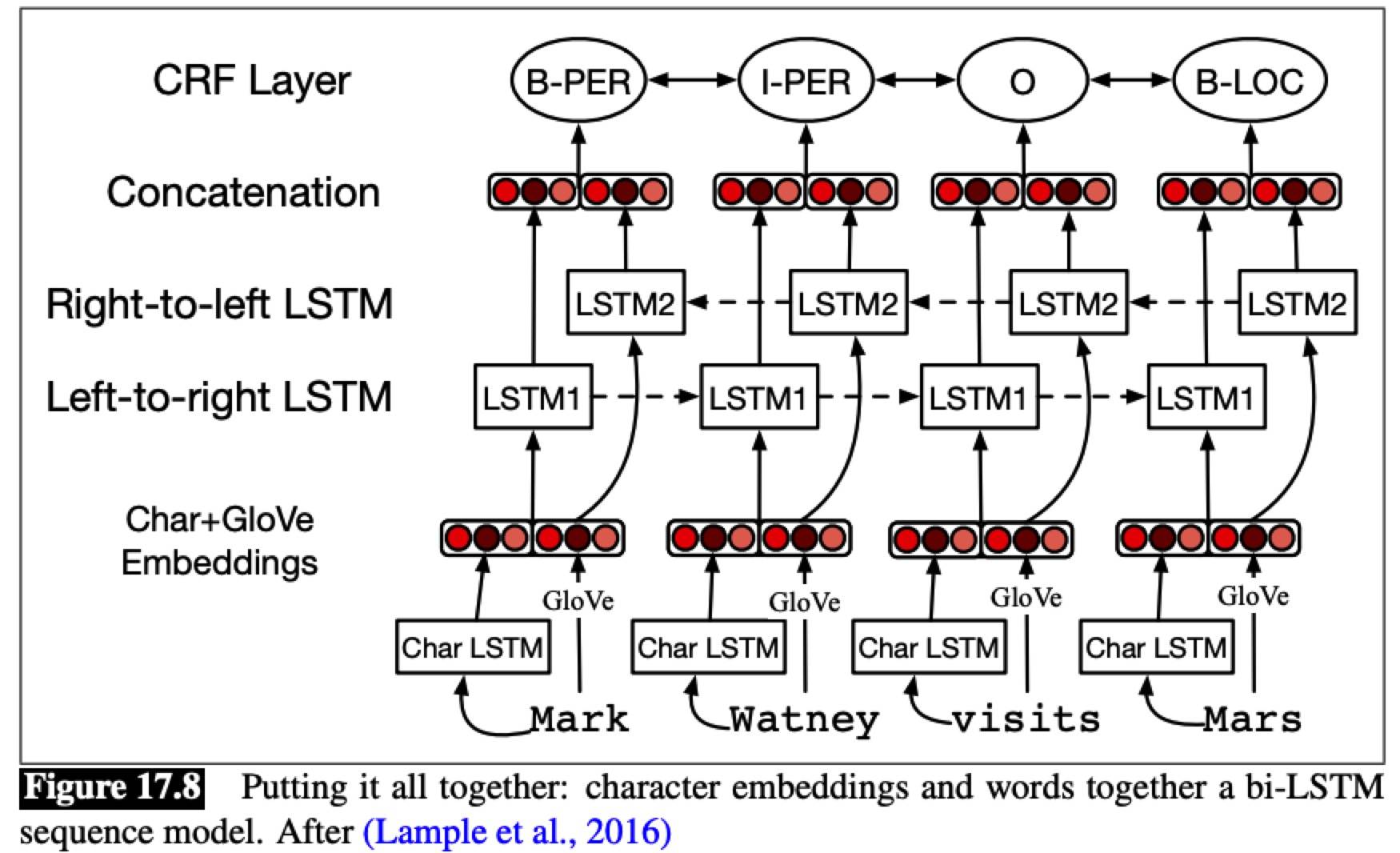
A neural algorithm for NER
A bi-LSTM output a softmax over all NER tags, but it’s insufficient, since it doesn’t allow us to impose the strong constraintsneighboring tokens have on each other. Instead a CRF layer is normally used on top of the bi-LSTM output, and the Viterbi decoding algorithm is used to decode.
Rule-based NER
While sequence models are the norm in academic research, commercial approaches to NER are often based on pragmatic combinations of lists and rules, with smaller amount of supervised machine learning. For example SystemT: Declarative Text Understanding for Enterprise.
One common approach:
- First, use high-precision rules to tag unambiguous entity mentions
- Then, search for substring matches of the previously detected names
- Consult application-specific name lists to identify likely name entity mentions from the given domain
- Finally, apply probabilistic sequence labeling techniques that make use of the tags from previous stages as additional features
Evaluation of Named Entity Recognition
For named entities, the entity rather than the word is the unit of response. The fact that named entity tagging has a segmentation component which is not present in tasks like text categorization or part-of-speech tagging causes some problems with evaluation. For example, a system that labeled American but not American Airlines as an organization would cause two errors, a false positive for O and a false
negative for I-ORG.
Relation Extraction
An RDF triple is a tuple of entity-relationentity, called a subject-predicate-object expression.
- DBpedia is an ontology derived from Wikipedia containing over 2 billion RDF triples.
- Data Dumps | Freebase API (Deprecated) | Google Developers
- WordNet | A Lexical Database for English or other ontologies offer useful ontological relations that express hieris-a archical relations between words or concepts.
Using Patterns to Extract Relations

-
Advantage: high-precision and can be tailored to specific domains
-
Disadvantage : low-recall and a lot of work to create them for all possible patterns
Relation Extraction via Supervised Learning
The most straightforward approach has three steps:
- Find pairs of named entities (usually in the same sentence)
- A filtering classifier is trained to make a binary decision as to whether a given pair of named entities are related
- A classifier is trained to assign a label to the relations that were found by step 2
For the feature-based classifiers like LR, RF, the most important step is to identify useful features. Consider features for classifying the relationship between American Airlines (M1) and Tim Wagner (M2) from the sentence: “American Airlines, a unit of AMR, immediately matched the move, spokesman Tim Wagner said”.

Labeling a large training set is extremely expensive and supervised models are brittle: they don’t generalize well to different text genres. So much research has focused on the semi-supervised and unsupervised approaches.
Semisupervised Relation Extraction via Bootstrapping
Suppose we just have a few high-precision seed patterns or a few seed tuples, that’s enough to bootstrap a classifier.
1 | function BOOTSTRAP(Relation R) returns new relation tuples |
Bootstrapping systems assign confidence values to new tuples to avoid semantic drift.
Given a document collection D, a current set of tuples T, and a proposed pattern p, we need to track two factors:
- hits: the set of tuples in T that p matches while looking in D
- finds: the total set of tuples that p finds in D
We can assess the confidence in a proposed new tuple by combining the evidence supporting it from all the patterns P’ that match that tuple in D. One way to combine such evidence is the noisy-or technique.
Assume that a given tuple is supported by a subset of the patterns in P, each with its own confidence assessed as above.
In the noisy-or model, we make two basic assumptions. First, that for a proposed tuple to be false, all of its supporting patterns must have been in error, and second, that the sources of their individual failures are
all independent.
If we loosely treat our confidence measures as probabilities, then the probability of any individual pattern p failing is 1−Conf(p); the probability of all of the supporting patterns for a tuple being wrong is the product of their individual failure probabilities, leaving us with the following equation for our confidence in a
new tuple.
Setting conservative confidence thresholds for the acceptance of new patterns and tuples during the bootstrapping process helps prevent the system from drifting away from the targeted relation.
Distant Supervision for Relation Extration
It combines the advantages of bootstrapping and supervised learning, uses a large dataset to acquire a huge number of seed examples, creates lots of noisy pattern features from all these examples and then combines them in a supervised classifier.
1 | function DISTANT SUPERVISION(Database D, Text T) returns relation classifier C |
Distant supervision can only help in extracting relations for which a large enough database already exists. To extract new relations without datasets, or relations for new domains, purely unsupervised methods must be used.
Unsupervised Relation Extraction
The goal of unsupervised relation extraction is to extract relations from the web when we have no labeled training data, and not even any list of relations. This task is often called open information extraction or Open IE.
The ReVerb - Open Information Extraction Software system extracts a relation from a sentence s in 4 steps:
- Run a part-of-speech tagger and entity chunker over s
- For each verb in s, find the longest sequence of words w that start with a verb and satisfy syntactic and lexical constraints, merging adjacent matches.
- For each phrase w, find the nearest noun phrase x to the left which is not a relative pronoun, wh-word or existential “there”. Find the nearest noun phrase y to the right.
- Assign confidence c to the relation r=(x, w, y) using a confidence classfier and return it.
A confidence classifier is then trained on this hand-labeled data, using features of the relation and the surrounding words.
The disadvantage is the need to map these large sets of strings into some canonical form for adding to databases or other knowledge sources. Current methods focus heavily on relations expressed with verbs, and so will miss many relations that are expressed nominally.
Evaluation of Relation Extraction
Semi-supervised and unsupervised methods are much more difficult to evaluate, since they extract totally new relations from the web or a large text. It’s possible to approximate (only) precision by drawing a
random sample of relations from the output, and having a human check the accuracy of each of these relations.
-
Only want to know if the system can discover and don’t care how many times it discovers
-
Another approach that gives us a little bit of information about recall is to compute precision at different levels of recall. Assuming that our system is able to rank the relations it produces (by probability, or confidence) we can separately compute precision for the top 1000 new relations, the top 10,000 new relations, the top 100,000, and so on.
Extracting Times
Times and dates are those temporal expressions, must be normalized —— converted to a standard format.
Temporal Expression Extraction
Temporal expressions are those that refer to absolute points in time, relative times, durations, and sets of these.
Temporal expressions are grammatical constructions that have temporal lexical triggersas their heads. Lexical triggers might be nouns, proper nouns, adjectives, and adverbs; full temporal expressions consist of their phrasalprojections: noun phrases, adjective pharases, and adverbial phrases.
Noun: morning, noon, night, winter, dusk, dawn
Proper Noun: January, Monday, Ides, Easter, Rosh Hashana, Ramadan, Tet
Adjective: recent, past, annual, former
Adverb: hourly, daily, monthly, yearly
Rule-based approaches to temporal expression recognition use cascades of automata to recognize patterns at increasing levels of complexity.
Sequence-labeling approaches follow the same IOB schema used for named-entity tags. Features are extracted from the token and its context. Tipical features used to train IOB-style temporal expression taggers:
- Token: The target token to be labeled
- Tokens in window: Bag of tokens in the windown around a target
- Shape: Character shape features
- POS: Parts of speech of target and window words
- Chunk tags: Base-phrase phrase tag for target and words in a window
- Lexical triggers
A major difficulty is avoiding expressions that trigger false positives:
- 1984 tells the story of Winston Smith
- U2’s classic Sunday Bloody Sunday
All these above are suitable for Chinese.
Temporal Normalization
Temporal normalization is the process of mapping a temporal expression to either temporal normalization a specific point in time or to a duration.
Normalized times are represented with the VALUE attribute from the ISO 8601 standard for encoding temporal values.
Most temporal expressions in news articles are incomplete and are only implicitly anchored, often with respect to the dateline of the article, which we refer to as the document’s temporal anchor. Relative temporal expressions are handled with temporal arithmetic similar to that used for today and yesterday. Such ambiguities are handled by encoding language and domain-specific heuristics into the temporal attachments.
Extracting Events and their Times
Event extraction is to identify mentions of events in texts. Events are to be classified as actions, states, reporting events (say, report, tell, explain), perception events, and so on. Supervised learning for sequence models with IOB tagging. Common features like:
- Character affixes: Character-level prefixes and suffixes of target word
- Nominalization suffix: Character level suffixes for nominalizations (e.g., -tion)
- Part of speech: Part of speech of the target word
- Light verb: Binary feature indicating that the target is governed by a light verb
- Subject syntactic category: Syntactic category of the subject of the sentence
- Morphological stem: Stemmed version of the target word
- Verb root: Root form of the verb basis for a nominalization
- WordNet hypernyms: Hypernym set for the target
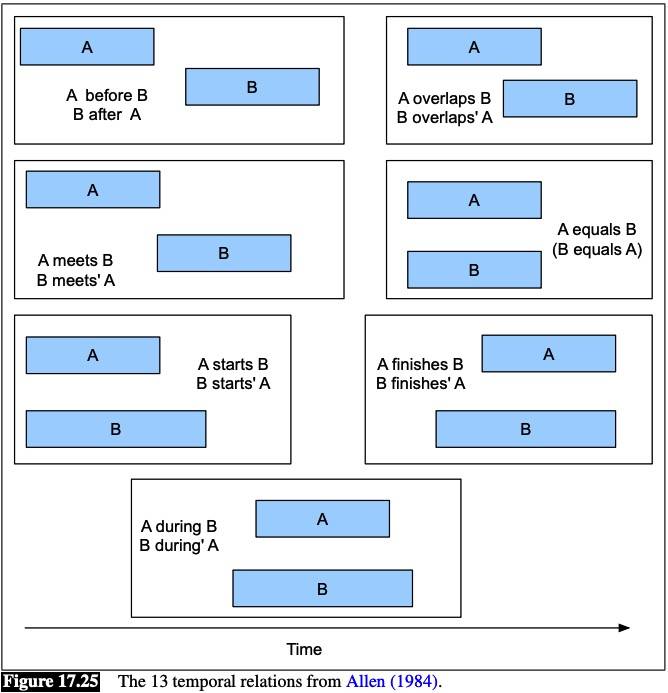
Temporal Ordering of Events
The temporal relation between events is classified into one of the Allen relations standard set.
Template Filling
Template filling is to find documents that invoke particular scripts and then fill the slots in the associated templates with fillers extracted from the text. These slot-fillers may consist of text segments extracted directly from the text, or they may consist of concepts that have been inferred from text elements through some additional processing.
Machine Learning Approaches to Template Filling
Two supervised systems:
- Template recognition: decides whether the template is present in a particular sentence
- Features extracted from every sequence of words that was labeled in training documents as filling any slot from the template being detected.
- The usual set of features can be used: tokens, embeddings, word shapes, part-of-speech tags,
syntactic chunk tags, and named entity tags.
- Role-filler extraction: detects each role (DATE, AMOUNT, and so on)
- Run on every noun-phrase in the parsed input sentence, or a sequence model run over sequences of words.
- The usual set of features can be used.
Recent work focuses on extracting templates in cases where there is no training data or even predefined templates, by inducing templates as sets of linked events: Template-Based Information Extraction without the Templates.
Earlier Finite-State Template-Filling Systems
Early systems for dealing with complex templates were based on cascades of transducers based on hand-written rules.
The first four stages use hand-written regular expression and grammar rules to do basic tokenization, chunking, and parsing. Stage 5 then recognizes entities and events with a FST-based recognizer and inserts the recognized objects into the appropriate slots in templates. The merging algorithm, after performing coreference resolution, merges two activities that are likely to be describing the same events.

This is an example of FASTUS: A Cascaded Finite-State Transducer for Extracting Information from Natural-Language Text.
Summary
-
Named entities can be recognized and classified by featured-based or neural sequence labeling techniques.
-
Relations among entities can be extracted by pattern-based approaches, supervised learning methods when annotated training data is available, lightly supervised bootstrapping methods when small numbers of seed tuples or seed patterns are available, distant supervision when a database of relations is available, and unsupervised or Open IE methods.
-
Reasoning about time can be facilitated by detection and normalization of temporal expressions through a combination of statistical learning and rulebased methods.
-
Events can be detected and ordered in time using sequence models and classifiers trained on temporally- and event-labeled data like the TimeBank corpus.
-
Template-filling applications can recognize stereotypical situations in texts and assign elements from the text to roles represented as fixed sets of slots.
Practice
This post provides industrial level content and also an overall framework.
The NLTK Book provides a practical tutorial.
This post provides an example of specific information extraction from unstructured texts (CVs). The steps are below:
- Parts of speech tagging
- using NLTK library
- use a regular expression or model to extract noun phrases examples
- results with a number of entities among which some are the target skills and some are not
- DeepLearning for candidates classification
- train a model with a labeled training set
- The set of features used for training is composed regarding the structure of the candidate phrase and the context.
- Each word’s vector is comprised of such binary features as occurrence of numbers or other special characters, capitalization of the first letter or of the whole word.
- Also check if a word appears in the English language vocabulary and in some thematic lists such as names, geographical names, etc.
- Usage of another binary feature describing presence of the popular English prefixes and suffixes in a candidate.
- The classification has three input layers each designed to take special class of data
- features of candidate phrases
- context structure information: 3 neighbouring words to the left and right of candidate phrase respectively
- coordinate wise maximum and minimum values of word vectors in the phrase and its context which, among the other information, represent the presence or absence of many binary features in the whole phrase.
I was a little confused about the input layers, and I’ve posted a question.
Appendix
Reference
- Speech and Language Processing
- 7. Extracting Information from Text
- Natural Language Processing (NLP) Techniques for Extracting Information | Search Technologies
- Deep learning for specific information extraction from unstructured texts
- [1807.02383] Natural Language Processing for Information Extraction
Repos
Application level:
- snipsco/snips-nlu: Snips Python library to extract meaning from text
- machinalis/iepy: Information Extraction in Python Focused on Relation Extraction
Non-DeepLearning:
- marcolagi/quantulum: Python library for information extraction of quantities from unstructured text
- gabrielStanovsky/template-oie: Extract templated Open Information Extraction
- information-extraction: based on Stanford open IE Library and domination decision rules
DeepLearning (Suitable for study):
- Information-Extraction-Chinese/RE_BGRU_2ATT at master · crownpku/Information-Extraction-Chinese
- An Open-Source Package for Neural Relation Extraction (NRE) implemented in TensorFlow
- PyTorch implementation of the position-aware attention model for relation extraction
Dataset:
- davidsbatista/Annotated-Semantic-Relationships-Datasets: Public and free annotated datasets of relationships between entities/nominals
- TimeBank
CHANGELOG
- 20190402 Created