本文介绍两篇与DPO以及其他RL算法相关的。R1-Zero在表现出潜力后,GRPO自不必多说,得到大家关注。PPO、Reinforce++等也被用来尝试实验,结果也很亮眼。既然如此,其他RL算法可以吗,尤其是前LLM时代流行的DPO。于是就有了本文的两篇研究。
Online-DPO-R1
首先是这篇:
Online-DPO-R1: Unlocking Effective Reasoning Without the PPO Overhead
这篇Paper的出发点很简单,就是想看看其他RL算法能否R1-Zero。本文尝试iterative DPO和reward-ranked fine-tuning (RAFT),后者其实就是FT。
核心观点如下:
- DPO和RAFT都能提升模型性能(意味着有效果)。
- Iterative DPO并不会从Negative Log-Likelihood (NLL) 损失中受益。个人猜想可能负样本只是结果不对,其中推理过程很多地方可能还是对的,NIL在这种情况下甚至带来负面影响(结果的确如此,加了NIL性能反而比没加有轻微下降)。
- Iterative DPO从多样化的提示词中受益(训练数据的多样性更重要,这点已经被验证的很清楚了),比PPO受益更多。个人猜想可能和DPO直接优化目标有关,更多数据时效果就相对比较明显。
- LLaMA3系列在iterative DPO+基于规则的奖励下并不生效,说明基于规则的成功可能来自Qwen模型的预训练阶段(这个也是被验证了的)。
- 与PPO相比,DPO和RAFT都稍微差了一些,DPO比RAFT强一些(负样本的作用),不过DPO+SFT预热能达到PPO相当的效果。
从这些观点我们可以概括出一些Common Sense,也是我们一直以来看到和验证过的:
- Base模型有推理能力,RL才能将该能力激活。
- 多样化的数据比算法设计更重要。
- 任何RL算法应该都有效,不过PPO/GRPO依然在第一梯队。
另外是关于DPO的:
- DPO比直接FT更好些。
- 数据更多时,DPO比PPO更好些。
- NIL在此类任务中可能没有效果,但负样本本身是有意义的。
- SFT+DPO和SFT+PPO一样,依然取得最好的效果。
方法:Iterative DPO
如下图所示:

采样8个输出,reward最高和最低的构成pair对数据,分一样就丢掉那条数据。
RAFT类似,不过只用了正样本(就是得分最高的)数据FT。实际从reward=1的回复中随机选则一条,如果没有1的,就丢掉那条数据。
配置
基础模型:Qwen2.5-MATH-7B-base
数据集:
- 训练:Numina-Math(随机200K)和MATH(7.5k)
- 测试:AIME24, AMC23, MATH500, Minerva Math, 和OlympiadBench
奖励规则,同R1-Zero:
- 格式+答案对:1
- 格式对:-0.5
- 其他:-1
提示词:
1 | <|im_start|>system\nPlease reason step by step, and put your final answer within |
结果
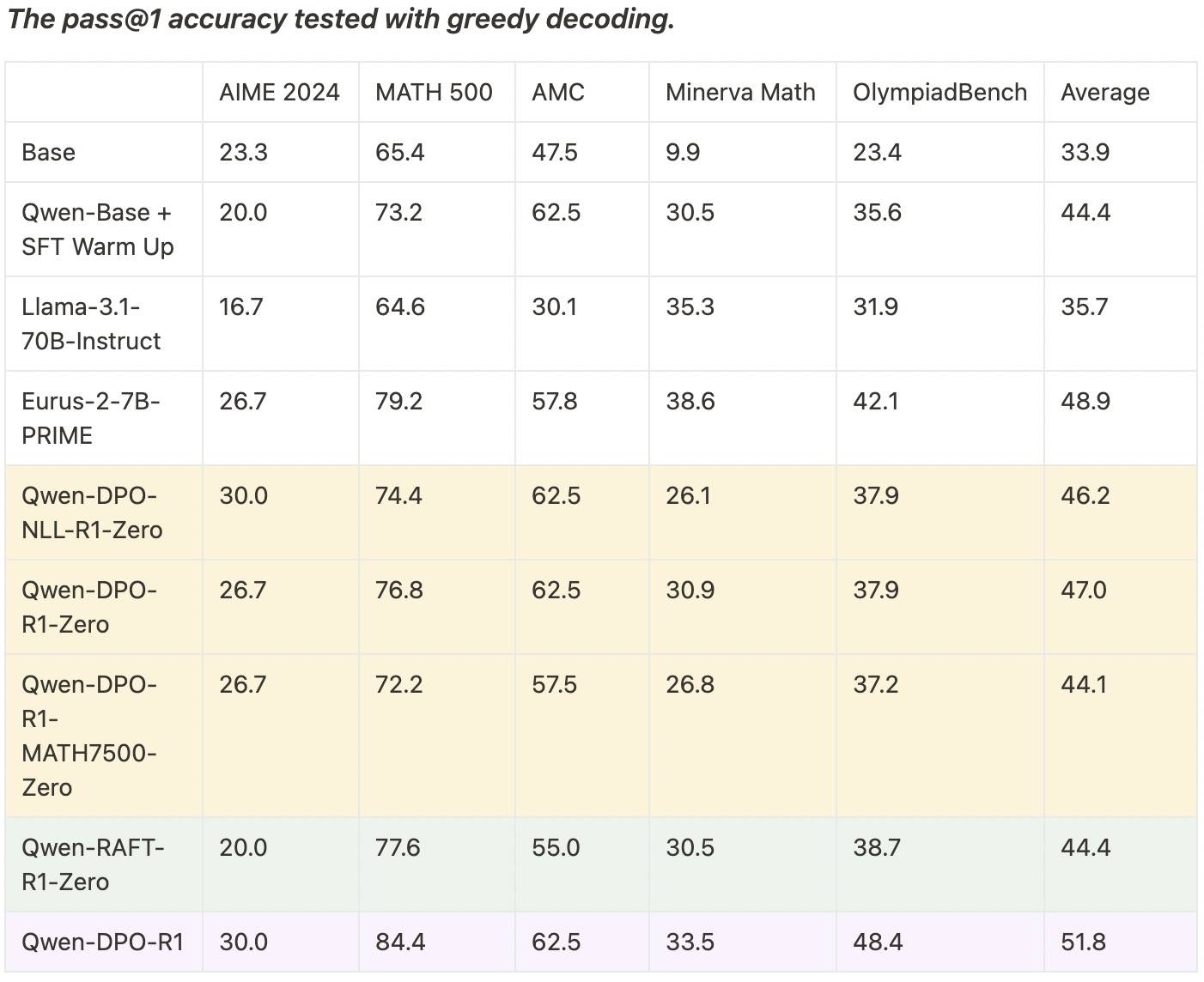
Qwen-DPO-NLL-R1-Zero和Qwen-DPO-R1-Zero是在数据集更多的Numina-Math上训的,效果要比MATH7500好一些,Qwen-RAFT-R1-Zero也是Numina-Math,效果比DPO差一些。注意Qwen-DPO-R1-Zero和Qwen-DPO-R1-MATH7500-Zero,前者用了20k的Numina-Math,效果并没有比MATH7500提升很多(3%),但是比PPO在同等配置下提升多(1.3%)。
另外值得注意的是最后一组,在Qwen-DPO-R1-Zero之前,先在 MATH 训练集上使用QwQ-32B生成15K长CoT数据对模型进行 SFT(这个Warmup是不是数据太多了点……),这一步后效果达到44.4%,和RAFT齐平了,加了DPO后到了51.5%。也就是说SFT+RL的范式取得最好的效果,这点之前DeepScaleR做过验证。
最后说说Aha Moment,这个一开始被很多人莫名神话的东西。本文的发现和oat-zero类似:
- DPO或PPO训练阶段没有观察到Aha Moment。
- 自我反思就在Qwen2.5-MATH-7B-Base中。
- DPO和PPO都不会增加自我反思的频率。
Less is More
又是这个名字,都几篇了!实在起不出来好名字了呀,起名字都要卷死了。要不就叫LIMD吧,D既可以表示Data,也可以表示DPO。我觉得这个名字还不错。
Less is More: Improving LLM Alignment via Preference Data Selection
也是关于DPO的,但是是从“数据选择”方向改进DPO的。具体方法是:最大化间隔原则。是不是和SVM有点像;)
为了准确估计用于数据选择的间隔,提出了一种_双间隔引导(dual-margin guided)_方法,该方法同时考虑外部奖励间隔和DPO内部隐式奖励间隔。
效果:10%的数据带来3%-8%的提升。而且可以扩展到iterative DPO,用25%的在线数据带来3%的性能提升。
是不是感觉本文提出的方法和前面那篇很配;)
迄今为止我们已经见过三种比较完善的数据筛选方法了:LIMO、LIMR和本文LIMD,用的训练方法分别是SFT、PPO和DPO,想想觉得蛮有趣的。
本文的出发点是,我们对偏好学习的数据驱动方面的理解依然存在一个关键gap:偏好数据的哪些特征对模型对齐贡献最大?
本文的主要贡献如下:
- 证明了数据选择的必要性。具体而言,奖励模型中固有的噪声可能会颠倒响应对之间的偏好, 从而引发参数收缩问题。证明了基于间隔的选择准则可以通过引导参数膨胀有效缓解该问题。
- 融合了外部奖励集成信号和DPO 内部隐式奖励信号的最大化间隔(margin maximization)数据筛选原则。
- 扩展到Iterative DPO,证明对在线数据进行选择性采样可以同时降低计算成本并提升模型性能。
方法论
关于参数收缩:奖励模型的不准确性可能导致LLM的参数收缩趋近于零。通过选择具有更大边界的数据可以弥补这种收缩带来的性能下降。参数收缩与膨胀之间的平衡为提升LLM的性能提供了潜在的优化空间。Loss推导见附录。
双间隔 (DM) 引导的高效偏好数据选择
包括两步:
- 计算外部和隐式奖励。
- 融合这些奖励以抑制噪声,并实现更可靠的间隔估算。
Step1:计算奖励
外部奖励:
一个外部奖励模型,Skywork-Reward-Llama-3.1-8B-v0.2(目前 RewardBench Leaderboard 最好的)。
隐式奖励:
这里用的policy模型建议和目标policy区分开(就是额外训一个模型,Llama-3.2-3B SFT+2000条随机数据)。
Step2:间隔融合
最简单的融合方法就是相加(DM-ADD),比较宽松,任何一个间隔大都可以。
严格的版本(DM-MUL)是任何一个间隔小表示样本没价值。言下之意要减轻异常值(尤其是某一个间隔非常小的情况)的不利影响。
首先做一个简单线性变换:
clip(m) = min(max(m, M1), M2)),(M1, M2)是可调整参数。
根据A3S: A General Active Clustering Method with Pairwise Constraints中的融合规则最终得到:
Step3:选择最大融合间隔的样本。
实验
基本配置:
- 数据集:Reddit TL;DR、HH、UltraFeedback、LlamaUltraFeedback and Mistral-UltraFeedback。后2个数据集的chosen和rejected替换为最高、最低分的响应,生成5个候选,PairRM打分。
- 基础模型:Llama-3.23B、Llama-3-8B、Mistral-7B,Base+Instruct。Base模型先训练了最基本的指令遵循能力。
- 评测集:TL;DR 和HH验证/测试集随机400条。UltraFeedback使用AlpacaEval and AlpacaEval 2.0,共805条。GPT-4作为代替人工评价。
- Baseline:RANDOM、IFD、M-Ex/IM。
- Conditional Perplexity (IFD):利用Token概率衡量信息量,利用chosen和rejected响应的IFD分数差异来选择数据。
- M-Ex/Im:External/Implicit Margin。
- 对后两种,把数据集分成三类:TOP (最高正差)、MID (接近零差)和 BOT (最低负差)子集。
- IDF-MID被称为Low-Gap,chosen和rejected比较相似。
结果
首先是整体评估。
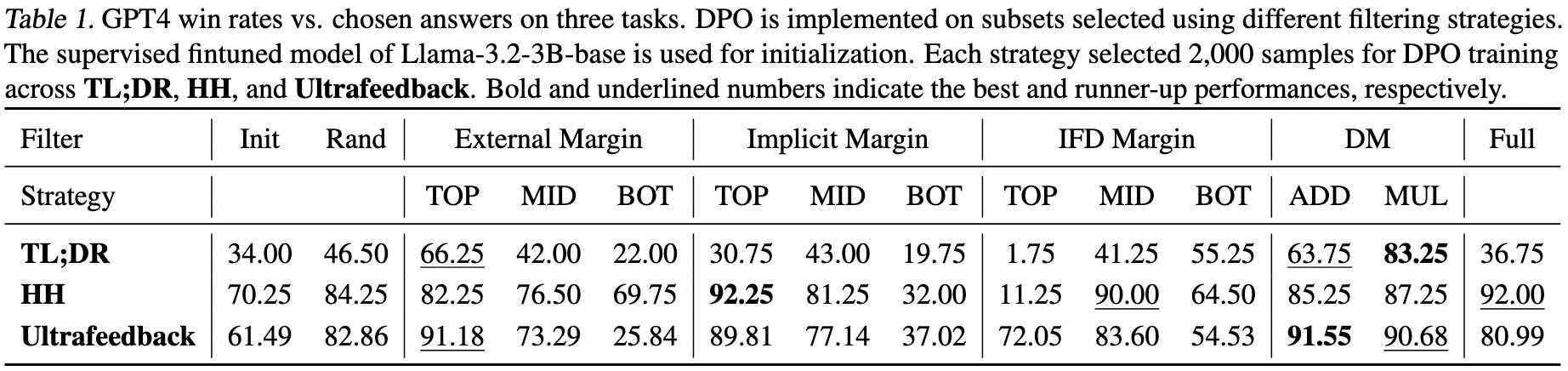
结果如下:
- DM在每个任务上表现都接近最优,没有其他对照组的短板。
- 更多的数据训DPO不一定能产生更好的结果(2-5%的数据超过所有数据)。
- 不同奖励间隔在不同任务上表现不同。
接下来分析DM。
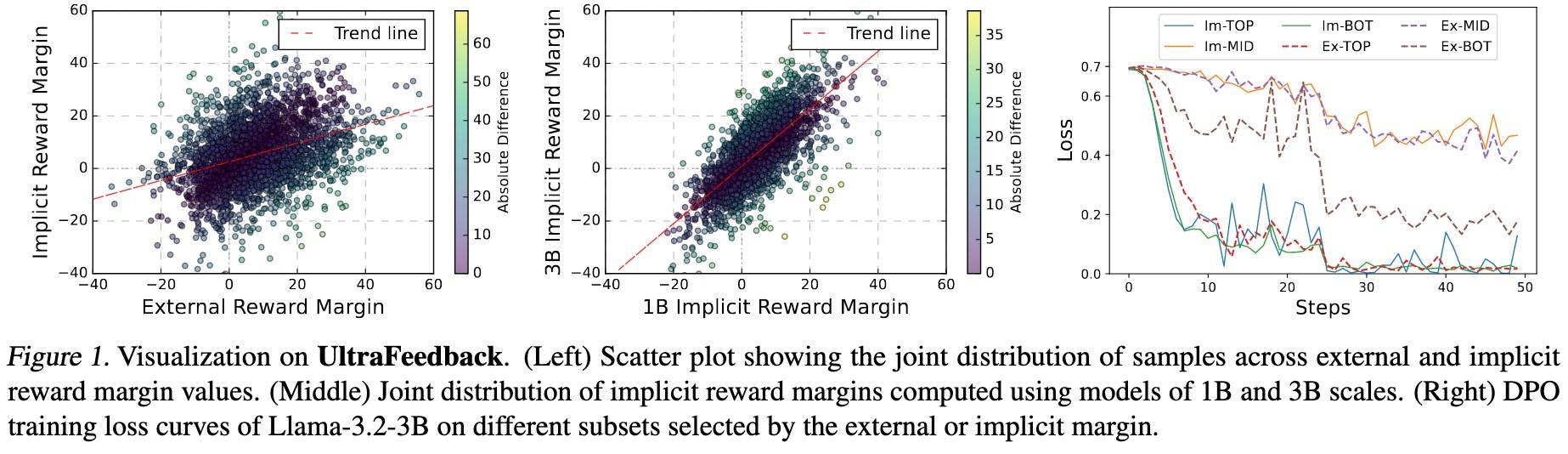
结果如下:
- 隐式奖励间隔和外部奖励间隔相关性较弱,说明两种奖励捕捉到了不同的偏好模式,说明集成的重要性。
- 不同大小模型计算的隐式奖励间隔之间具有较强的相关性。说明使用额外训一个小模型计算隐式奖励间隔的设计是合理的。
消融
结果如下:
- 数据筛选对于其他模型(Mistral)仍然有效。
- 数据筛选在其他DPO变体算法中(IPO、KTO、SLiC)也有效。
- 数据筛选对不同超参数(β、LR)均有效。
Appendix
RM ω Loss
根据论文可知win与loss的真实间隔为:
于是有:
反过来:
根据交叉熵损失,可得:
前者表示win比loss好的概率,后者表示win比loss差的概率。
RM Loss
PPO (RLHF) Loss
DPO Loss
本文已收录至 rl-llm-nlp —— 一份带观点的 post-R1 LLM × RL 编年史与论文索引。如果你对相关话题有想法,欢迎来 Issues 拍砖。