这是一篇来自 Google 的研究结果,通过一定的方法和策略,比如多个预训练模型结合,进一步提升模型整体推理能力。本文主要是对这方面的研究做了一个整体统一的划分,包括:思维链(Chain-of-Thought),验证器(Verifiers, STaR)选择-推理(Selection-Inference),工具使用(Tool Use)等,这些统称为:语言模型级联(Language Model Cascades)。
背景介绍
关于单个/多个模型交互,一般会用在信息推理、数学题等方面,主要方法包括:
-
Scratchpads【1】:Google 出品,针对复杂多步计算,通过不断给出中间结果,一步一步引导模型完成任务。
-
Chain-of-Thought【2】和【3】:Google 出品【2】针对复杂推理,给它拆成一系列步骤。Google 出品【3】采用了 Self-Consistency 取代原来的 Naive Greedy 解码策略:每次采样一组推理路径,但不根据贪婪选择,而是选择最一致的那个。
-
Learned Verifiers【4】:OpenAI 出品,使用验证器评判模型结果来处理多步数学推理问题,感觉和 HF 一样有点黑盒的意思。推理时也是生成一堆候选,然后用验证器排序并选择 Top1。
-
Selection-Inference【5】:DeepMind 出品,也是解决多步逻辑推理问题,与 CoT 不同的是,这里采用了和 CoT 的流程(如下):
1
[c, q, r, a] × k(k-shot) + [c, q] → generated [r, a]
不同的另一个流程(如下,注意:「只是一步推理」)——选择-推理框架:
1
2
3
4
5
6
7
8
9
10
11
12# Step1: Selection
[c, q, s(r)] × k(k-selection-shot) + [c, q] → [s]
# Exampe of s
< fact >. We know that < fact >[ and < fact >]*. Therefore ,...
# Step2: Inference
[s(r), i(new_f)] × k(k-inference-shot) + [s] → [i]
# Example of prompt
< fact >. We know that < fact >[ and < fact >]*. Therefore , < new fact> .
# Loop until gets the answer, or fixed number of loops
[c] = [c] + [i]其中,c 表示 context,q 表示 question,a 表示 answer,r 表示 reason,i 表示 inference,f 表示 fact。注意,k-shot 使用的 Prompt 中的 c(或其他内容)与给定的 c 没关系。
可以看到,这比 CoT 细粒度的多,不光流程拆分了,步骤都拆成循环了。值得注意的是,为了防止模型编造事实影响实际推理(因为生成不受控制),Selection 时会对生成的 selection 中的 facts(会生成多个 facts)进行打分并选择得分最高的,新的 fact 会被添加到之前的 Prompt 后面继续生成,直到完整的 Selection 被构建好(论文采取了固定数量步数),请仔细阅读上面的例子;Inference 时选择生成的第一句作为新 fact,添加到 context 中。
-
Bootstrapping【6】:Stanford +Google 出品,这个有点不太一样,它采用的是自学习方式。在回答 Q 时(使用一些理由作为 Prompt),它会生成一些合理的理由,对于最终答案正确的,会被用来 fine-tuning 模型;如果是错误的,则根据正确的答案再生成一条理由。重复上述过程。可以看出这个过程其实可以看作是把 CoT 这个过程给升级了。
本文使用 PPL(概率编程语言)框架,并将其扩展到使用字符串——使用 PPL 来定义字符串值随机变量的联合概率模型,使用 LM 进行参数化,然后根据字符串值观测值对模型进行条件化,以计算字符串值未知数的后验,然后可以对其进行推断。这样的概率程序被称为「语言模型级联」,这个框架可以囊括近期的许多方法,并且还可以解决更复杂的推理问题。
模型级联
级联是一个包含字符串随机变量,从 LM 中采样的概率程序。具体的 case 可以阅读原文附录 A,我们直接看本文是如何进行统一的。
注意:下面每个部分和上面的不一定完全吻合,下面说的具有一定抽象概括性。
中间结果和思维链
建模 P(A|Q) 优化为 P(A|(q, t, a)),其中 (q, t, a) 是 Prompt,示例如下:
1 | def qta(): |
半监督学习
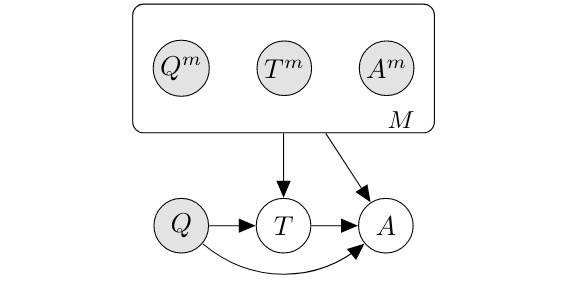
更具扩展性的是先给一个 (Q, T, A) 三元组小数据集,然后给一个 (Q, A) 大数据集,可以通过添加隐变量 T 来完善大数据集的三元组。这是典型的半监督方式。如下图所示:
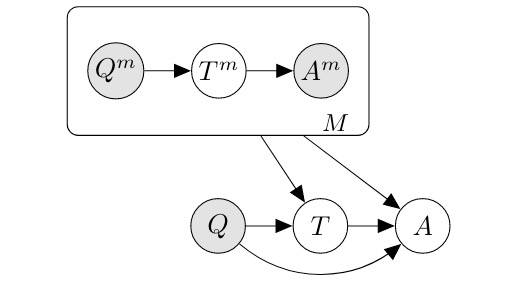
选择-推理
将推理分成选择-推理两个模块,选择模块选择一组事实,推理模块据此推理出新的事实。如下图所示:
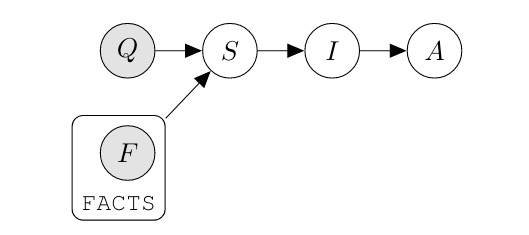
验证器
对 answer 或 thought 的有效性进行验证。这在可能有多种方法推导答案的环境中特别有用。
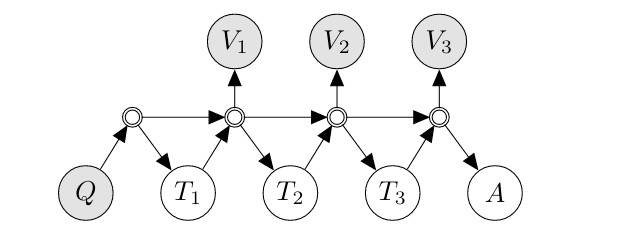
如上图所示,双环节点是确定性缓冲区节点,它们拼接输入,累积过去字符串。其他节点都是随机的,验证器用来「观察」正确值。
工具使用
上面讨论的涉及一个模型,以及一些内部控制流,但没有外部反馈。工具的使用主要是增加与外部系统的交互,比如用 LM+计算器做数学任务。
相关讨论
展望
可以在当前框架中扩展很多规划和 RL 任务,通过使用控制角度作为推理;也可以将字符串扩展为多模态。
实际中应用模型级联的一个挑战是使用字符串值变量在模型中进行概率推理的难度。核心技术挑战是推理效率,经常是 PPL,这里可以将 LM 作为建议的分布或引导网络。
最新的进展是搜索解决目标任务的级联,而不是假设固定的概率程序结构。
小结
模型级联也许是解决大模型『推理』缺陷的一个可用的手段,这我们在 ChatGPT Prompt 工程一文后面有所提及。不过,这种「推理过程」是怎么产生的呢?我们应该如何设计具有普遍意义的「推理流程」?CoT/半监督方式能否让语言模型学习到其中的「推理过程」,即便在过程中加上验证器?选择/推理这种框架也有同样类似的问题。
总之,目前看来好像并没有一个特别好的解决方案,还是更倾向于使用黑盒端到端方式。也许,符号主义可以焕发又一春,也许,我们需要等到大脑思考机制彻底解密。
文献参考
核心文献
- David Dohan, Language Model Cascades, 2022, Google
相关文献
- 【1】Maxwell Nye, Show Your Work: Scratchpads for Intermediate Computation with Language Models, 2021, Google
- 【2】Jason Wei, Chain-of-Thought Prompting Elicits Reasoning in Large Language Models, 2022, Google
- 【3】Xuezhi Wang, Self-Consistency Improves Chain of Thought Reasoning in Language Models, 2022, Google
- 【4】Karl Cobbe, Training Verifiers to Solve Math Word Problems, 2021, OpenAI
- 【5】Antonia Creswell, Selection-Inference: Exploiting Large Language Models for Interpretable Logical Reasoning, 2022, DeepMind
- 【6】Eric Zelikman, STaR: Self-Taught Reasoner Bootstrapping Reasoning With Reasoning, 2022, Stanford + Google