论文:[2110.15943] MetaICL: Learning to Learn In Context
一句话概述:任务的数量和多样性+Instruction是元学习的最佳实践。
摘要:MetaICL 是一种新的元训练框架,用于小样本学习,其中预训练模型被微调以在大量训练任务上进行上下文学习。这种元训练使模型在测试时能够更有效地学习上下文中的新任务,方法是在不更新参数或不需要任务特定模板的情况下简单地调整几个训练示例。本文对 142 个 NLP 数据集组成的任务集合进行实验,包括 CLS、QA、NLI、释义检测等,跨越 7 个不同的元训练/目标拆分。结果比已有的 Baseline(如没有 Meta 训练的 In-Context 学习,多任务学习,零样本转移)要好。而且,对于具有从元训练任务进行域转移的目标任务,收益尤其显着,并且使用不同的元训练任务集是改进的关键。另外,MetaICL 接近(有时甚至超过)在目标任务训练数据上完全微调的模型的性能,并且优于具有近 8 倍参数的更大模型。
背景
In-Context Learning:根据几个训练样本进行调节并预测哪些 Token 最能完成测试输入即可学习新任务。
- 优点:
- 可以仅通过推理来学习新任务,无需参数更新
- 缺点:
- 性能不如监督微调,尤其是目标任务和 LM 不同,或 LM 不够大时
- 结果具有高方差
- 设计将现有任务转换为格式所需模板较难
Meta-training via Multi-task Learning:
-
优点:
- 无论是 Zero-Shot 还是微调,在大规模任务上多任务学习在新任务能获得更好的结果。
-
缺点:
-
Zero-Shot 模型局限于和训练任务相同格式的任务
-
严重依赖特定任务模板,由于非常小的变化导致性能差异很大,因此难以设计
-
Meta-Training:
- 已有研究 「Finetuned language models are zero-shot learners」 表明需要 68B 或更多参数才有用,本文 770M
- 与「Meta-learning via language model in-context tuning」相比,本文:
- 去除了人工模板
- 包括了更多多样化任务
- 更强的 baseline
- 更大规模的元训练/目标拆分实验
框架
ICL 表示 In-Context Learning,MetaICL 在大量任务上调整预训练语言模型,学习如何进行上下文学习,并在严格的新未知任务上进行评估。每个元训练示例都与测试设置相匹配 —— 它包括来自一个任务的 k + 1 个训练样本,这些样本将作为单个序列一起呈现给语言模型,并且最后一个样本的输出用于计算交叉熵损失。在此配置下,简单地微调模型可以带来更好的上下文学习 —— 模型学习从给定的例子中恢复任务的语义,推理时新任务也是这样执行的。只不过 MetaICL 可以从 k 个样本中单独学习新任务,而不需要依赖任务重格式化或特定任务模板。
核心思想:在大规模集合 meta 训练任务上,使用一个多任务学习方案,学习如何基于一组训练样本恢复一个任务的语义,并预测输出。

实验配置:
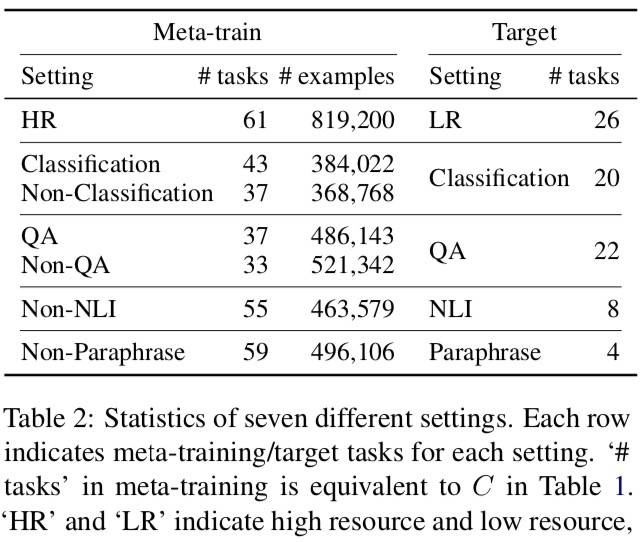
- 大规模、多样化的任务集合:142 个文本分类、QA、推理和短语检测数据集。
- 7 个不同的设置,训练和目标任务在任务和领域上都没有交集。
结果显示:
- MetaICL 使得模型在训练任务和目标不一致时也能在推理时很好地恢复语义
- 表现常常和 8 倍参数的有监督微调接近(有时甚至会超过)
- 没有任何模板比最新使用人工手写的指导(human-written natural instructions)效果更好,两者结合效果最佳
Meta-training
每一步,一个 meta-training 任务被抽取作为样本,k+1 个训练数据从该任务中抽取,然后将前 k 个样本的 x 和 y 与第 k+1 个样本的 x 拼接起来作为输入,训练模型生成第 k+1 个样本的 y。
Inferece
对一个新的目标任务,模型给出 k 个训练样本和一个测试输入 x,同时给定一组候选 C,一般一组标签(分类任务)货答案选项(QA 任务)。k 个样本的 x 和 y 再加 x 作为输入,计算每个 label 的条件概率,取最大的作为预测值。
Channel MetaICL
训练时:给定 k 个样本的 y 和 x,以及第 k+1 个样本的 y,生成第 k+1 个样本的 x;推理时,给定 k 个样本的 y 和 x,以及 c,最大化测试输入 x 的概率。
实验
基本设置
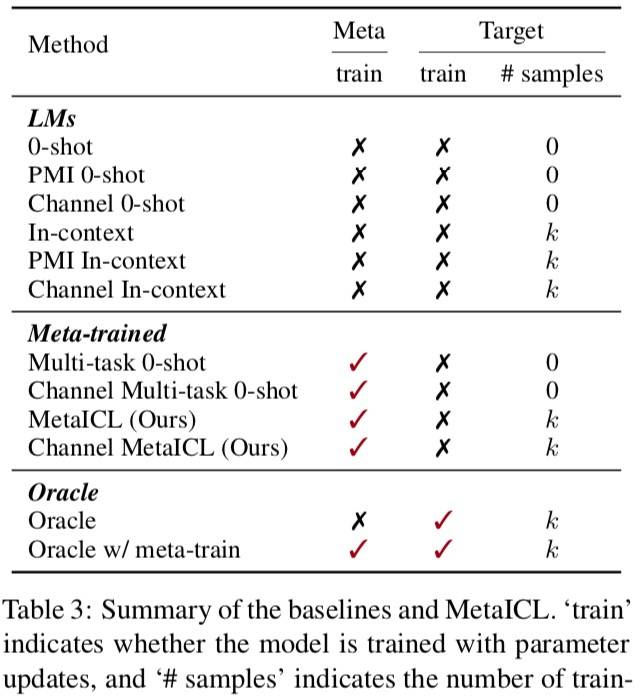
基线设置
实验评估
使用 Macro-F1
- 对一个目标任务,使用 k=16 随机均匀样本
- 使用了 5 组 k 个训练样本
- 去掉了模板,使用数据集给定的输入和标签词(如下图示)

训练细节
- Base LM = GPT-2 Large(770M 参数)
- Raw LM = GPT-J(6B 参数)
- 16384 训练样本/每个任务
- BatchSize=8,LR=1e-5,seq_len=1024
- 30000 Steps,8-bit 精度 Adam
报告
实验结果
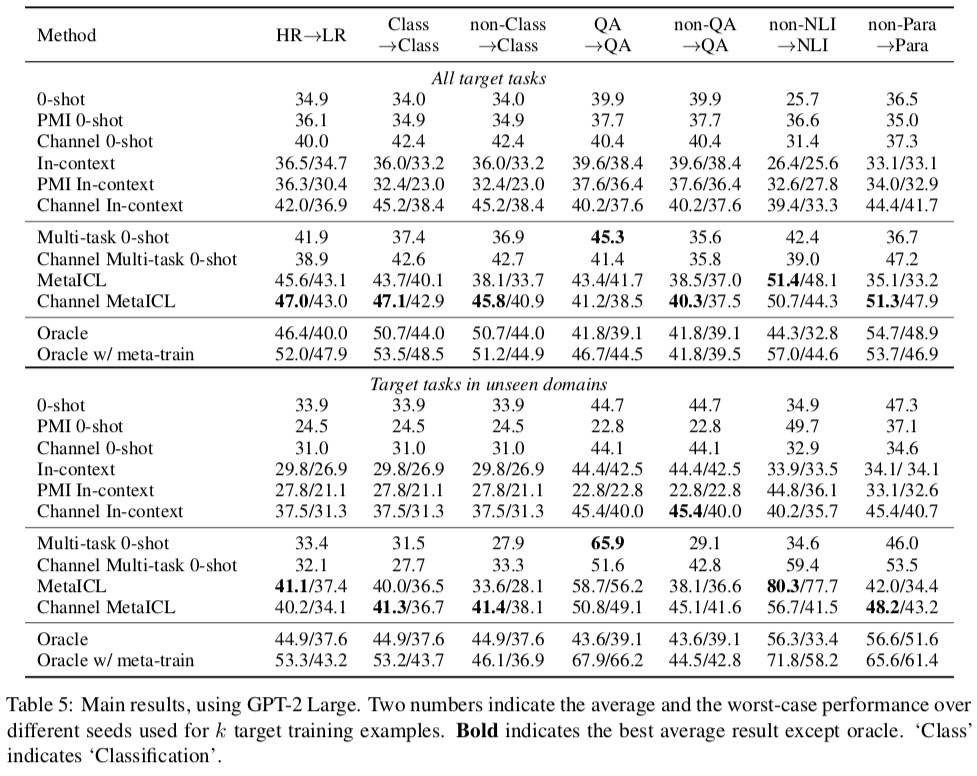
- 相比没有 Meta-training(1-6 行),Channel In-context 效果最好
- Multi-task 0-shot 没有超过最好的 raw LM,原因可能是:模型小,与更强的「channel 基线」进行对比
- MetaICL 和 Channel MetaICL 超过了一系列强 Base
- QA→QA 可能因为 Meta-training 和目标太相似,并不需要生成能力
- Multitask 0-shot 在未知领域不如 raw LM,可能因为需要更强的生成能力,MetaICL 没有太受影响
- Meta-training 有助于监督学习和 MetaICL
实验消融
Meta-training 任务的数量
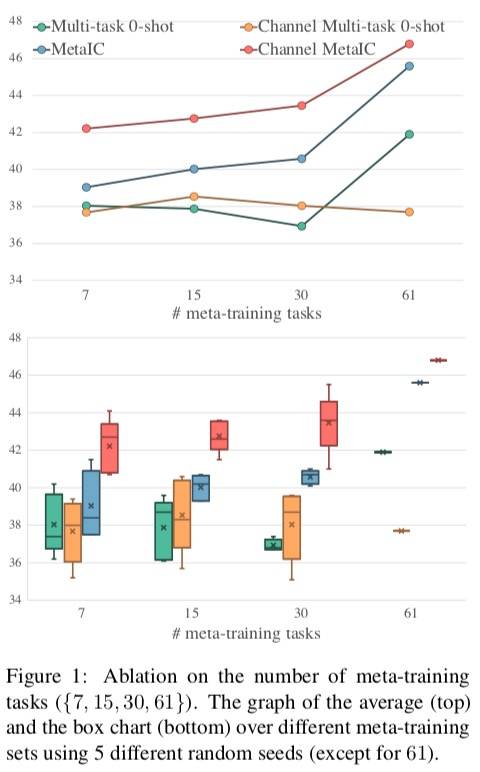
- 随着任务数增加效果增加
- Channel MetaICL 超过其他模型
- Meta-training 的不同选择(图 1 底部)会对性能产生重大影响
Meta-training 任务的多样性
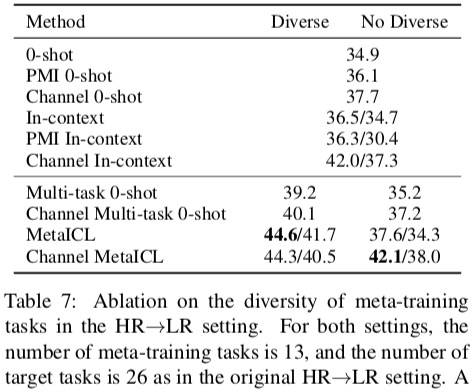
- 多样性对 MetaICL 很重要
- 高质量多领域数据有用
- 对抗收集的数据往往没用
Instruction 的必要性
- 基于 k 个样本建模可能可以不要 Instruction
- Instruction 可能有互补作用,能够为模型提供额外的有用信息
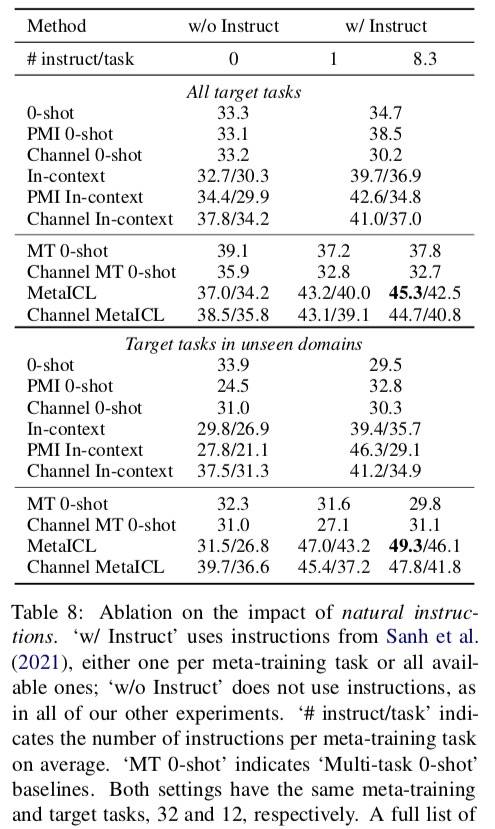
- 不使用 Instruction 的 MetaICL 比使用了的 Multi-task 0-shot 好
- 使用 Instruction 时 MetaICL 有进一步的改进(互补)
- 随着 Instruction 数量的增加,MetaICL 效果提升比 Multi-task 0-shot 更多
结论
本文介绍了一种新的 few-shot 学习方法——MetaICL,一个 LM 通过元训练来学习上下文学习,基于训练样本恢复任务并做出预测。在大量多样的任务上表现出很好的效果,超过不使用元训练的 In-context 学习和多任务学习+zero-shot 迁移学习,和 8 倍大小的模型不相上下。
MetaICL 成功的要素包括元训练任务的数量和多样性,同时使用 Instruction 可以互补,最佳实践是二者结合。一个关键限制是每个样本的长度起着关键作用,因此长样本更难使用。