In NLP, logistic regression is the baseline supervised machine learning algorithm for classification.
- discriminative classifier: like logistic regression
- only trying to learn to distinguish the classes.
- directly compute $$P(c|d)$$
- generative classifier: like naive Bayes
- have the goal of understanding what each class looks like.
- makes use of likelihood term $$P(d|c)P©$$
A machine learning system for classification has four components:
- A feature representation of the input
- A classification function that computes $$\hat y$$, the estimated class, via $$p(y|x)$$. Like sigmoid and softmax.
- An objective function for learning, usually involving minimizing error on training examples. Like cross-entropy loss function.
- An algorithm for optimizing the objective function. Like stochastic gradient descent.
Classification: the sigmoid
Logistic regression solves task by learning from a training set, a vector of weights and a bias term (also called intercept).
decision boundary:
y^ = 1 if P(y=1|x) > 0.5, otherwise = 0
Designing features: Features are generally designed by examining the training set with an eye to linguistic intuitions and the linguistic literature on the domain. For logistic regression and naive Bayes combination features or feature interactions have to be designed by hand.
For many tasks we’ll need large numbers of features, they are created automatically via feature templates, abstract specifications of features.
In order to avoid the extensive human effort of feature design, recent research in NLP has focused on representation learning: ways to learn features automatically in an unsupervised way from the input.
Choosing a classifier: Naive Bayes has overly strong conditional independence assumptions. If two features are strongly correlated, naive Bayes will overestimate the evidence.
-
Logistic regression generally works better on larger documents or datasets and is a common default.
-
Naive Bayes works extremely well on very small datasets or short documents, also easy to implement and very fast to train.
Learning in Logistic Regression
- The distance between system output and gold output is called loss function or cost function.
- Need an optimization algorithm for iteratively updating the weights so as to minimize the loss function.
The cross-entropy loss function
L(y^, y) = How much y^ differs from the true y
MSE loss: $$L_{MSE}(\hat y, y) = \frac{1}{2} (\hat y -y)^2$$
It’s useful for some algorithms like linear regression, but becomes harder to optimize (non-convex) when it’s applied to probabilistic classification.
Instead, we use a loss function that prefers the correct class labels of the training example to be more likely. This is called conditional maximum likelihood estimation: we choose the parameters w,b that maximize the log probability of the true y labels in the training data given the observations x. The resulting loss function is the negative log likelihood loss, generally called the cross entropy loss.
We’d like to learn weights that maximize the probability of the correct label p(y|x). Since there are only two discrete outcomes (1 or 0):
A perfect classifier would assign probability 1 to the correct outcome (y=1 or y=0) and probability 0 to the incorrect outcome. That means the higher ˆy (the closer it is to 1), the better the classifier; the lower ˆy is (the closer it is to 0), the worse the classifier. The negative log of this probability is a convenient loss metric since it goes from 0 (negative log of 1, no loss) to infinity (negative log of 0, infinite loss).
This loss function also insures that as probability of the correct answer is maximized, the probability of the incorrect answer is minimized; since the two sum to one, any increase in the probability of the correct answer is coming at the expense of the incorrect answer.
We make the assumption that the training examples are independent:
Gradient Descent
Gradient descent is a method that finds a minimum of a function by figuring out in which direction
(in the space of the parameters θ) the function’s slope is rising the most steeply, and moving in the opposite direction.
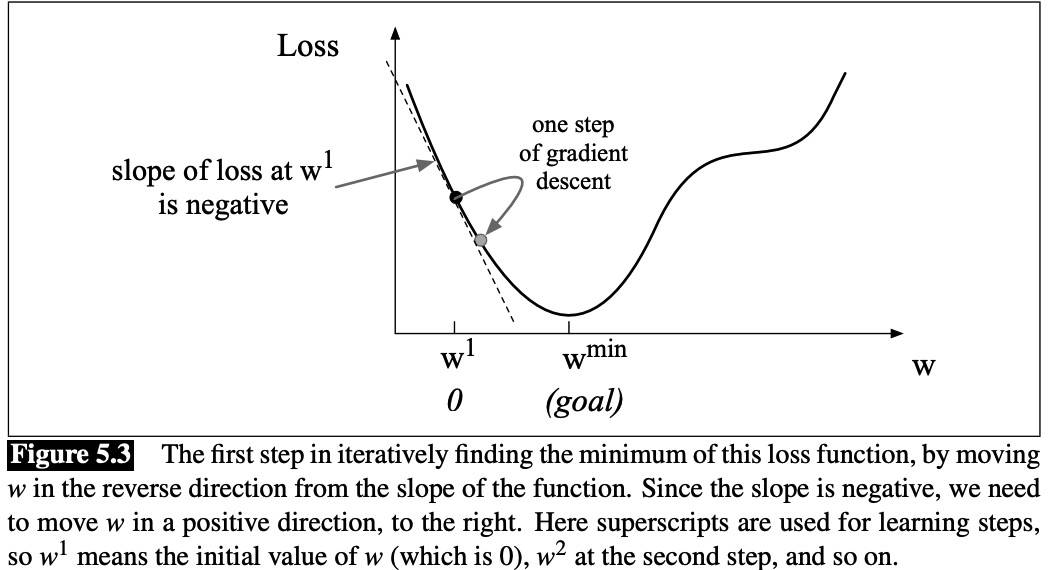
The magnitude of the amount to move in gradient descent is the value of the slope d/dw f(x;w) weighted by a learning rate η:
The Gradient for Logistic Regression
The Stochastic Gradient Descent Algorithm
1 | function STOCHASTIC GRADIENT DESCENT (L(), f(), x, y) returns θ |
The code is here: Stochastic-Gradient-Descent
Regularization
If the weights for features fit too perfectly, noisy factors just accidentally correlate with the class. This problem is overfitting. To avoid overfitting, a regularization term is added to the objective function:
R(w) is used to penalize large weights. There are two common regularization terms R(w):
- L2 regularization, also called ridge: $$R(W) = |W|2^2 = \sum{j=1}^N w_j^2$$
- easier to optimize because of simple derivative
- prefers weight vectors with many small weights
- α = λ/2m
- L1 regularization, also called lasso: $$R(W) = |W|1 = \sum{j=1}^N |w_j|$$
- more complex because the derivative of |w| is non-continuous at zero
- prefers sparse solutions with some larger weights but many more weights set to zero
- α = λ/m
Both L1 and L2 regularization have Bayesian interpretations as constraints on the prior of how weights should look.
- L1 can be viewed as a Laplace prior on the weights
- L2 corresponds to assuming that weights are distributed according to a gaussian distribution with mean is 0
Multinomial logistic regression
Use multi-nominal logistic regression, also called softmax regression.
Σ is used to normalize all the values into probabilities.
Features in Multinomial Logistic Regression
A feature might have a negative weight for 0 documents, and a positive weight for + or - documents.
Learning in Multinomial Logistic Regression
The gradient is:
Interpreting models
Logistic regression can be combined with statistical tests (the likelihood ratio test, or the Wald test); investigating whether a particular feature is significant by one of these tests, or inspecting its magnitude (how large is the weight w associated with the feature?) can help us interpret why the classifier made the
decision it makes. This is enormously important for building transparent models.
Summary
- Logistic regression is a supervised machine learning classifier that extracts real-valued features from the input, multiplies each by a weight, sums them, and passes the sum through a sigmoid function to generate a probability. A threshold is used to make a decision.
- Logistic regression can be used with two classes or with multiple classes (use softmax to compute probabilities).
- The weights (vector w and bias b) are learned from a labeled training set via a loss function, such as the cross-entropy loss, that must be minimized.
- Minimizing this loss function is a convex optimization problem, and iterative algorithms like gradient descent are used to find the optimal weights.
- Regularization is used to avoid overfitting.
- Logistic regression is also one of the most useful analytic tools, because of its ability to transparently study the importance of individual features.