2018 全球人工智能与机器人峰会(CCF-GAIR)NLP 专场,云孚科技创始人兼 CEO 张文斌;竹间智能 CTO 翁嘉颀;神州泰岳大数据 VP 张瑞飞;薄言 RSVP.ai 联合创始人 CTO 熊琨 带来的分享笔记摘录,文字稿来自:AI 科技评论:自然语言处理可以这样商业落地。
公司概览
云孚科技
专注于为企业提供自然语言处理技术解决方案。
-
NLP 的特点
-
来自各行业客户的真实需求非常多
-
难度非常大,尤其是中文:

-
-
NLP 商业化
- 2C
- 2B
- 垂直行业的应用
- 基础技术平台
-
云孚科技的架构
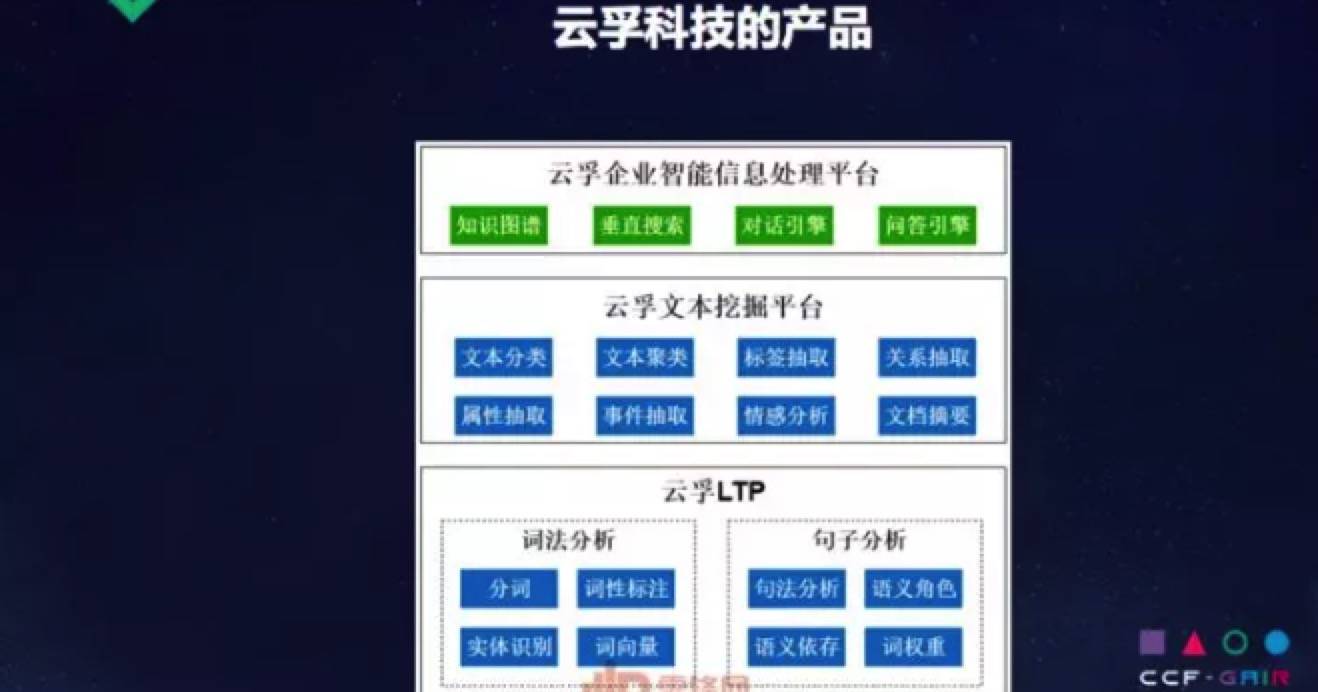
创业公司的核心不是提出新的模型和算法,我们是结合学术界最好的模型和算法,从工程、数据角度,把效果优化到理想程度。
云孚的战略总结起来就是:「先横后纵、自底向上」——先做横向的、底层的技术平台,再做纵向的、上层的行业应用。
竹间智能
公司主要是做情感计算和文本分析、自然语义理解,情感计算。不只做文本情感,还做语音情绪和表情。
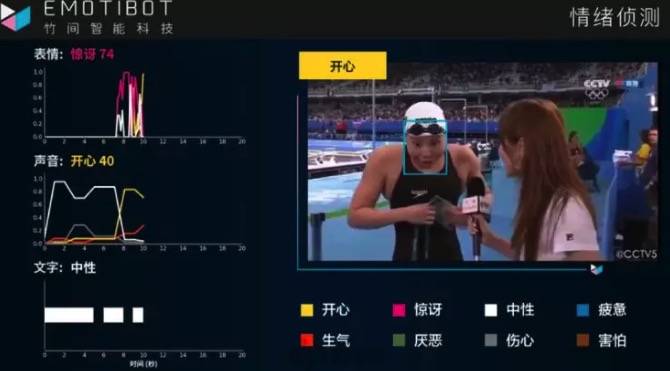
傅园慧说「在澳洲训练非常辛苦,我已经快死了,简直是生不如死」,「鬼知道我经历了什么,我太累了」
目前人工智能必须从单个到单独的领域去突破,去那个领域先收集语料,以及到底要解决什么问题,针对这一类问题我能解决哪些?
比如订酒店,今天我要订酒店,我可能会说「我要订万豪酒店旁边的快捷酒店」,如果抓关键词的话,会以为我要订万豪酒店。再比如订餐,我大概有七八个大人再加两个小孩,七八个大人是七十八个人还是八个人?再比如说「几点」?六、七点,不不不,改成八点好了。那么到底是几点?
希望未来每个人有自己的机器人,你的机器人能理解你,记得你,我跟手环或机器人说「帮我点个外卖吧,我肚子饿了」,它能记得我喜欢吃什么、不喜欢吃什么,而且它知道我昨天吃过什么、前天吃过什么,不要点重复的东西。每个企业都应该有点餐机器人,可以做智能客服的回答。未来我们还可以跟机器人交流,比如我跟手环说「帮我点个巨无霸吧」,它知道这是麦当劳的产品,会找到麦当劳的机器人,两个机器人对话,帮我搞定。
神州泰岳
大数据及人工智能公司。
- 解决算法、数据和算力这三个数据时,肯定先搞定数据
- 工程化的第二步,也就是怎样在成本成效中有所取舍
- 迁移学习
- 把人类已有的知识结构和语言结构和深入学习进行融合
把概念单元、把 3192 个句类、语境单元和记忆标好,实现有限和无限之间的哲学关系,概念是无限的,但概念单元是有限的,语句是无限的,但句类是有限的,语境是无限的,但语境单元是有限的。把已有的结构化知识或者图的知识结构,就是用人脑可以分析的知识结构直接融入到神经网络中,在算法中把它适配和协调起来,这样算法落地时才准,准是你能使用的非常高的影响力,它也是能要到钱的基础。
薄言 RSVP.ai
公司的初衷就是希望让机器了解语言,自动帮人做一些关于语言的事情。
-
任务型自然语言理解:希望深度学习网络不仅仅给出概率分布,还希望给出图状结构,能够解决文法表达的问题。
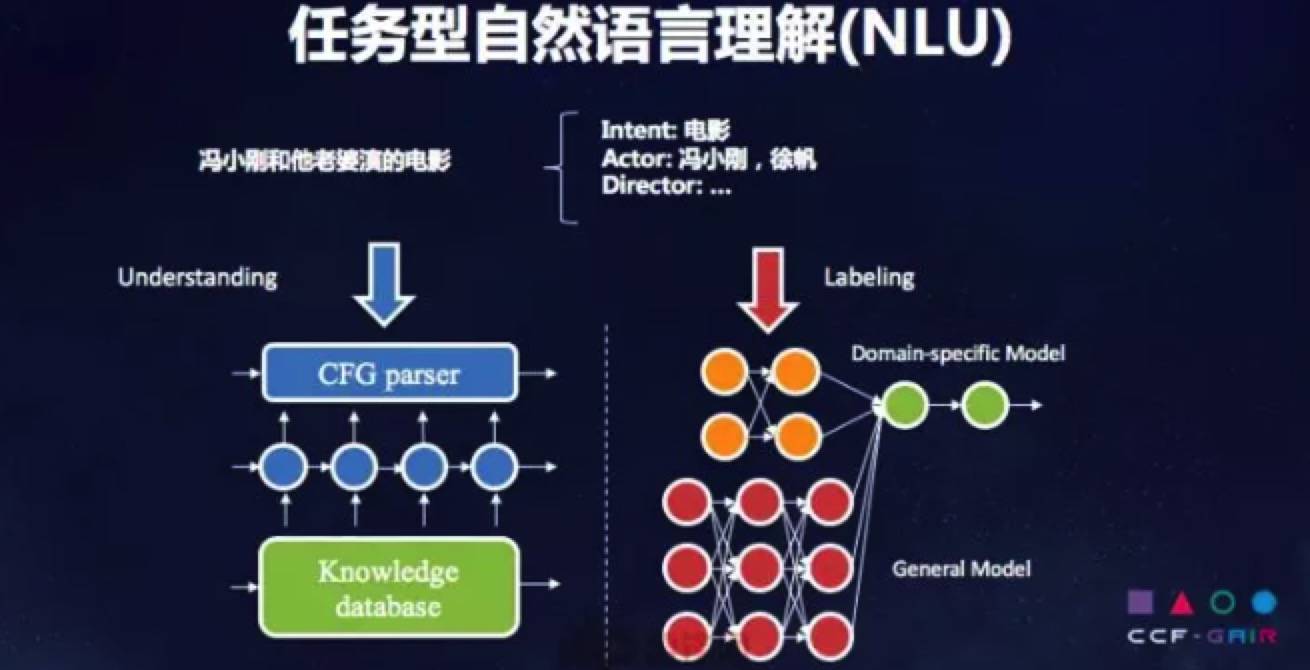
-
对话型理解
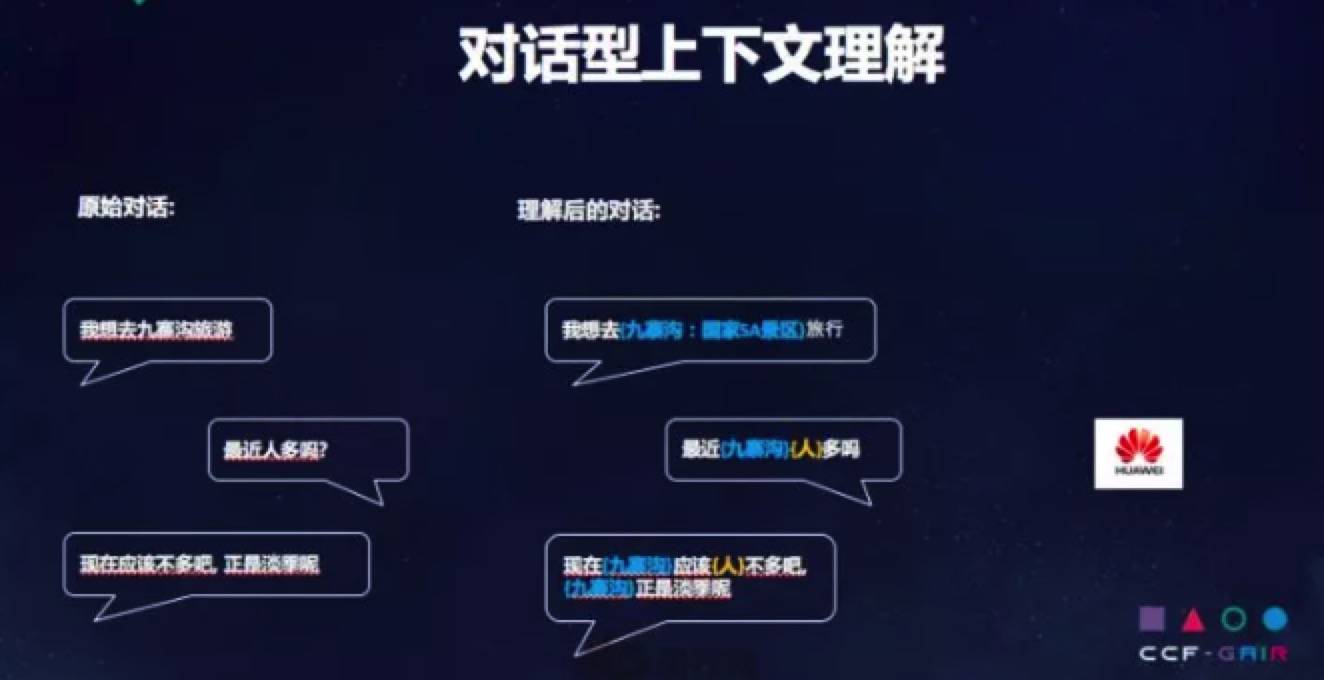
技术讨论
NLP 落地的技术鸿沟
- 就算分词这么成熟的技术,落到特定行业,面对一些新词,效果还是不足够理想,还需要花很多精力去做针对特定领域去做优化。
- 短文本、短句 15 个字以内,意图理解、意思理解可能没有什么问题,长文本目前还不太行。
- 把视觉中已经取得的技术,比如 DCN 技术应用在文本中,如舆论控制。
- 算法通用问题(把算法做得特别深,往往有普适性的问题,如果做平台,往往做深入就会有困难);
- 模型迁移问题(新的领域的训练语量没有那么多,但又有各自领域自己的知识和特点,这个时候通用的数据集怎么达到更好的效果?)
- 成本问题
需要重点解决的问题
-
短文本相似度(同样的文本可能意思不同)
-
标注好的数据
-
如何做好对话控制,如何限制用户讲话方式
-
非结构化文本存在,怎么在这上面把他们想要的结构化信息抽取出来,抽取完再构建这个行业的知识图谱。一般可以先用已有的通用系统结合基于规则的方法先做一版系统出来,这样可以先跑一个初步结果,从中挑一部分比较严重的 badcase 出来,人工标注语料,再重新训练模型,如此反复迭代。总之,怎么样用尽可能少的标注语料,可以快速迁移领域是一个非常实际的问题。
一些建议
- 首先,搭建一套统一的基准平台,先给算法和数据分别定义好统一的接口,然后就能很方便地替换成算法或模型以及数据进行效果测试,这样就可以快速尝试新的算法模型,到底在特定任务上效果怎么样,纯粹根据效果来挑选最终适合这个任务的整体模型方案。其次,真正用这些算法做预测时,我们还得考虑它的性能,在正式场合,包括它需要的硬件条件是否符合业务需求。
- 内部要有自己的测试集和标准,对于新的方法能够快速适应和尝试。
对 NLP 的思考
这篇文章看了两遍,颇有些感触和收获,将一些思考记录如下。
NLP 商业化思路
-
垂直行业应用。
这点听很多大佬讲过,因为通用的由于涉及不同业务场景、背景知识、数据等导致太难做,只能退而求其次,在一个领域做精,再将方法迁移至其他领域,比如神州泰岳。
-
专业应用服务。
这个是把 NLP 中的某一领域做到极致,这种极致不仅包括在该领域技术水平领先,同时还能与其他不同领域的技术结合,比如竹间智能的情感分析除了文本,还有语音、表情等。当然,也有在特定领域做垂直行业应用的,比如薄言的自然语言理解。
-
基础服务。
主要是做底层的技术平台,以及在此基础上提供一些对外的应用服务接口。比如云孚科技,他们的基础 LTP 服务以及信息抽取、知识图谱等都是相对底层的。这种服务可以做到模型、服务统一,数据定制。
-
相关配套服务。
从这简单的分类可以看出 NLP 领域巨大的市场,NLP 自身多个领域触及到各个行业都有应用场景。从数字到图像、声音再到自然语言,数据维度越来越复杂,非结构程度越来越高,抽象程度越来越高。难怪人们都说 NLP 是 AI 的皇冠,NLP 即便不是 AI 的终极任务,也一定是其中最重要的任务。
NLP 体系设计
本部分将简单讨论下 AI 自然语言处理商业化(以下简称 NLP)体系设计架构,希望能做到模块化、层次化,以便为不断增加的 NLP 业务提供服务保障。其实云孚科技的架构我觉得非常值得参考,即使我们做的是自然语言处理的其他领域。在公司虽然只做了几个小项目,但还是有些感触,现在将自己的一些体验和心得分享一下,希望能和 NLP 友们交流。
-
分层
随着项目的增加,慢慢会发现几乎所有项目都会用到分词、词性标注、句法分析、词向量等自然语言处理底层的东西,尤其是分词和词向量。一开始是把这些服务包直接 import 进来,但是当项目增加时就很浪费资源(特别是词向量,很占内存),而且一旦某个地方有一些调整或更新,所有项目都要改。所以自然而然就想到单独把这些常用的底层的东西做成独立的服务,统一对外提供接口。
- 提供服务有两种方式,一种是作为 RESTFUL API 提供,另一种是用 RPC,这两种方式没有特别的好坏,经过测试 RPC 可能稍微快一点点。
- 有个小的注意点是,传给服务时尽量不要把请求分割的太小,尤其是词向量。我们在请求词向量时可以传入一个词的 list,返回每个词对应的词向量,这样可以减少请求次数,相对的能提高速度。
- RPC 有很多种选择,我们最后选择 Google 制造:grpc / grpc.io,除了那么一点点情怀,还有懒,不想去看其他的了。
- 服务端的语言,本来就只会 Python,不过最终选择用 C++ 和 Cython,Python 的速度还是慢了不少。不同项目需要加载不同的模块和自定义词典,甚至不同的词向量模型,这些东西最好作为参数传递。
-
基准
这点云孚科技的创始人兼 CEO 张文斌张总在分享中强调过:“建议搭建一套统一的基准平台,先给算法和数据分别定义好统一的接口,然后就能很方便地替换成算法或模型以及数据进行效果测试,这样就可以快速尝试新的算法模型,到底在特定任务上效果怎么样,纯粹根据效果来挑选最终适合这个任务的整体模型方案。”
我们的经验觉得这点特别重要,因为很多时候你要实现一个效果可能会有很多种不同的方案,不同方案内部的不同部分还可以互相组合,有时候你甚至还会突发奇想改变其中的某个部分。这时候要是没有基准就好比航海中没有指南针一样,你无法选择模型,你对模型做了一些创新也不知道效果如何(效果不好的话所谓的创新也就没有什么意义)。恰巧前段时间听百度 2018 AI 大会《深度学习前沿技术与工业应用公开课》分享时也提到他们内部有一套基准平台。
-
数据
这点在薄言创始人 CTO 熊琨的分享中提到过:“公司内部要有自己的测试集和标准,对于新的方法能够快速适应和尝试。”其实基准的设计中就包括数据,百度的分享中提到他们用的是公开的数据集,如果你的项目恰好没有公开能用的数据集,就只能自己构建一份。我们现在的每个项目在写完算法设计稿后的第一个工作就是整一份数据集出来。当然这个数据集包括了训练数据和测试数据,有了数据之后才能对各种算法进行试验。
另外,数据很多时候对公司来说是至关重要的。在目前这种氛围下,算法基本没有什么特别的秘密,大家都抢着发 Paper,很多还有现成的代码。那核心竞争力就主要体现在了数据上,你有某个领域的数据积累,别人没有就很难进来,哪怕你的算法模型差了点。所以,可以说数据就是最大的资产。而且,好的数据也能直接提升模型的效果。
以上就是一些关于 NLP 体系方面的思考,其实我们老板很早之前就让我们对 NLP 领域按模型、任务和专题梳理。专题类似于项目,可能用到多种模型和任务组合;任务主要是分词、分类、生成等等,特别注意搜集对应的公开数据集;模型则是各种如 Ngram,DNN,RL,GAN,Seq2Seq 等经典模型。