Paper: ELECTRA: PRE-TRAINING TEXT ENCODERS AS DISCRIMINATORS RATHER THAN GENERATORS
本来代码还没出来不想看的,不过前段时间确实太火了,先偷偷瞄一眼,看看到底是什么个情况。
核心思想:Replaced token detection Task + Transformer。
Abstract
相比 MLM(Masked Language Modeling)的改进是:将 Mask 改为一个生成器生成的 token(看起来似乎是真的),然后用一个判别器识别每个 token 是否是生成器生成的。
这想法不就是 GAN 么,能想到这种骚操作也是够机智的。
Introduction
Bert 使用了 Masked LM,XLNet 使用了 PermutationLM。本文使用了替换 token 检测,这些替换的 token 生成自一个 MLM 模型,解决了 Bert 预训练与精调由于人工 Mask 带来的效果差异;同时由于判别器是针对每一个 token 的,比起 MLM 的 15% 在计算上更有效率。作者这里也提到了,虽然很像 GAN,但其实并不是,他们的生成器是用极大似然训练的。
本文的模型被称为:ELECTRA,即 Efficiently Learning an Encoder that Classifies Token Replacements Accurately,结果无论是计算还是参数方面都比现有模型更有效率。
Method
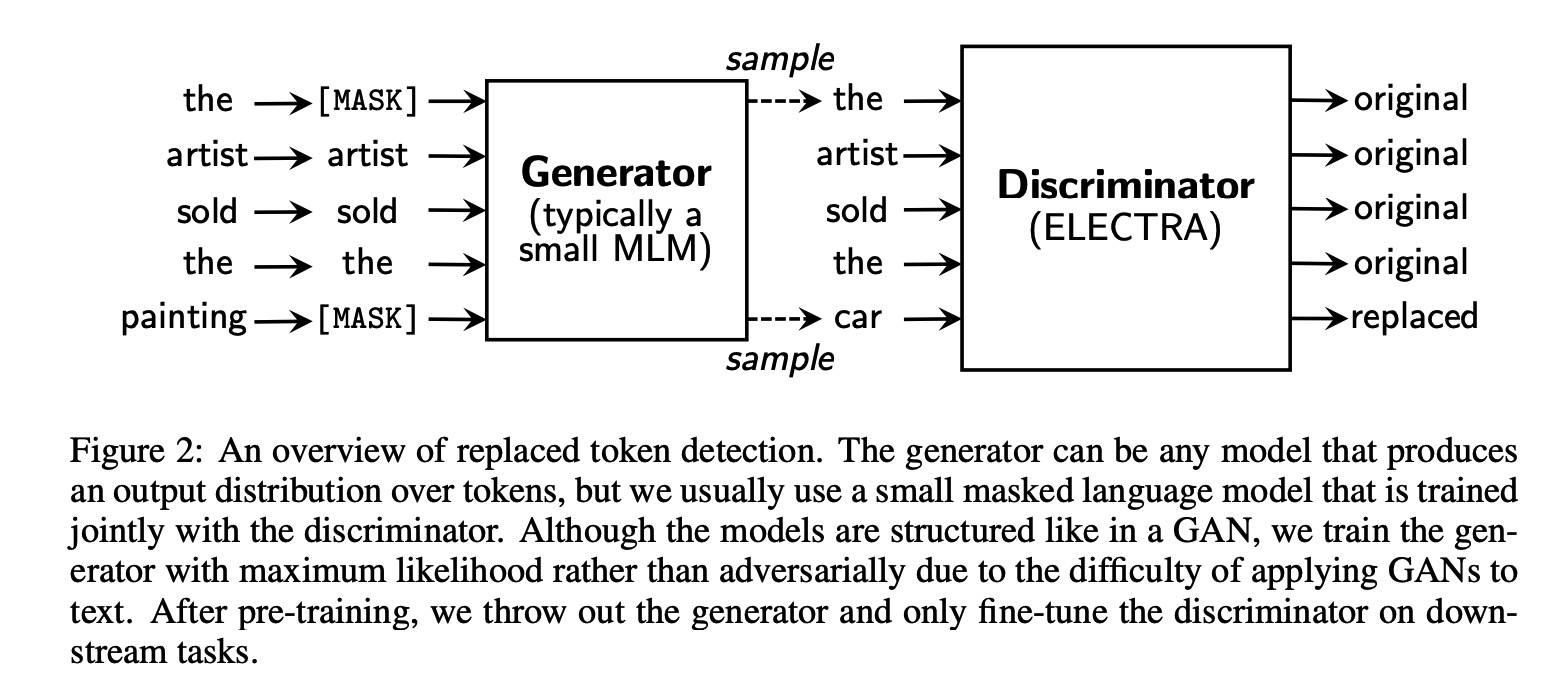
训练了两个网络:生成器 G 和判别器 D,均包含了一个 Transformer 的 encoder(将 input 的序列表示成隐向量表示)。给定位置 t,G 接 softmax 生成 xt:
e 表示 token embedding。
对给定位置 t,D 判断 xt 来自 G 还是原始的数据分布:
G 用来执行 MLM,给定输入序列 X(x1…xn),首先随机选择一组(15%)mask 的位置,这些位置的 token 被替换为 [MASK],G 要学习最大化 masked-out tokens 的似然,D 要区分被 G 生成的 sample 替换的 token。具体而言,通过替换 masked-out tokens 为 generator samples 创建损坏的 X 序列,然后训练判别器来识别 X 中的 tokens 和原始的 input 序列是否匹配。
形式上看:
与 GAN 的不同点:
- 如果 G 生成的 sample 是原始的 token,这个 token 将被看作 “real” 而不是 “fake”
- G 用极大似然法训练而不是对抗方法去迷惑 D
- G 的 input 不是 GAN 中的噪声向量
另外:
- D 的 loss 没有反向传播到 G
- 预训练后丢掉 G,在下游任务上精调 D
不熟悉 GAN 的可以看这里。
近很长一段时间以来看论文都发现 Method 篇幅越来越小,实验导向很明显。不过作为工程师,我们只关注思想和最后的应用,实验还是交给这些研究机构吧。
Experiment
所以这块我们记录一下关键点,过一下就行了。
Setup
Dataset: GLUE, SQuAD
Training Data: Bert (most), XLNet (Large)
Model architecture and most hyper-parameters: Bert
Small evaluation dataset with the median of 10 fine-tuning runs
Extensions
Weight Sharing: 小的 Generator 更有效,因此只共享了 D 和 G 的 embeddings(token + position)。
Smaller Generators: 主要通过减少 layer size 缩小模型,G 的 size 是 D size 的 1/4-1/2 时效果最好,作者猜测太强的 G 会阻止 D 进行有效地学习,具体而言就是 D 的大量参数用来给 G 建模,而不是真实的数据分布。
Training Algorithms: 推荐联合训练 G 和 D,但作者还尝试了其他的训练方法:
- 两步训练:训练 n 步 G,用 G 的参数初始化 D(G 和 D 大小一样),固定 G 的参数,训练 n 步 D。这种方法有时候甚至无法学习,作者猜测可能是 G 超过 D 太多。
- 像 GAN 一样训练 G:使用强化学习适应离散的采样。效果不如采用极大似然,作者猜想主要是以下原因(也是 GAN 在文本训练中已经观察到的问题):
- 对抗训练的 G 在 MLM 上更差,主要是强化学习在文本生成的大的操作空间下采样效率太低。
- 对抗训练的 G 会产生多峰低熵分布(大部分概率聚集在单个 token 上),意味着 G 的 sample 缺乏多样性。
Small
sequence length: 512 -> 128
batch size: 256 -> 128
model hidden dimension: 768 -> 256
embeddings: 768 -> 128
Large
400k steps with batch size 2048 on the XLNet data
Efficiency
- ELECTRA 15%: D 的 loss 只来自 15% 的 masked tokens
- Replace MLM: 与 MLM 一致,除了将 masked-out tokens 替换为 G 的 samples
- All-Tokens MLM: 除了与 Replace MLM 一致外,预测 inputs 中的所有 tokens,而不只是 masked tokens

All-Tokens MLM 造成了与 Bert 相比的大部分 gap。另外,模型越小,ELECTRA 超过 Bert 越多。
Related
Self-Supervised Pre-training for NLP
- Word2Vec: 词表示,CBOW,Skip-gram
- ELMO: 双向 LM(Bi-LSTM)+ 下游任务(首次两阶段)
- GPT: 单向 LM + Transformer + 下游任务(首次 Transformer)
- Bert: 双向 LM(MLM) + Transformer + 多任务 + 下游任务
- MASS and UniLM extend BERT to generation tasks by adding auto-regressive generative training objectives
- ERNIE 和 SpanBERT mask 连续的 token
- RoBERTa 剔除了 NSP 任务,使用了动态 Mask
- DistilBERT 是蒸馏版本
- XLNet: 双向 LM(PLM)+ Transformer + 下游任务
- XLNet masks attention weights such that the input sequence is auto-regressively generated in a random order
- ELECTRA: 双向 LM(Replaced token detection)+ Transformer + 下游任务
Conclusion
为语言表示学习提出一种新的 self-supervised 任务:replaced token detection,核心思想是训练一个 text encoder 来区别 input 的 token 和一个小的 Generator 生成的高质量的 negative sample。相比 MLM 训练效率更高,且在下游任务取得更好的表现。