Encoder takes an input sequence and create a contextualized representation of it, then passed to a decoder which generates a task-specific output sequence.
Neural Language Models and Generation Revisited
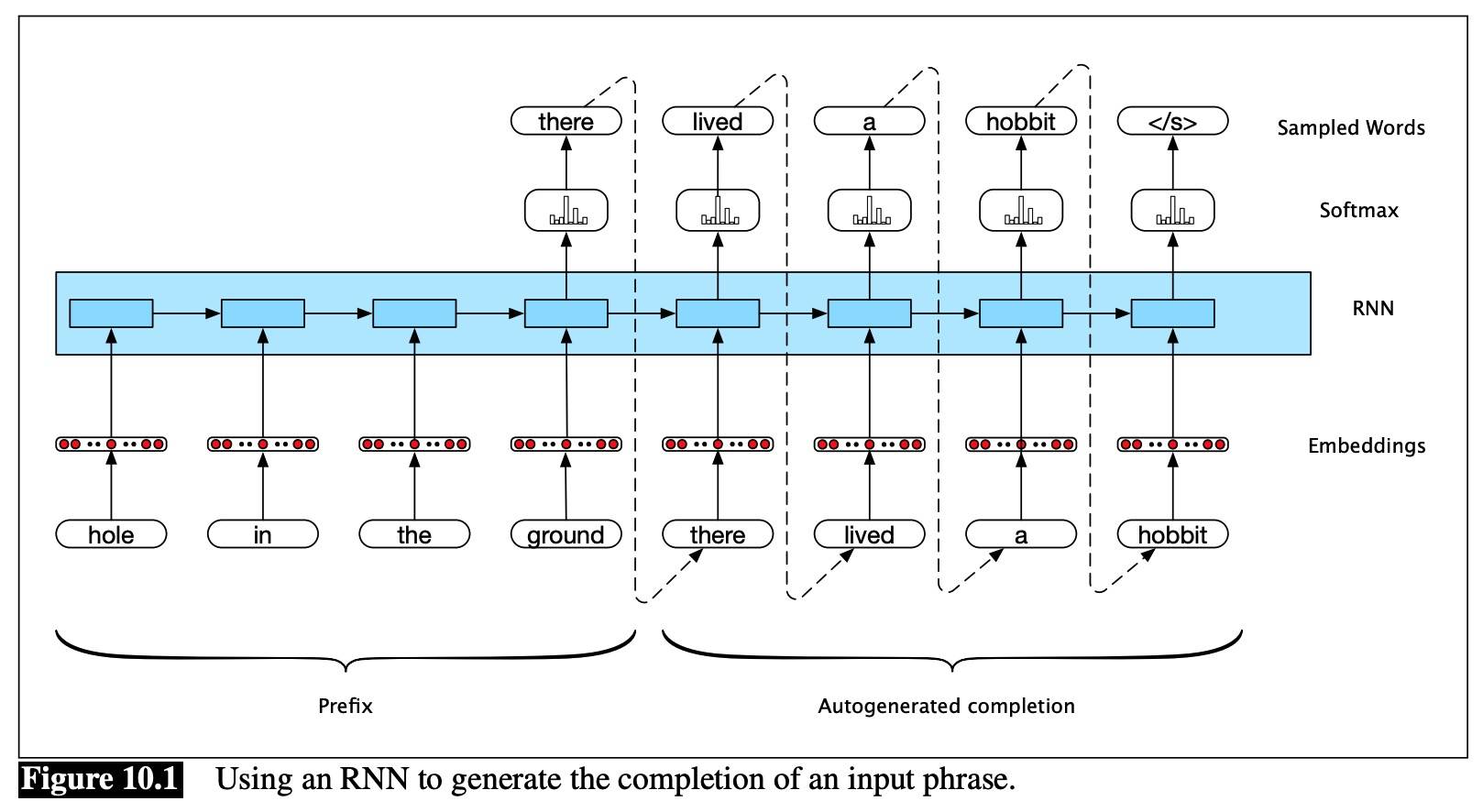
Train network to predict the next word in a sequence using a corpus of representative text is referred to as autoregressive models.
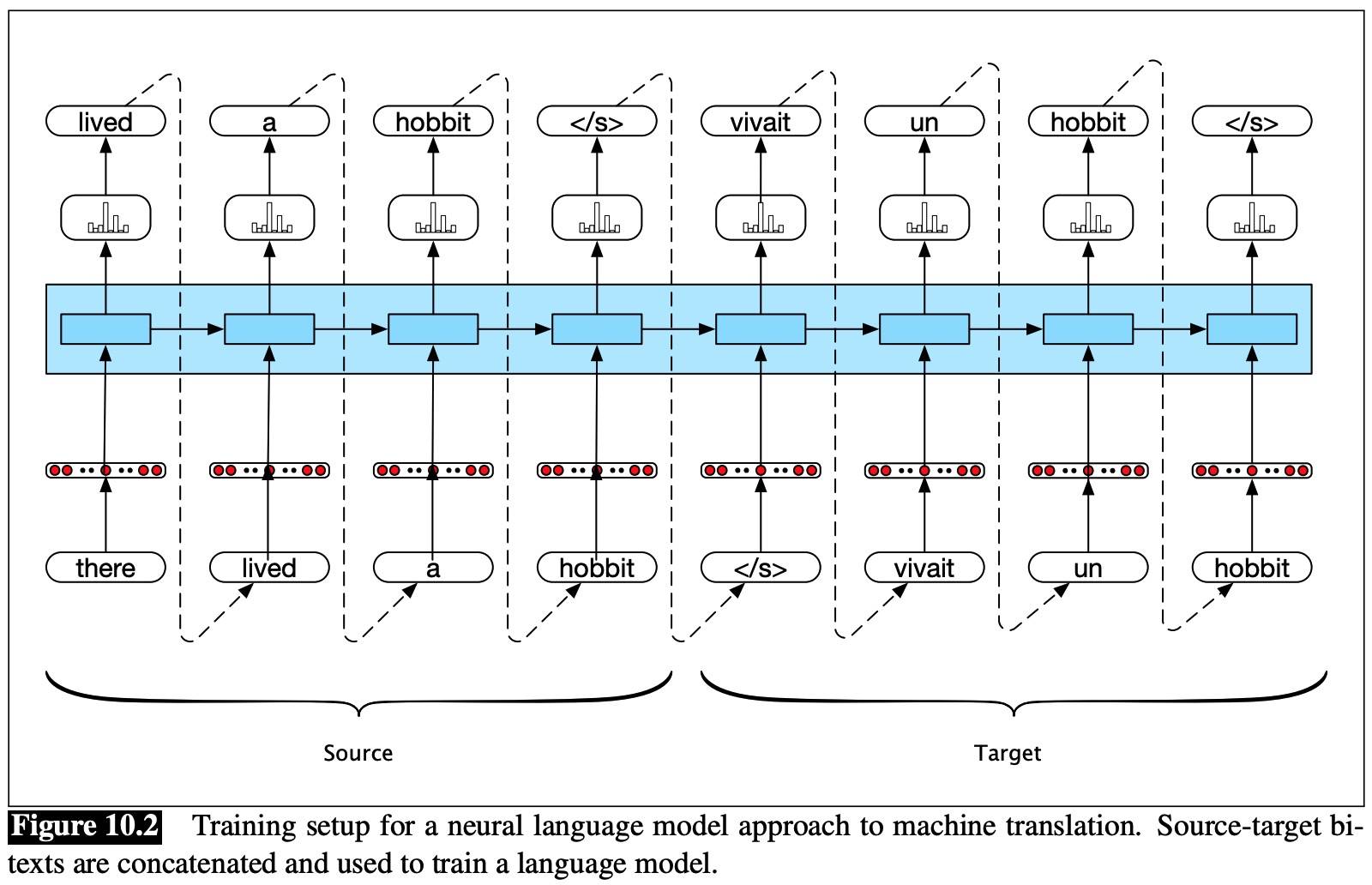
The primary resources used to train modern translation systems are bitexts known as parallel texts, or bitexts, includes the source and the target.
To translate a source text:
- Performing forward inference to generate hidden states until we get to the end of the source.
- Begin autoregressive generation, asking for a word in the context of the hidden layer from the end of the source input as well as the end-of-sentence marker.
- Subsequent words are conditioned on the previous hidden state and the embedding for the last word generated
Encoder-Decoder Networks
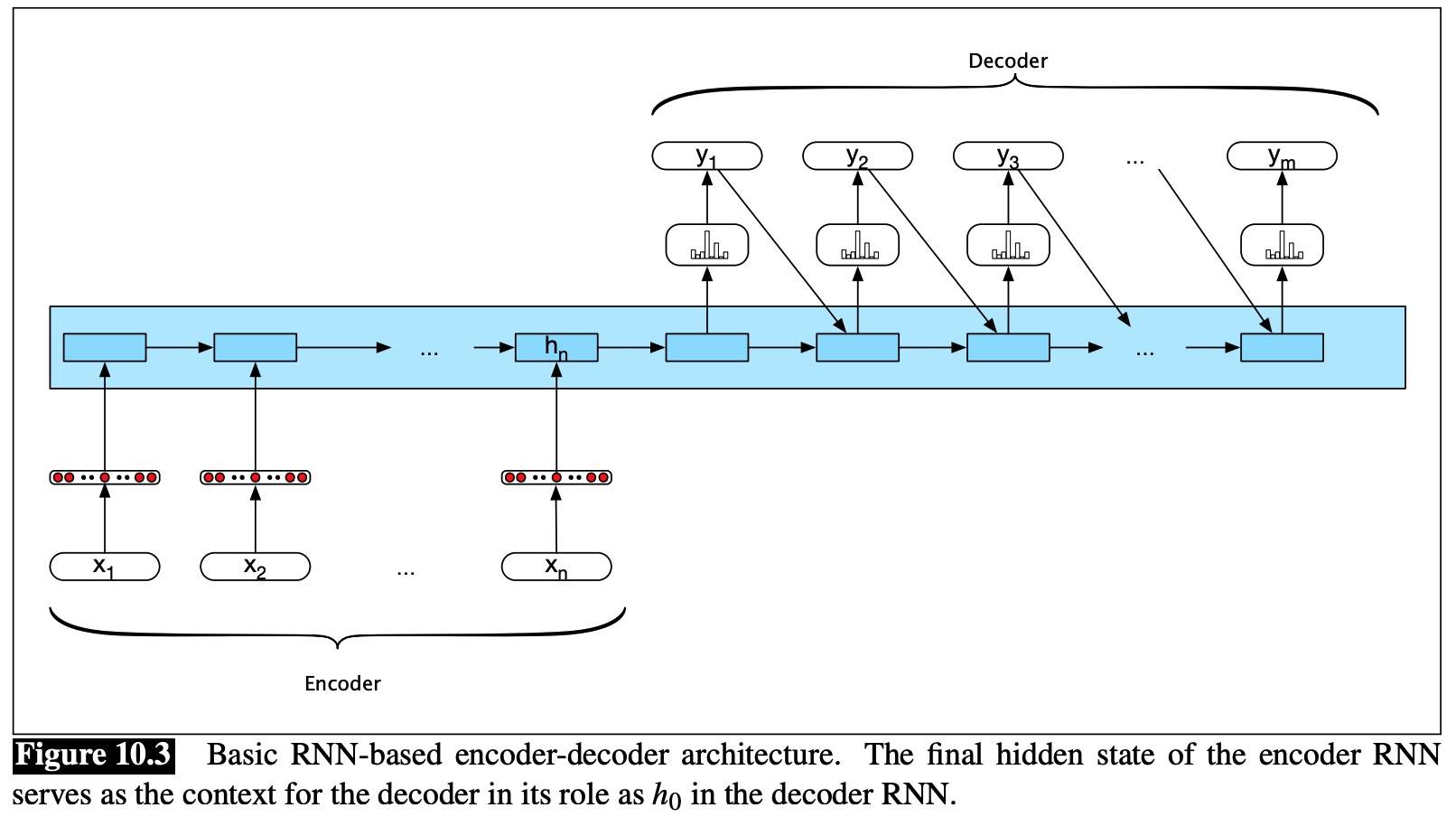
- An encoder that accepts an input sequence Xn and generates a corresponding sequence of contextualized representations Hn.
- A Context vector, c, which is a function of Hn, conveys the essence of the input to the decoder.
- A decoder, which accepts c as input and generates an arbitrary length sequence of hidden states Hm, from which a corresponding sequence of output states Ym can be obtained.
Encoder
Can be RNN, GRU, LSTM, CNN, Transformer, Bi-LSTM and stacked architectures.
Decoder
The weakness: c is only directly available at the beginning of the process and its influence will wane as the output sequence is generated. A solution is to make the c available at each step:
Beam Search
To control the exponential growth of the search space, Beam search operates by combining a breadth-first-search strategy with a heuristic filter that scores each option and prunes the search space to stay within a fixed-size memory footprint, called the beam width. The sequence of partial outputs generated along these search paths as hypotheses.
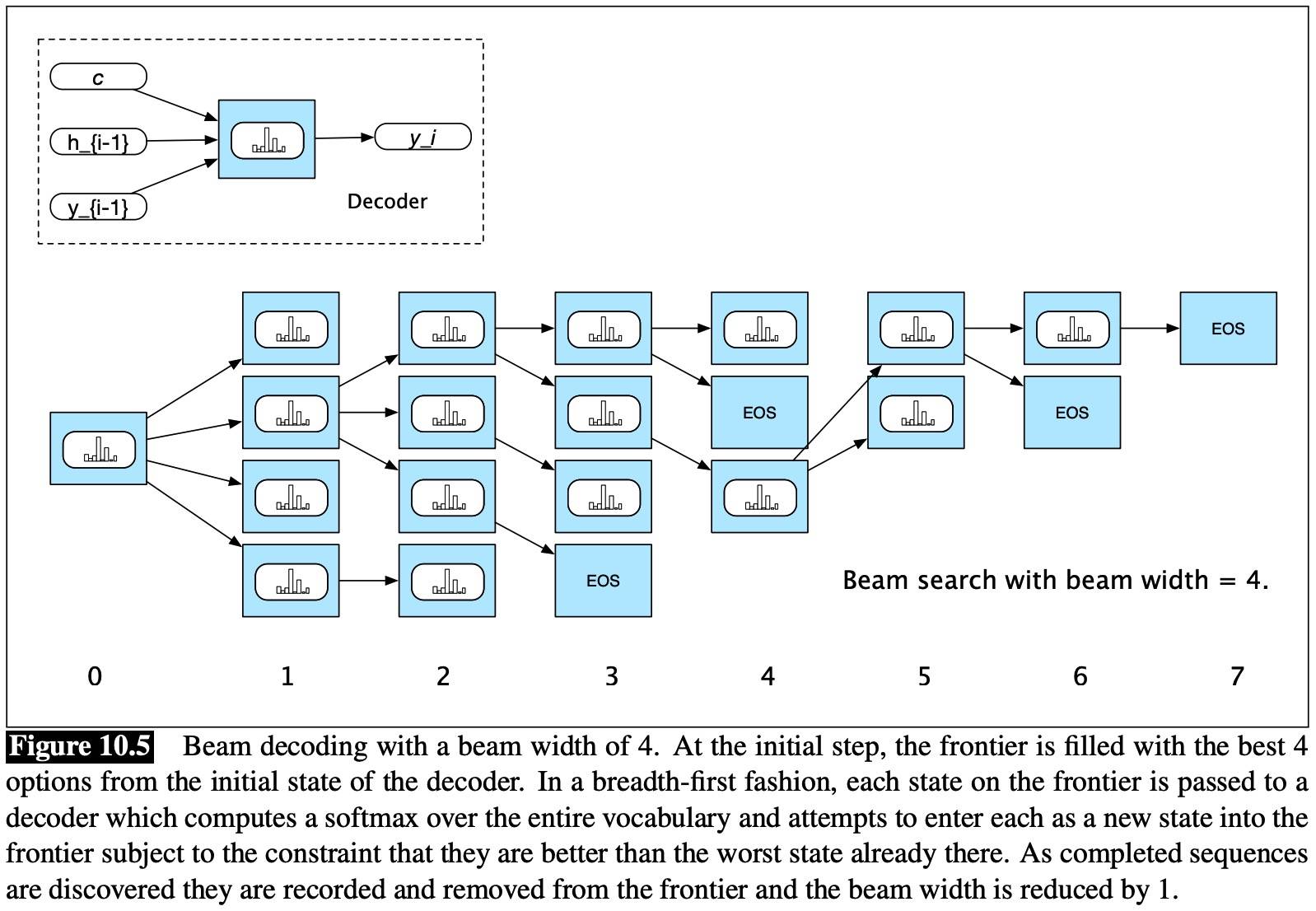
The completed hypotheses may have different lengths. The usual solution is to apply some form of length normalization to each of the hypotheses. With normalization, we have B hypotheses and can select the best one, or we can pass all or a subset of them on to a downstream application with their respective scores.
Context
The number of hidden states varies with the size of the input, making it difficult to just use them directly as a context for the decode. The basic approach is just use the final hidden state of the encoder as c. However, it is more focused on the latter parts of input sequence, rather than the input as whole. One solution to this problem is to use Bi-RNNs, the context can be a function of the end state of both the forward and backward passes.
Attention
To overcome the deficiencies of these simple approaches to context, we’ll need a mechanism that can take the entire encoder context into account, that dynamically updates during the course of decoding, and that can be embodied in a fixed-size vector. Taken together, we’ll refer such an approach as an attention mechanism.
It is generated anew with each decoding step i and takes all of the encoder hidden states into account in its derivation. Then make this context available during decoding by conditioning the computation of the current decoder state on it, along with the prior hidden state and the previous output generated by the decoder.
Score is a measure of encoder hidden state and decoder hidden state. Ws learns which aspects of similarity between the decoder and encoder states are important to the current application.
Normalized αij, tells us the proportional relevance of each encoder hidden state j to the current decoder state i.
Compute a fixed-length context vector for the current decoder state by taking a weighted average over all the encoder hidden states.
