一句话概述:去偏技术尚不明朗。
摘要:研究表明预训练模型有一定的社会偏见(这个真得怪社会),所以我们不得不从技术角度去缓解它。本文主要从经验角度分析了五种最近的纠偏技术:Counterfactual Data Argumentation(CDA)、Dropout、Iterative Nullspace Projection,Self-Debias,SentenceDebias。在三个不同的 bias benchmark 上分别对其效果进行量化评估,同时评估了这些技术对模型的语言建模能力和下游任务表现的影响。结果如下:(1)CDA 和 Self-Debias 是最好的纠偏技术;(2)当前的纠偏技术不能很好地泛化到性别偏见之外;(3)纠偏通常伴随着语言建模能力的下降,从而难以确定偏差缓解是否有效。
背景
因为预训练模型都是在已有语料上训练的,而语料本身是有一定社会偏见的,这就导致模型可能也学到了这种偏见。虽然已经有一些相关研究,但这些技术并没有经过认真审查。比如大量工作只聚焦在性别偏见方面,但预训练模型的偏见可能是其他方面。另外,去偏见技术对下游任务表现和语言模型能力的影响也没有很好的研究。
本文实证研究了近期提出的五种去偏技术:CDA、Dropout、Iterative Nullspace Projection,Self-Debias 和SentenceDebias。在三个 MLM 预训练模型(BERT、ALBERT 和 RoBERTa)和一个自回归语言模型(GPT-2)中研究了这些技术在减轻性别、种族、宗教偏见方面的功效。另外也探讨了对语言建模能力和下游 NLU 任务性能的影响。
具体来说,主要回答了以下几个问题:
- 哪种技术对减轻偏见最有效?CDA 和 Self-Debias。
- 这些技术是否可用于非性别偏见?大部分技术对非性别偏见泛化能力很差。
- 是否影响模型的语言建模能力?会影响能力。
- 是否影响下游 NLU 任务?会降低性能。
使用了三个 Benchmark:
- StereoSet
- CrowS-Pairs
- Sentence Encoder Association Test(SEAT)
评价偏见技术
WEAT:Word Embedding Association Test
- 两组偏见属性词和两组目标词
- 属性词表征了一种偏见:
{*man*, *he*, *him*, ...}, {*woman*, *she*, *her*, ...},用于性别偏见。 - 目标词表征了特定概念:
{*family*, *child*, *parent*, . . . }, {*work*, *office*, *profession*, . . . }分别用来描述家庭和事业的概念。
- 属性词表征了一种偏见:
- 评估来自一个特定属性词表的词表示是否倾向于与来自一个特定目标词表的表示更密切相关。
其中,A 和 B 表示属性词,X 和 Y 表示目标词。
对一个特定词 x=w,s(x, A, B) 定义为 w 分别与 A 和 B 中词的平均 cosine 相似度的差异:
效果为:
其中 μ 和 σ 分别表示均值和方差。d 约接近 0,说明偏见程度越低。词替换后可以用语言模型来表征句子,这样就可以创建句子级别的 WEAT,即 SEAT:Sentence Encoder Association Test。
StereoSet
评估四种不同类型的刻板偏见,包括一个句内任务和一个句间任务,本文聚焦句内任务。每个任务样本包括一个上下文句子和一组(3个)与句子可能相关的词——一个是有偏见的,一个是反偏见的,还有一个不相关的。
具体做法是将有偏见的词与反偏见的词在 MLM 时的概率作为分数,然后计算偏见词得分高于反偏见词的样本比例,这个比例作为模型的「偏见分数」;同时还考虑了不相关词,计算与其他两类的比例,这个比例作为一个模型的「LM分数」。
CrowS-Pairs
评估语言模型九种不同类型的社会偏见,每个样本包含一对仅有少数几个 Token 不同的句子对,第一个句子反映了美国历史上对处于不利地位群体的刻板印象,第二个句子则是反第一个句子的刻板印象。
具体做法是评估模型更偏好第一个句子的频率——通过计算每个句子的伪似然。
去偏见的技术
CDA
CDA 通过交换数据集中的性别术语来重新平衡语料,平衡后的语料继续训练以对模型去偏。
Dropout
增加 BERT 和 ALBERT 的注意力权重和隐藏激活的 dropout 参数,并执行额外的预训练,猜测可能是 dropout 中断了 attention 机制,阻止了学习词之间的关联。
Self-Debiasing
一种不需要数据、训练或人工单词列表的事后去偏差方法,它利用模型的内部知识来阻止其生成有偏见的文本。比如可以先让模型根据人工提示(Promote)生成有偏见的文本,然后生成第二个文本,其中第一个有偏见文本中的 Token 概率会缩小。
Sentence Debias
一种基于投影的去偏技术,涉及估计特定类型偏差的线性子空间。可以通过投影到估计的偏差子空间并从原始句子表示中减去投影来对句子表示去偏差。
评估一个有偏差的子空间有三个步骤:
- 定义偏见属性词列表,每组包含两个词,分别表示偏见的不同维度,如(男,女)。
- 把属性词上下文到句子里,具体通过找到语料中包含属性词的句子来实现。对每个句子,使用 CDA 生成一对仅在偏见方面不同的句子。
- 评估偏见子空间。对每个句子,CLS Token 可以作为句子表示,然后使用 PCA(前 k 个主要成分)来估计表示集的主要变化方向。
INLP
一种类似于 Sentence Debias 的基于投影的去偏技术。粗略地说,INLP 通过训练线性分类器来预测要从表示中删除的受保护属性(例如,性别)来消除神经表示的偏差。然后,表示可以通过将它们投影到学习分类器的零空间来消除偏差。然后重复此过程以消除表示的偏差。
去偏效果比较
SEAT
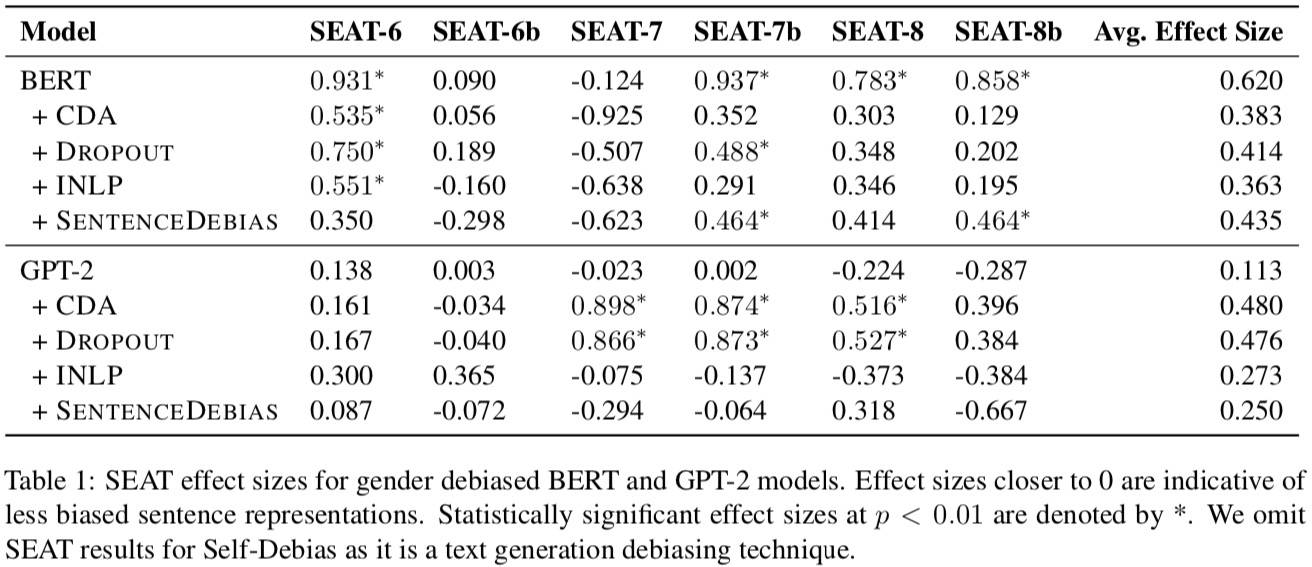
性别偏见:
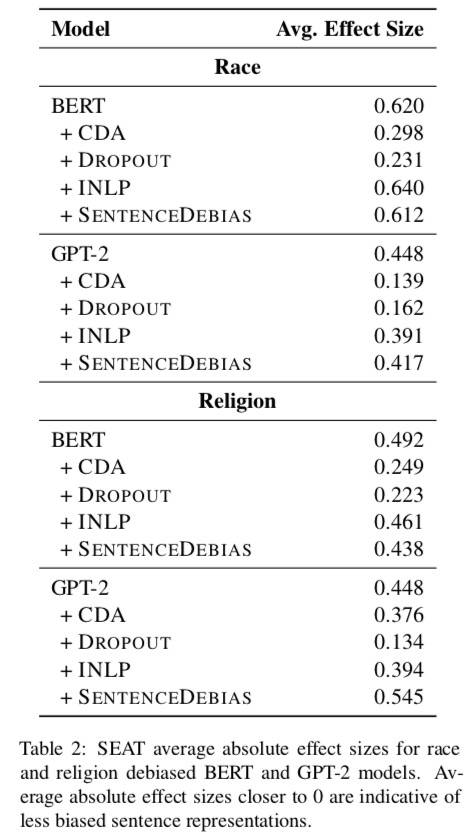
种族和宗教偏见:
小结:
- BERT 的去偏有效果,GPT-2 没效果。
- 在不同数据集上表现大不相同。
- CDA 和 Dropout 在种族和区域领域表现稳定。
StereoSet 和 CorwS-Pairs

StereoSet 小结:
- 对性别偏见,大部分去偏技术有效。
- 对宗教偏见,Self-Debias 对两个模型都有效。
CrowS-Pairs 小结:
- CDA,Self-Debias 和Sentence Debias 对性别偏见有效。
- 在宗教 GPT-2,Sentence Debias 猜测可能是只有 105 个样本。
刻板印象分数能否可靠地衡量偏见?
这里有个很重要的问题:去偏模型可能不是由于缓解了实际偏见,而仅仅因为变成了一个更差的语言模型(类似于随机)从而得到较低的刻板印象分数。
建模能力影响
对 MLM 模型,计算伪 ppl 代替 ppl。

小结:
- Dropout 和 CDA 降低了 ppl,可能是因为额外的预训练。
- Dropout 或 CDA 额外的预训练增强了 BERT 的语言模型能力。
下游任务影响
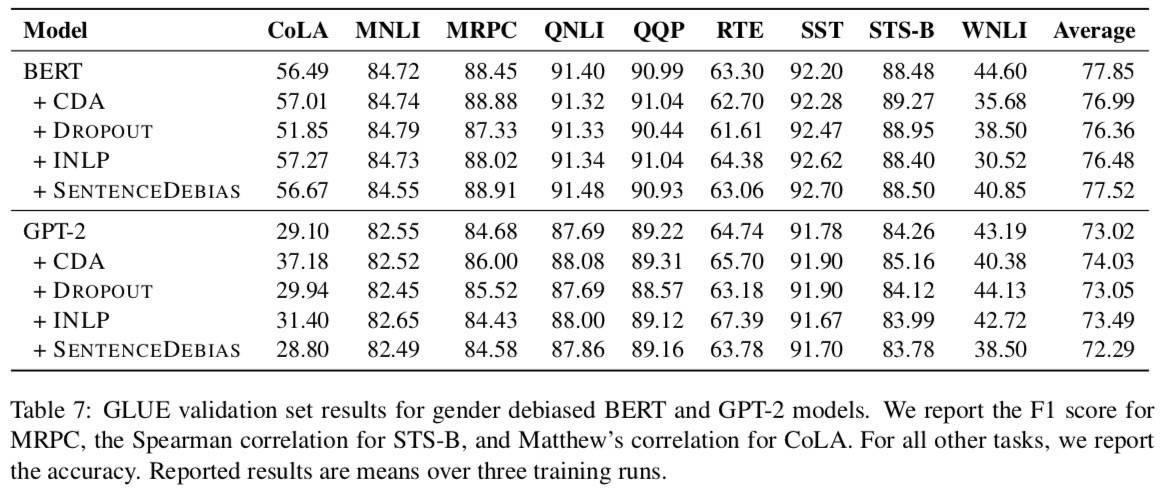
小结:去偏技术对模型执行下游 NLU 任务的能力只有很小的负面影响。
讨论
去偏技术效果如何
- 很难确定 Dropout、INLP 和 SentenceDebias 是否是有效的偏见缓解技术。 尽管使用这些技术通常在 CrowS-Pairs 和 StereoSet 上获得降低的刻板印象分数,但也存在语言建模性能下降的现象。
- Self-Debias 作为一种缓解偏见的技术确实看起来很有效,因为它不仅在 CrowS-Pairs 和 StereoSet 上都获得了降低的刻板印象分数,而且在去偏后仍然是一个强大的语言模型。
- 就本文的研究来说,Self-Debias 是最有希望的去偏技术。
用于评估去偏技术的可靠偏差基准
- 衡量去偏技术的有效性时,仅来自 CrowS-Pairs 和 StereoSet 的刻板印象分数并不是衡量偏差的可靠指标。
- 偏差基准还必须考虑模型的语言建模能力。
- 开发可靠的偏差基准是未来研究的一个重要领域。
非性别偏见的去偏见技术
- 本文的一些去偏技术似乎不容易适应非性别偏见。
结论
- Self-Debias 和 CDA 看起来是最好的去偏技术,三个基准偏差减少,同时仍然在很大程度上保留语言建模能力和下游任务性能;
- 这项工作中研究的许多去偏见技术在减轻非性别偏见方面并不是很有效;
- 一些 debiasing 技术似乎严重损害了模型的语言建模能力;
- 当前的偏置基准,如 StereoSet 和 CrowS-Pairs 可能无法可靠地测量去偏置上下文中的偏置。
思考
看到这篇文章时觉得挺有意思,主要的点体现在对语言模型「输出的影响」方面。无论是使用生成模型生成句子,还是使用 MLM 填充空白,都可能会产生一些「敏感」结果,在不损害语言模型的前提下,如何优雅地解决这个问题才是值得探究的点。看完之后——挺失望的,文章的很多结论其实并不清晰,效果飘忽不定,解释颇有牵强;CDA 和 Self-Debias 也并不是很优雅地方案(不过肉眼可见的有效)。最后搞了半天还是停留在前处理和后处理上,还只能针对很少的偏见,这对实际场景来说是远远不够的。