Paper: coling2018_attribute.pdf
code: thunlp/attribute_charge
核心思想:基于类别属性的注意力机制共同学习属性感知和无属性的文本表示。
这是 COLING2018 上的一篇老论文了,最近因为一些事情正好遇上,当时大概看了一下就发现这篇文章正好解决了我之前在做多分类任务时没有解决的问题。所以拿来记录一下,顺便研究下代码。
Abstract
本文主要解决罪名预测(根据刑事法律文书中的案情描述和事实部分,预测被告人被判的罪名)中的两个问题:
- 数据不平衡问题:有些罪名的 case 太少
- 标签相似的问题:有些罪名意思过于接近
文章通过提取罪名相关属性作为额外特征,不仅为 case 少的罪名类别提供了信息,同时还可以作为鉴别相似标签的有效信号。结果在 few-shot 场景下比 baseline 取得 50% 的提升。
看到这里当时就有两个反应:卧槽,为啥这么简单我没想到?卧槽,为啥这么简单的方法效果居然这么好?
Introduction
传统的做法是人工设计特征,包括文本相关(字、词、短语)和属性特征相关(日期,位置,条款,类型),目前基本都是用深度学习的方法在做了。
不过依然有两个主要挑战:
- Few-Shot Charges:实际场景中,最多的 10 种罪名占了 78.1%,最少的 50 种罪名仅占不到 0.5% 而且大部分就 10 个左右的案例。传统的方法一般忽略少的,深度学习需要一定量的训练样本。所以,这个问题成为决定一个系统鲁棒性和有效性的关键。
- Confusing Charges:比如(盗窃,抢劫),(挪用资金,挪用公款),它们的定义仅在验证特定行为时有所不同,对应案例中的条件常常非常相似。
为了解决这两个问题,本文建议考虑具有区别罪名的法律属性,并将这些属性作为犯罪事实描述和罪名之间的映射。具体而言,选中 10 个有代表属性的罪名,然后进行低成本类别级构建:对每个罪名,注释每个属性的值(是,否或不可用)。
有了属性注释后,本文提出一个多任务学习框架来同时预测每个案例的属性和罪名。在模型中,使用属性注意力机制来捕获与特定属性相关的关键事实信息。之后,将这些属性感知与无属性事实表征(文本表征)结合起来,预测最终的罪名。
这样做的两个原因:
- 这些属性可以提供有关如何区分相似罪名的明确知识。
- 所有罪名共享这些属性,知识可以从高频罪名转向低频罪名。
本文的三个主要贡献:
- 首先专注于 Few-Shot Charges 和 Confusing Charges。
- 提出了一种新颖的多任务学习框架,以共同推断案件的属性和指控。采用注意力机制学习属性感知的事实表示。
- 在真实数据集上结果优于其他基准,在 few-short 罪名上的提升超过 50%。
Related Work
Zero-Shot Classification
与计算视觉中的 Zero-Shot 相关。有许多基于属性的模型,属性在不同类别间共享并提供中间表示。
- Lampert et al. (2014) 提出了 direct attribute prediction 和 indirect attribute prediction,并提出可以预训练,当需要寻找新的合适的对象类别时就不用再训练的属性分类器。
- Akata et al. (2013) 提出将基于属性的分类任务转为标签 embedding 任务。
- Jayaraman, Grauman (2014) 引入随机森林方法,强调了未知类别属性预测的不可靠性。
除了属性外,还可以引入其他信息:
- Elhoseiny et al. (2014) 使用标签的文本描述在文本特征和视觉特征之间传递知识。
- Zero-Shot 除了用在 object recognition 外,还被用于 activity recognition 和 event recognition
Charge Prediction
法律领域一直致力于自动裁决。
- Kort (1957) 使用定量方法计算事实元素的数值预测。
- Nagel (1963) 利用相关性分析对重新分配案件进行预测。
- Keown (1980) 引入数学模型,如线性模型和最近邻。
这些模型通常限于标签少的小型数据集。
在机器学习兴起时,问题转化为文本分类,通常需要从案例中提取特征。
- Lin 等 (2012) 提取 21 个法律因素标签分类。
- Mackaay 和 Robillard (1974) 提取了 Ngram 和通过语义相似 Ngram 聚类得到的主题作为特征。
- Sulea 等 (2017) 提出了基于 SVM 继承的系统,使用案例描述,案例的裁定和时间跨度作为输入。
不过这些方法只能提取在大数据集上难以收集的浅层语义表征或手动标签,而且,常规模型无法捕捉相似犯罪之间的细微差别。
随着深度学习的兴起,Luo et al. (2017) 提出了一个分层注意力网络同时预测罪名并提取相关文章。
Method
Discriminative Charge Attributes
为所有罪名引入了 10 个判别属性,对每个(罪名,属性)对,可以标记为是,否或不可用)。比如,故意杀人罪的指控在故意犯罪上标记为 “否”,在死亡时标记为 “是”,在国家机关标记为 “不适用”。对特定属性,特定案件的标签和相应罪名的标签应相同或不冲突。在实践中,手动标记了 149 种不同罪名的属性,然后为每个案例分配与其相应罪名相同的属性。
Formalizations
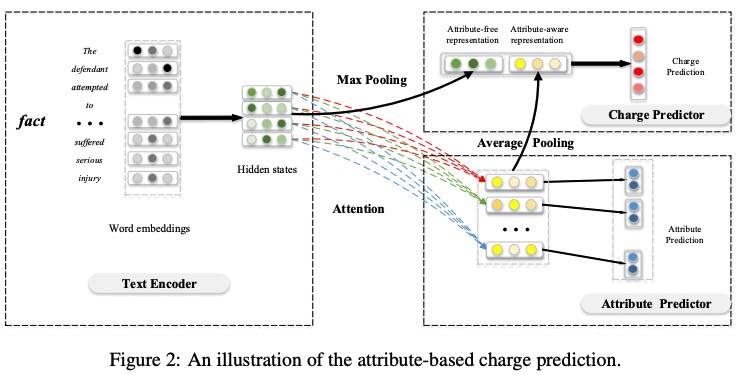
Charge Prediction
给定犯罪事实文本,预测一个罪名
Attributes Prediction
二分类任务,给定犯罪事实文本,预测每个属性的分类
Fact Encoder
LSTM + Max-Pooling 获得无属性文本表征
s 是 hidden states 的维度。n 是 time step。也就是取了每个 hidden state 中的最大值提出来重新组成一个向量作为句子的表征。
Attentive Attribute Predictor
采用注意力机制从犯罪事实文本中选择相关信息并生成属性感知的事实表示。
Step1: 输入为 hidden states 序列:h = {h1, ..., hn}
Step 2: 然后计算所有属性的 attention weights a = {a1, ..., ak},ai = [ai1,...ain]:
ui 是第 i 个属性的上下文向量,用于计算元素对属性的信息程度。Wα 是所有属性共享的权重矩阵。
Step3: 然后得到属性感知的表示:g = {g1, ..., gk},gi = Σt ait ht
Step4: 最后用 g + softmax 获得 p 的预测结果:
Output Layer
属性无关 + 属性感知表示预测最终的罪名:
Optimization
包括两部分
Part1: 最小化预测罪名和真实罪名分布的交叉熵(C 是罪名总数)
Part2: 最小化每个属性预测分布和真实分布的交叉熵(求和是或否的 loss)
Ii 指示 label 是 yes/no (Ii=1) 还是 NA(Ii=0)
最终的 loss function(α 是超参数):
Experiments
Dataset Construction
数据来源:中国判决文书网
简单起见,将多个罪名的调整为一个罪名;同时为了检查模型在 few-shot 任务中的表现,将罪名调成为 149 个完全不同的(每个罪名至少包含 10 个案例)。
随机选择了 40 万案例构建了三个不同量级的数据集,它们包含的罪名相同,只是数量不同。
Attribute Selection and Annotation
如何选择属性呢?
- 训练一个基于 LSTM 的罪名预测模型,在验证集上得到预测结果的混淆矩阵。
- 筛选出相似罪名(标签相似)对,专家从中定义出 10 个能狗区分这些相似罪名的、有代表性的属性。
- 使用这 10 个属性对所有的罪名低成本标注,所谓的低成本意思是只对 149 个罪名手动标注,而不是对所有的案例进行标注。
全文最经典的部分了。很聪明、优雅的做法。
Baselines
多个文本分类模型 + 一个罪名预测模型:
- TFIDF + SVM:TFIDF 提取特征
- CNN
- LSTM
- Fact-Law Attention Model: Luo et al. (2017)
Experiment Settings and Evaluation Metrics
- max sequence length: 500
- TFIDF feature size: 2000
- Skip-Gram pre-train word embeddings (size 100)
- LSTM hidden state size: 100
- CNN filter (2, 3, 4, 5), filter size 25
- α = 1
- Adam
- lr = 0.001
- dropout = 0.5
- batch size 64
- Macro-F1
Results and Analysis
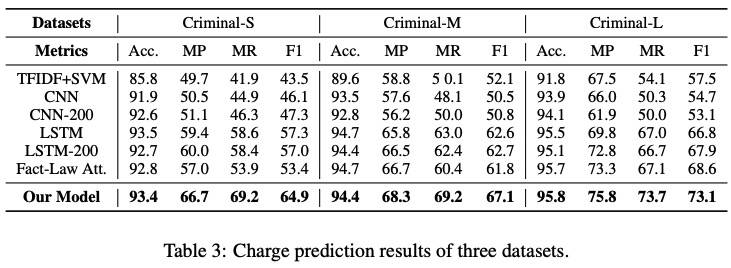
Few-Shot 任务的结果:(Low,≤ 10;High,> 100)
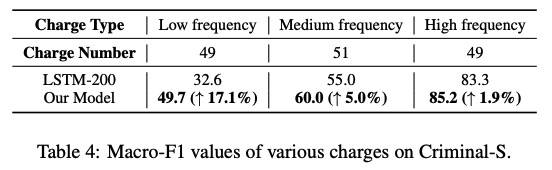
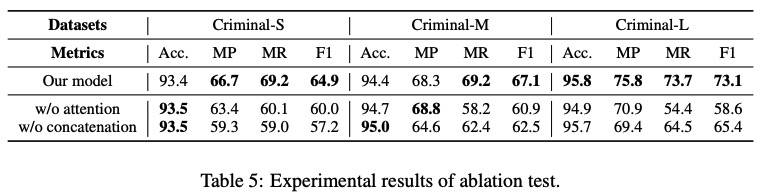
Ablation Test
- 取消注意力机制时,对每个属性,将注意力机制替换为全连接层。
- 取消属性感知表示时,退化为基于 LSTM 的典型多任务学习。
Case Study
江苏省南京市江宁区人民检察院指控,2013年4月2109时许, 被告人朱某在南京市江宁区横溪街道UNK社区美尚家具厂门前 ,因驾车问题与于某甲发生争执,后朱某纠集他人至美尚家 具厂车间内,持铁棍、斧子等工具对于某甲实施殴打,被害 人尤某在帮助于某甲抵挡时被砍伤,UNK某右侧顶骨骨折等 损伤经南京市公安局江宁分局法医鉴定,被害人尤某的损伤程度为轻伤
这个案件被判为故意伤害罪,故意伤害罪和骚扰是一对相似类别,都和暴力有关。一个重要的区别就是故意伤害罪有 “身体伤害” 的特征。
所以 Physical Injury 这个属性在这里一定是非常重要的,事实上模型也正确预测了 Physical Injury 的 label 是 yes,最终的罪名也预测为 “故意伤害罪”,相反,LSTM-200 则把结果预测为 “骚扰”。
从下面的注意力热力图也可以看出,注意力机制能够捕获当前属性相关的关键模式和语义。

Conclusion
为解决 Few-Shot 和标签相似问题,引入了判别法律属性,提出了基于属性的多任务学习模型。具体来说,模型通过利用基于属性的注意力机制来共同学习无属性和属性感知的事实表示。进一步的探索方向包括:更复杂的案件判断(如多标签)和更复杂的罪名属性。