论文:[1910.10683] Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
一句话概述:把所有 NLP 任务统一成 Text-to-Text 格式使用 Transformer 统一处理。
摘要:迁移学习在 NLP 领域已经是最有效的方法,本文引入了统一的文本处理框架——将所有文本问题统一成 Text-to-Text 的格式。为了验证效果,构建了 C4 数据集(Colossal Clean Crawled Cropus),结果发现取得了很好的效果。
初衷
首先,我们看统一的样式,拿 Paper 里的一张图来说明,几种不同的任务被统一成如下格式:
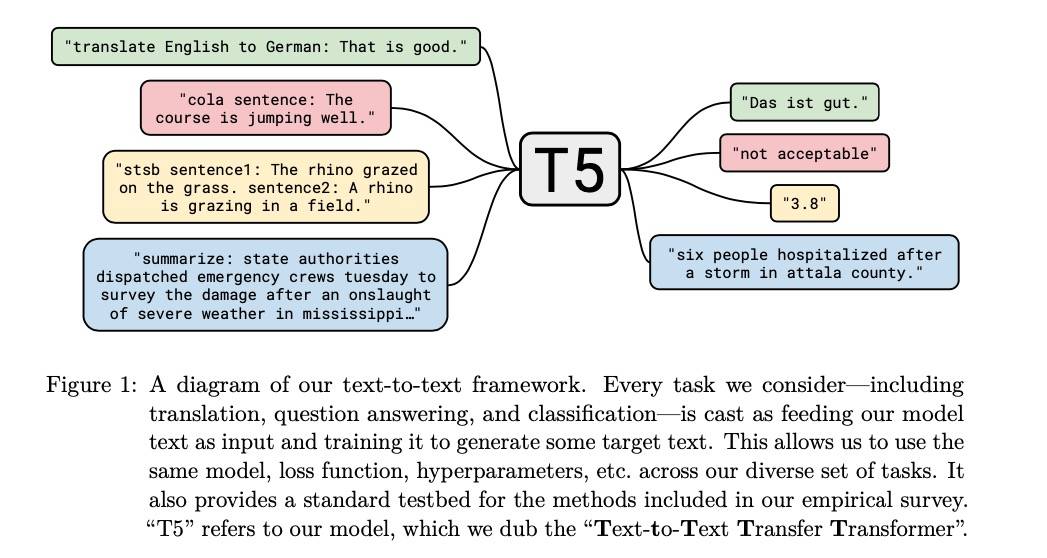
从直觉上看其实思想很简单,Encoder 把任务和 X 放进去,Decoder 生成对应的 Y。X 部分基本没啥说的,一般就是正常的自然语言文本;Y 的形式比较多样,毕竟 NLP 有那么多种任务,但总的来说还是可以分为两大类:分类(包括回归)和生成。分类就让 Decoder 生成对应的 Label,生成(摘要、翻译等)则让 Decoder 像正常一样生成文本即可。总的来说这个想法是比较 Make Sense 的。
那么,为什么要这样做呢?最直观的原因就是:简单、省事。由于 NLP 已经步入了预训练时代,衡量不同预训练模型、不同的预训练目标、不同的数据集等等就变得非常容易。不同的任务不仅不会成为一个变量,反而会成为衡量这些因素的一个很好的标准——效果越好,在不同任务上表现就应当越好,这比单一任务有说服力,还不用那么麻烦地一个个处理。我想这应该来自于 GPT-3 这样 NLG 大模型的 Zero-Shot 和 Few-Shot 能力,结合 Bert 优秀的 NLU 能力,喜欢「偷懒」的程序员们应该老早就想怎么避免单个处理任务,这才有了这篇规模浩大的「实验报告」。而且,论文还提到说目的不是提出一个新方法,而是提供一个 NLP 领域全面综合的视角。从他们的过程和结果来看,的确做到了这点。
We emphasize that our goal is not to propose new methods but instead to provide a comprehensive perspective on where the field stands.
配置
这部分有几个要点得明确:模型、数据集、下游任务和输入输出格式。这些都是基本设置,有了这些才能开始接下去的实验。值得一提的是,无论是开始的 Introduction 还是之后的部分,论文对历史发展介绍都比较全面,不光是在做实验,同时也是在综述领域演变,而且很细。确实是在提供更全面综合的视角。
模型
这部分详细介绍了 Transformer 架构,以及它的由来和演变,本文采用的模型架构也是 Transformer,不过有几个地方调整:
- 移除了 Layer Norm 的偏置项。
- 将层归一化放在残差连接路径之外。
- 位置编码。
归一化的具体代码如下:
1 | ##### Layer Norm ##### |
T5 这个也是 OpenNMT 的做法,具体可以看这篇 Paper:https://arxiv.org/pdf/2002.04745.pdf
位置编码:
1 | # 代码来自 Transformers |
感兴趣的可以阅读 Transformer 中 T5 的源代码。另外需要提醒的是,T5 仓库中并没有模型代码,模型用的是 mesh 里面的,Mesh 是一个分布式计算平台。
数据集
为了这个任务专门搞了个大数据集,确实到位。数据集是从网上抓取的,有以下特点:
- 原始来源是 2019 年 4 月的数据。
- Common Crawl 每个月产生 20 T 数据集。
- 只保留了英文数据。
- 预处理后得到 750G。
预处理策略如下:
- 只保留结束标点结束的行。
- 丢弃少于 5 个句子的页面,只保留至少包含 3 个单词的行。
- 删除了包含不良词表中任意词的页面。
- 删除了带有 JavaScript 的行。
- 删除了包含「lorem ipsum」占位符的页面。
- 删除了包含大括号的页面。
- 丢弃了数据集中不止一次出现的任何三句跨度中的一个。
任务集
主要包括:
- 机器翻译:WMT English 翻 German, French 和 Romanian
- QA:SQuAD
- 摘要:CNN/Daily Mail
- 分类:GLUE、SuperGLUE
输入输出
主要就是在原始句子前面添加一个任务前缀,就像前面的图 1,具体可以参考附录 D,不再赘述。
实验
接下来就是本文的重头了,整整 30 页的实验报告,我们重点关注要验证什么,以及结果如何。大的方面主要包括以下几个:
- 架构
- 训练目标
- 数据集
- 迁移策略
- 缩放
基准
Model
和 BertBase 同大小:
- 12 个 block
- FFN 3072 维
- ReLU
- AttnHeadDim 64
- HeadsNum 12
- HiddenDim 768
- 220 million 参数(110 × 2)
- Dropout 0.1
Training
- Teacher forcing
- 交叉熵损失
- AdaFactor 优化器
- Greedy 解码
- C4 上预训练 2^19=524288 步
- MaxSeqLen=512
- BatchSize=128
- 共 2^35=34B Tokens
- 「inverse square root」 Learning Rate Schedule:
1/sqrt(max(n,k)),n 是当前训练的 iteration,k 是 warm-up steps(10^4),即前 10^4 步学习率保持为 0.01,然后指数衰减直到预训练结束。 - 微调 2^18 步,BatchSize=128,MaxSeqLen=512,学习率固定 0.01,每 5000 步根据最佳验证集结果保存。值得注意的是,每个任务都是单独选择最佳的 checkpoint。
词表
- 32000 词条
- 包含非英文的其他语种(德、法、罗马)
- 输入输出共享词表
预训练目标
- Denoising 目标函数(即 MLM)
- 随机采样,丢掉 15% 的 Token,连续的 span 会被替换为特殊的符号
- 预测替换位置的 Token
表现
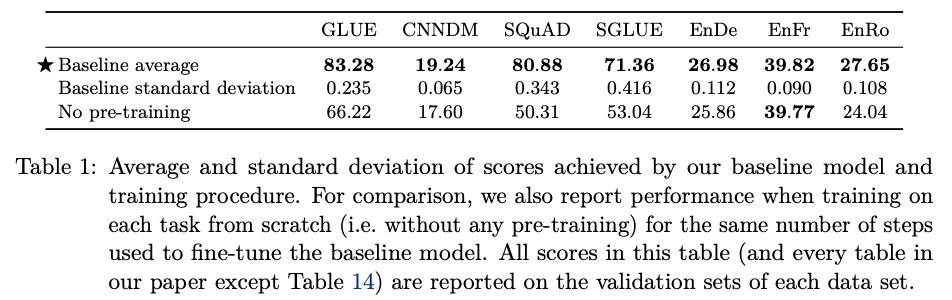
五角星是 Baseline,加粗的表示相差 2 个标准差之内的。
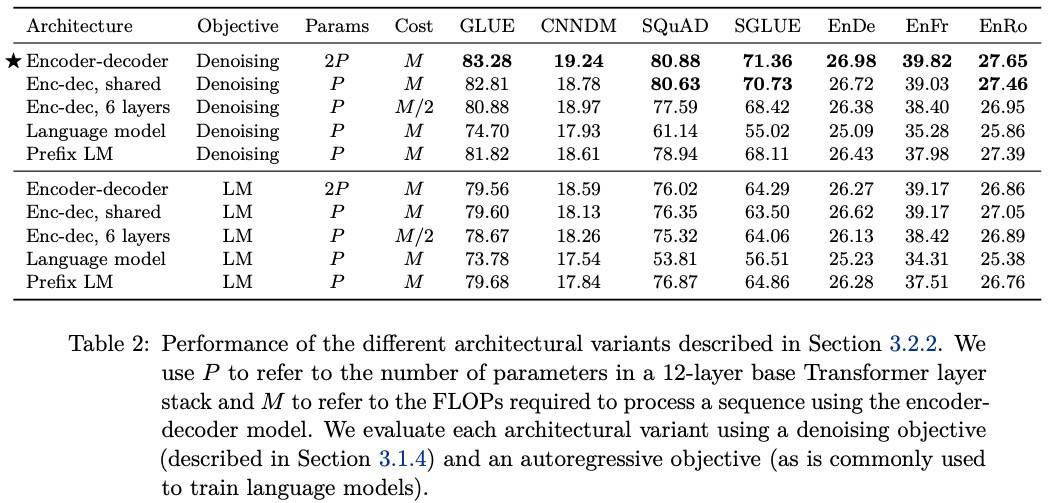
架构
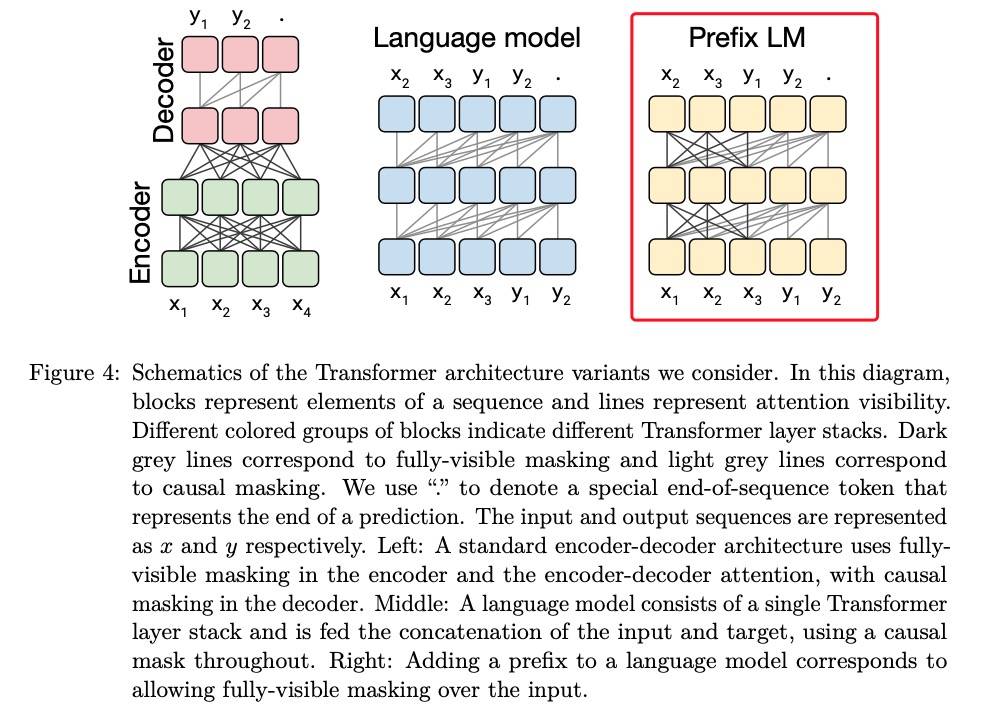
Encoder-Decoder 参数量虽然相比单独的 Encoder 或 Decoder 增加了一倍,但计算量却差不多。这是因为 Encoder 仅应用于输入序列,Decoder 仅应用于输出序列,语言模型(BERT)中的 L 层必须同时应用于输入和输出序列。
对比实验包括(Text-to-Text 格式可以使用任一种架构):
- Encoder-Decoder 模型,各 L 层,共 2P 参数,M FLOPS
- 模型同上,L 层,参数共享,共 P 参数,M FLOPS
- 模型同上,各 L/2 层,共 P 参数,M/2 FLOPS
- Decoder,L 层,P 参数,M FLOPS
- Decoder PrefixLM + 输入完全可见自注意力
无监督目标
不同的训练目标(重要):
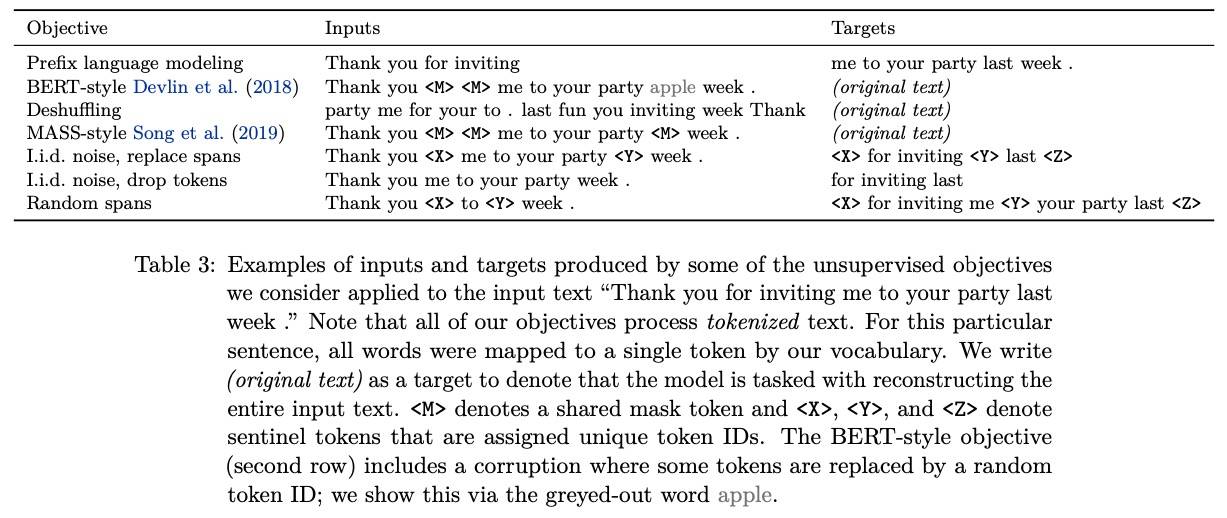
注意,PrefixLM 是从中间随机选个位置切开的,BERT 15%(90% Mask,10% 随机替换)。
效果如下:
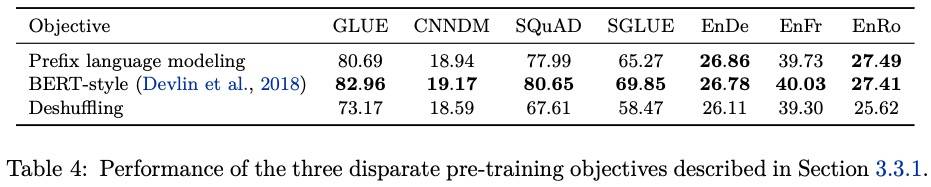
BERT 风格变种的效果如下:

注意后两种,不仅效果可以,而且由于 target 更短,训练更快。
然后是不同损坏比例的效果:

最后是不同 Span 的长度:

长度 2-3 效果都可以,另外 Span 也有加速训练效果。需要注意的是,15% 是所有损坏的 Token 数(而不是 Span 数)。
预训练数据集
好家伙,连数据集的效果都要测一下,效果如下:
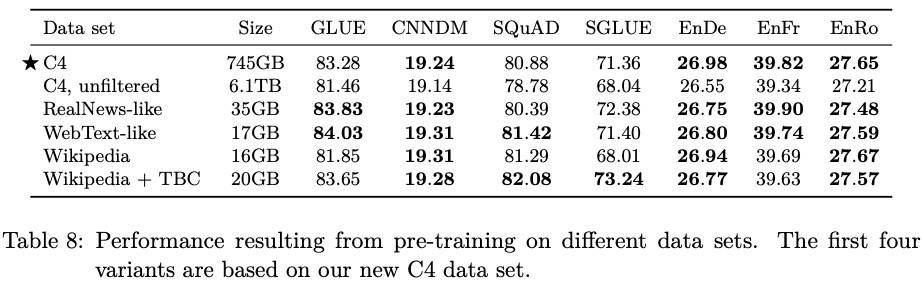
得出一个结论:领域数据集上预训练能够提升下有效果(为啥感觉像是句废话……)。
接下来是数据量大小的实验:
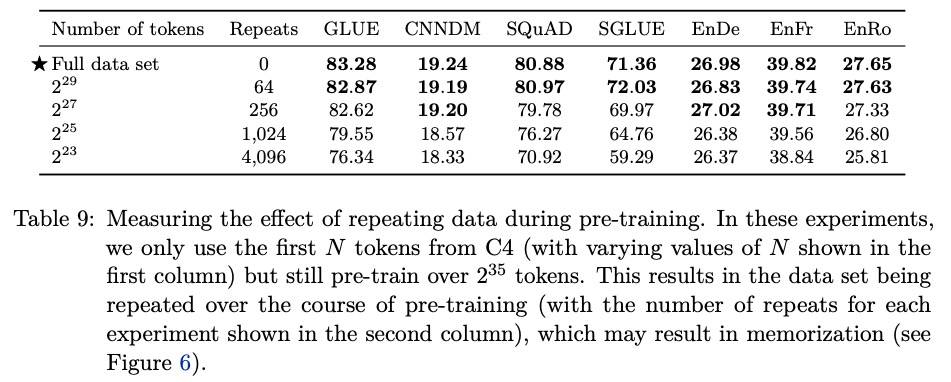
结论如下:
- 随着预训练数据集缩小,模型的训练损失明显更小,这表明可能存在记忆。(可不就是疯狂复制的锅)
- 较大的模型可能更容易过度拟合到较小的预训练数据集。
训练策略
首先是不同的微调方法:
- 适配层:在 Transformer 每个 Block 的前馈网络后添加的 dense-ReLU-dense Block,微调时,仅仅适配层和层归一化参数调整。
- 逐层解冻:微调时,从最后一层开始,随着训练的继续,之前的层逐步解开,直到所有参数都可以微调更新。具体是每隔
2^18/12步微调一个额外的层。
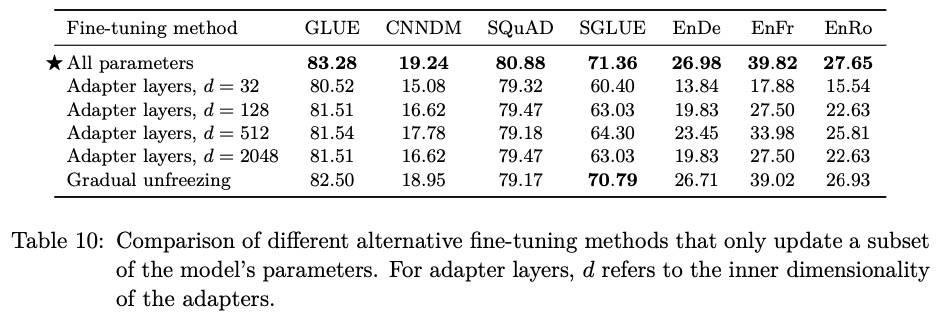
结论:低资源任务(SQuAD)在小 d 时效果也可以;高资源任务则需要更大的 d。说明只要将维度适当地缩放到任务大小,就可以在较少的参数上进行微调。
接下来是多任务数据混合策略,注意,虽然是多任务训练,但是评估表现时,不同的任务会选择不同的 checkpoint。
- Examples-proportional 混合:给定任务 n 的样本数量为 en,训练时从第 m 个任务采样的概率
rm=min(em, K)/Σmin(en, K),K 是人工数据集大小限制。 - Temperature-scaled 混合:给定 temperature T,每个任务的混合率 rm 提高到
1/T次幂并重新归一化。T=1 时就是上面的混合方法。 - Equal 混合:从每个任务中等概率采样。具体来说,每个批次中的每个样本都是均匀随机地从一个数据集上采样的。
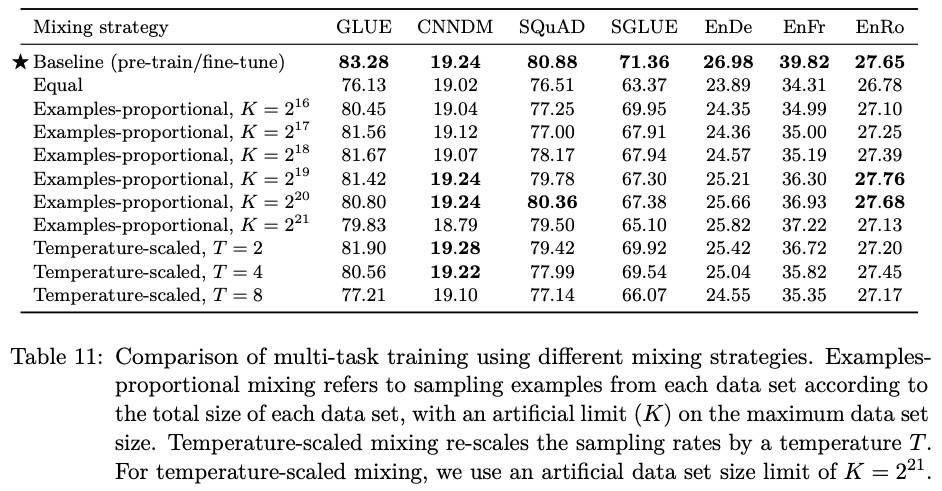
训练步骤都是 2^19 + 2^18 = 786,432,结果显示还是预训练+微调效果好,Equal 的效果最差,猜测是低资源任务过拟合,高资源任务又数据不足。
最后看看多任务学习+微调策略。
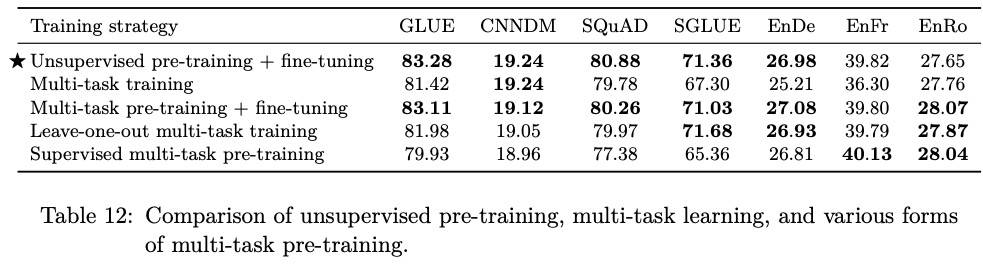
注意,多任务预训练+微调采用 K=2^19,结果显示:
- 多任务预训练+微调效果很不错。
- Leave-one 只是稍微差了些,说明多任务上训练的模型可以适配新任务。
- 多任务预训练在翻译任务上效果没那么差,说明翻译不太依赖预训练,无监督预训练在其他任务起了非常重要的作用。
总而言之,对于普通任务(数据量没那么大)无监督的预训练很有用;多任务预训练是有一定的 Zero-Shot 潜力的。
缩放
主要指更大的模型、更多的训练步骤和更大的 BatchSize。
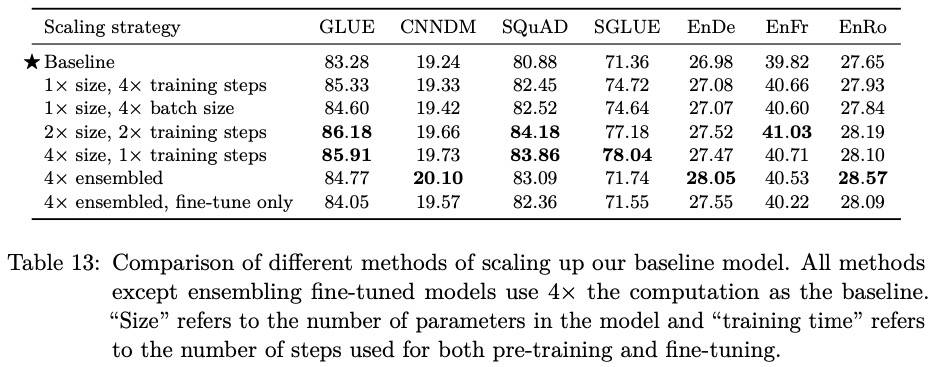
基本上,大模型多步骤=更好=多钱。需要注意的是集成策略时在最终输出到 SoftMax 前会将多个模型的 logits 平均。结论是:将小型模型预训练更长时间是个不错的策略。一个预训练模型+4个不同的微调版本效果还是不行,大模型时代,集成效果都要打折扣了。
汇总
意味着要把之前最好的都放一块整一个「完美」的版本出来了:
- 目标:MLM+Span,15% 的损坏 Token,Span 平均长度 3
- 长时间训练:1 million 步,BatchSize=2^11,序列长度 512
- 模型尺寸:Base 220M,Small 60M,Large 770M,3B 和 11B
- 多任务预训练:对无监督和监督任务的多任务组合进行预训练,再微调
- 分别在 GLUE 和 SuperGLUE 单个任务上微调:BatchSize=8,序列长度 512 在每一个任务上微调
- Beam Search:width=4,α=0.6
- 测试集:使用测试集而不是验证集
先看一下和之前的效果对比:

看起来有不小的提升,我咋觉得全靠更多的训练步骤呢。。。
再看看和之前 SOAT 的对比:

嗯,差距还是不小,后面 T5 又搞出来个 1.1 版,具体有这么些改进:
- 前馈层使用 GEGLU 代替 ReLU
- 预训练时关闭 Dropout,微调时打开
- 只在 C4 上预训练,不包含下游任务
- Embedding 和 Classifier 不共享参数
具体见参考文献【3】。
结论
要点
- Text-to-Text:方便地将多个任务放在一个模型
- 架构:Enc-Dec 的 Transformer(Enc 和 Dec 可以共享参数)效果最好。是不是最符合人类直觉,先理解再说话?
- 无监督目标:MLM,使用 Span 加速预训练
- 数据集:C4,大数据集预训练,数据集太小(重复采样)没用
- 训练策略:微调预训练模型的所有参数效果最好;多任务预训练+微调取得和无监督预训练+微调相当的效果
- 缩放:更多数据的小模型比大模型少步好
- 极限:11B,无监督预训练+多任务预训练+单任务上微调
展望
- 大模型的不便:提倡研究以更便宜的模型实现更强性能的方法。
- 更高效地知识抽取:怀疑这种简单化的技术(大规模预训练)可能不是教授模型通用知识的非常有效的方法。
- 形式化任务之间的相似性:领域内未标记数据预训练可以提升下游相关任务性能,所以制定一个更严格的「预训练任务和下游任务之间的相似性」的概念是有用的,这样我们就可以对使用什么未标记的数据来源做出更有原则的选择。我理解这其实就是说 T5 自己。
- 与语言(自然语言)无关的模型:进一步研究与语言无关的模型,即无论文本的语言如何,都可以以良好的性能执行给定 NLP 任务的模型。
T5 在模型上并没太多创新,但是这个统一各种任务的模式却是不错,诚如 paper 所言,这可以更方便地评估大模型的各种能力,可以让研究者将重心放在设计模型架构、预训练目标等方面。就这方面来说,这篇 paper 又开启了一个小时代。