当一句或一段代码运行时,Python 解释器将源代码转为字节码,然后进行词法、语法分析,检查是否有错,如果没有错误就编译并执行,然后将结果返回给。这个流程都由 Jupyter Notebook 自动完成。
CTRL 论文+代码+实践笔记
paper: [1909.05858] CTRL: A Conditional Transformer Language Model for Controllable Generation
code: salesforce/ctrl: Conditional Transformer Language Model for Controllable Generation
核心思想:借鉴多任务,将文本标签作为输入的一部分(放在开头)控制文本生成。
Abstract
文本生成最大的问题是难以对其进行控制,本文发布了一个 1.6 billion 参数的条件 transformer language model,训练能够 govern 风格、内容、特定任务行为等的控制代码。控制代码来自与原始文本共现的结构,保留了无监督学习的优点,同时提供对文本生成更明确的控制。这些控制代码还允许 CTRL 预测训练数据的哪些部分最有可能给出序列。
GraphQL Elixir Glance
There are several problems with the origin docs, so I reproduced this quick glance. It’s much simple and only contains the brief information. Hope this is helpful to u.
Getting Started
Schema-Driven Development
- Define your types and the appropriate queries and mutations for them.
- Implement functions called resolvers to handle these types and their fields.
- As new requirements arrive, go back to step 1 to update the schema, and continue through the other steps.
1 | # Step1: create |
You should see two pieces of items in the links table.
GraphQL Glance
This is a quick and simple glance to the raw document (in the references), maybe you could treat it as a brief note. Hope it’s helpful to u.
At its core, GraphQL enables declarative data fetching where a client can specify exactly what data it needs from an API. GraphQL is a query language for APIs - not databases.
REST vs GraphQL
- Data Fetching: multiple endpoints VS single query
- Over-fetching and Under-fetching (n+1) : fixed data structure VS given exact data
- Rapid Product Iterations on the Frontend: adjust with data change VS flexible
- Insightful Analytics on the Backend: fine-grained insights about the data
- Benefits of a Schema & Type System: type system => schema, frontend and backends can do their work without further communication
Bert 论文笔记
Paper: https://arxiv.org/pdf/1810.04805.pdf
Code: https://github.com/google-research/bert
Bert 的核心思想:MaskLM 利用双向语境 + MultiTask。
Abstract
BERT 通过联合训练所有层中的上下文来获取文本的深度双向表示。
Introduction
两种应用 pre-trained model 到下有任务的方法:
- feature-based:比如 ELMo,将 pre-trained 表示作为额外的特征
- fine-tuning:比如 OpenAI GPT,引入少量特定任务参数,在下游任务中 fine-tuning 所有的参数
现在的技术有个限制,就是只能采用从左到右的单向机制,这对有些任务是不适合的,比如问答。
Bert 通过 “masked language model” 缓和了这个限制,即随机 mask 输入中的一些 token,目标是只根据上下文(左边和右边)预测 mask 掉的原始 vocabulary id。
同时,还联合训练了一个 “next sentence prediction” 的任务用来表示文本对。
Transformer 论文笔记
Paper: https://arxiv.org/pdf/1706.03762.pdf
Code: https://github.com/tensorflow/models/tree/master/official/nlp/transformer
Tool: https://github.com/tensorflow/tensor2tensor
Attention 核心思想:Multi-Head Attention 关注不同位置不同表示子空间的信息,且更容易训练。
Abstract
一个完全基于 Attention 的架构。更容易并行训练,提高训练速度。
Introduction
RNN 的固有属性使其难以并行化(即使通过 factorization tricks 和 conditional computation 可以得到改善),Attention 对依赖关系建模,不考虑输入输出的距离。本文提出的 Transformer 采用了完全的 Attention 机制描述输入和输出的整体依赖关系,在训练速度和效果上都有明显提升。
Longest Palindromic Substring (LeetCode 5)
Given a string s, find the longest palindromic substring in s. You may assume that the maximum length of s is 1000.
Example 1:
1 | Input: "babad" |
Example 2:
1 | Input: "cbbd" |
ERNIE Tutorial(论文笔记 + 实践指南)
ERNIE 2.0 发布了,刷新了 SOTA,而且中文上做了不少优化,这种大杀器作为一个 NLP 工程师我觉得有必要深入了解了解,最好能想办法用到工作中。
ERNIE 2.0 是基于持续学习的语义理解预训练框架,使用多任务学习增量式构建预训练任务。ERNIE 2.0 中,新构建的预训练任务类型可以无缝的加入训练框架,持续的进行语义理解学习。通过新增的实体预测、句子因果关系判断、文章句子结构重建等语义任务,ERNIE 2.0 语义理解预训练模型从训练数据中获取了词法、句法、语义等多个维度的自然语言信息,极大地增强了通用语义表示能力。
这是官方的描述,我觉得那张配图可能更加直观:
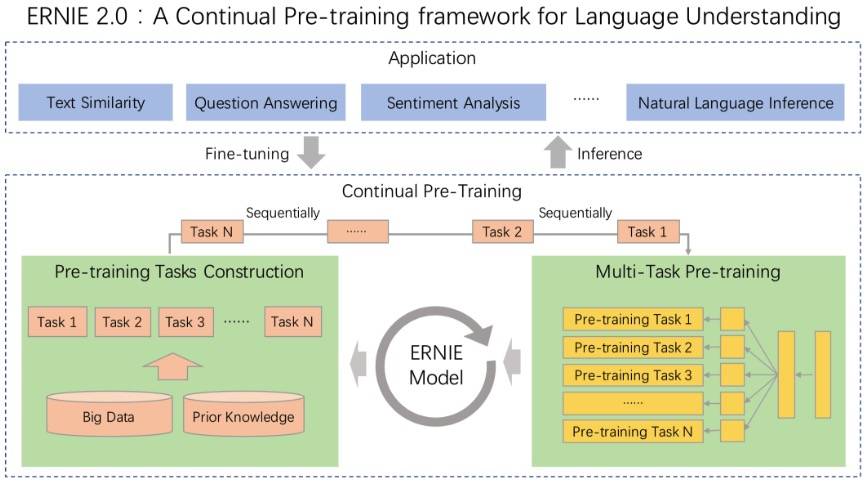
老习惯还是先理论再实践,所以看 paper 先,我们只看关键信息。
ChatBot 设计方案
最近公司有个客服机器人的需求,下午大概看了一下网上现有的一些方案,总感觉不是特别满意,而且整个 AI 圈子都透露出一点点的浮躁。其实对话机器人这个主题并不新颖,但对我来说,最早是在大学期间(2004-2008年)了,那时候的对话机器人都是基于模板的,印象很深刻有个网页版的机器人,名字叫 God,闲聊非常顺溜;再往后一点,记得在 2009 年看到的一篇文章,当时就特别想做一个,可惜不会写代码;然后就到了刚转行做技术的 2017 年,那时候有了 DeepLearning,也有了 RNN,于是就用对话语料自己训练了一个玩儿。
现在莫名其妙突然火起来我猜一方面是客服机器人确实解决了企业部分的需求;另一方面是这方面的技术更加成熟了。去看了一下发现虽然没有什么新东西(比如,意图理解是一个分类器,多轮对话是设计好的模板,甚至对话的生成也是基于模板),有点莫名其妙,可能还是得益于 NLP 基础技术不断取得的效果。还有一些借助知识图谱(又一个很早就提出最近突然火的东西)的客服机器人,看了几个项目,发现非常基础和简单粗暴,完全没有感觉到 AI 在哪里。感觉还不如三年前 memect 的 memect/kg-beijing: 北京知识图谱学习小组。
冷静点看,现在的人工智能其实过于依赖数据,这究竟是聪明还是愚蠢只能见仁见智了。想想先哲们六七十年代从事 AI 所做的工作,直感觉汗颜不已,都是利益造就啊。有时候不得不感慨,人一旦对某一事物开始投入就会逐渐变得盲目,随着投入的不断增加会越来越盲目。经济学把这叫沉没成本,心理学上也有类似的研究,大家都把精力和金钱砸进来了,谁会说不好呢?明知道不好也要说好,还要继续增加投入,当然有些人纯粹是起哄或者薅羊毛。说的有点偏,倒不是说对 AI 没有信心,而是觉得被过于神化(人们总是喜欢一拥而上),在没有解决意识问题之前,它看起来再怎么 “聪明” 也就是个工具而已,对于一个工具自然应该以对待 “工具” 的方式去看。
言归正传,对话机器人既然有这么悠久的历史,我们当然不应该完全忽视先哲们的研究,所以我决定结合历史 AI 技术和现在新的 AI 技术,以自己的理解去做一个工业级别、开源的客服机器人系统。这篇文章要谈的就是机器人整个架构的设计以及背后的思想和逻辑。
Median of Two Sorted Arrays (LeetCode 4)
There are two sorted arrays nums1 and nums2 of size m and n respectively.
Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
You may assume nums1 and nums2 cannot be both empty.